部分常見ORACLE面試題以及SQL注意事項
一、表的創建:
一個通過單列外鍵聯系起父表和子表的簡單例子如下:
CREATE TABLE parent(id INT NOT NULL,
PRIMARY KEY (id)
)
CREATE TABLE child(id INT, parent_id INT,
INDEX par_ind (parent_id),
FOREIGN KEY (parent_id) REFERENCES parent(id)
ON DELETE CASCADE
)
建表時注意不要用關鍵字當表名或字段名,如insert,use等。
CREATE TABLE parent(id INT NOT NULL,
PRIMARY KEY (id)
) TYPE=INNODB;
InnoDB Tables 概述
InnoDB給MySQL提供了具有事務(commit)、回滾(rollback)和崩潰修復能力(crash recovery capabilities)的事務安全(transaction-safe (ACID compliant))型表。
InnoDB 提供了行鎖(locking on row level),提供與 Oracle 類型一致的不加鎖讀取(non-locking read in SELECTs)。這些特性均提高了多用戶並發操作的性能表現。在InnoDB表中不需要擴大鎖定(lock escalation),
因為 InnoDB 的列鎖定(row level locks)適宜非常小的空間。
InnoDB 是 MySQL 上第一個提供外鍵約束(FOREIGN KEY constraints)的表引擎。
InnoDB 的設計目標是處理大容量數據庫系統,它的CPU利用率是其它基於磁盤的關系數據庫引擎所不能比的。
從一個表中查詢出數據插入到另一個表中的方法:
select * into destTbl from srcTbl ;
insert into destTbl(fld1, fld2) select fld1, 5 from srcTbl ;以上兩句都是將 srcTbl 的數據插入到 destTbl,但兩句又有區別的。
第一句(select into from)要求目標表(destTbl)不存在,因為在插入時會自動創建。
第二句(insert into select from)要求目標表(destTbl)存在,由於目標表已經存在,所以我們除了插入源表(srcTbl)的字段外,還可以插入常量,如例中的:5。
如果只想要結構而不要數據。
create table s_emp_42 as select * from s_emp where 1=2;//永假式
SQL查詢練習題
1.
表1:book表,字段有id(主鍵),name (書名);
表2:bookEnrol表(圖書借出歸還登記),字段有id,bookId(外鍵),dependDate(變更時間),state(1.借出 2.歸還)。
id name
1 English
2 Math
3 JAVA
id bookId dependDate state
1 1 2009-01-02 1
2 1 2009-01-12 2
3 2 2009-01-14 1
4 1 2009-01-17 1
5 2 2009-02-14 2
6 2 2009-02-15 1
7 3 2009-02-18 1
8 3 2009-02-19 2
要求查詢結果應為:(被借出的書和被借出的日期)
Id Name dependDate
1 English 2009-01-17
2 Math 2009-02-15
Select e.bookId,b.name,e.dependDate from book b,bookEnrol e where
第二個表是用來登記的,不管你是借還是還,都要添加一條記錄。
請寫一個SQL語句,獲取到現在狀態為已借出的所有圖書的相關信息。
參考語句:
select book.id,book.name,max(dependDate)
from book inner join bookEnrol on book.id=bookEnrol.bookid AND booker.state=1
group by book.id ;
2
第(1)題練習使用group by /having 子句。類似的筆試題還有:
表一:各種產品年銷售量統計表 sale
年 產品 銷量
2005 a 700
2005 b 550
2005 c 600
2006 a 340
2006 b 500
2007 a 220
2007 b 350
要求得到的結果應為:
年 產品 銷量
2005 a 700
2006 b 500
2007 b 350
即:每年銷量最多的產品的相關信息。
參考答案:
Select * from sale a where not exists(select * from sale where 年=a.年 and 銷量>a.銷量);
--or:
select * from sale a inner join (select 年,max(銷量) as 銷量from sale group by 年) b
on a.年=b.年 and a.銷量=b.銷量
3.查詢語句排名問題:
名次 姓名 月積分(char) 總積分(char)
1 WhatIsJava 1 99
2 水王 76 981
3 新浪網 65 96
4 牛人 22 9
5 中國隊 64 89
6 北林信息 66 66
7 加太陽 53 66
8 中成藥 11 33
9 西洋參 25 26
10 大拿 33 23
如果用總積分做降序排序..因為總積分是字符型,所以排出來是這樣子(9,8,7,6,5...),要求按照總積分的數字大小排序。
select * from tablename order by cast(總積分 as int) desc
表tb
uid mark
1 7
1 6
2 3
2 2
2 5
3 4
3 3
4 8
4 1
4 3
想查出uid=4的名次:
uid mc
4 3
select uid, sum(mark) as total from tab_name group by uid order by total desc;
4
表A字段如下
month name income
月份 人員 收入
1 a 1000
2 a 2000
3 a 3000
要求用一個SQL語句(注意是一個)的處所有人(不區分人員)每個月及上月和下月的總收入
要求列表輸出為
月份 當月收入 上月收入 下月收入
2 2000 1000 3000
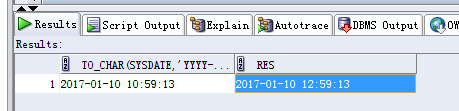
Select (Select Month From Table Where Month = To_Char(Sysdate, 'mm')) 月份,
(Select Sum(Income) From Table Where Month = To_Char(Sysdate, 'mm')) 當月收入,
(Select Sum(Income) From Table Where To_Number(Month) = To_Number(Extract(Month From Sysdate)) - 1) 上月收入,
(Select Sum(Income) From Table Where To_Number(Month) = To_Number(Extract(Month From Sysdate)) + 1) 下月收入
From Dual
5.刪除重復記錄
方法原理:
1、Oracle中,每一條記錄都有一個rowid,rowid在整個數據庫中是唯一的,
rowid確定了每條記錄是在ORACLE中的哪一個數據文件、塊、行上。
2、在重復的記錄中,可能所有列的內容都相同,但rowid不會相同,所以只要確定出重復記錄中
那些具有最大rowid的就可以了,其余全部刪除。
實現方法:
SQL> create table a (
2 bm char(4), --編碼
3 mc varchar2(20) --名稱
4 )
5 /
SQL> select rowid,bm,mc from a;
ROWID BM MC
------------------ ---- -------
000000D5.0000.0002 1111 1111
000000D5.0001.0002 1112 1111
000000D5.0002.0002 1113 1111
000000D5.0003.0002 1114 1111
000000D5.0004.0002 1111 1111
000000D5.0005.0002 1112 1111
000000D5.0006.0002 1113 1111
000000D5.0007.0002 1114 1111
查詢到8記錄.
查出重復記錄
SQL> select rowid,bm,mc from a where a.rowid!=(select max(rowid) from a b where a.bm=b.bm and a.mc=b.mc);
ROWID BM MC
------------------ ---- --------------------
000000D5.0000.0002 1111 1111
000000D5.0001.0002 1112 1111
000000D5.0002.0002 1113 1111
000000D5.0003.0002 1114 1111
刪除重復記錄
SQL> delete from a a where a.rowid!=(select max(rowid) from a b where a.bm=b.bm and a.mc=b.mc);
刪除4個記錄.
SQL> select rowid,bm,mc from a;
ROWID BM MC
------------------ ---- --------------------
000000D5.0004.0002 1111 1111
000000D5.0005.0002 1112 1111
000000D5.0006.0002 1113 1111
000000D5.0007.0002 1114 1111
其他組合函數
Group by 子句
Distinct 關鍵字
偽列ROWNUM,用於為子查詢返回的每個行分配序列值注意:組函數可以處理一組數據,返回一個值。組函數會忽略空值。where 後只能跟單行函數,不能有組函數。
使用TOP-N分析法
TOP-N分析法基於條件顯示表中最上面N條記錄或最下面N條記錄
TOP-N查詢包含以下內容:
1,一個用於排序數據的內聯視圖
2,使用ORDER BY子句或DESC參數的子查詢
3,一個外層查詢。由它決定最終記錄中行的數目。這包括ROWNUM偽列和用於比較運算符的WHERE子句
//語法:
SELECT ROWNUM,column_list
FROM (SELECT column_list FROM table_name ORDER BY Top-n-column_name)
WHERE ROWNUM <= N
例1:查詢Employee表的頂部10條記錄
//方法1:單表時可以用
select cEmployeeCode,vFirstName,vLastName from employee where rownum <= 10
//方法2:較復雜的查詢,建議使用這種
select * from (select rownum as num,cEmployeeCode,vFirstName,vLastName from employee)
where num <= 10
例2: 查詢Employee表的 第1 到 第10條 記錄,可以用於分頁顯示
//注意:因為這裡子查詢的rownum需要被外層查詢所使用,因此要使用別名,否則將被認為是兩個不同的rownum
select * from (select rownum as num,Employee.* from Employee) where num between 10 and 20
select * from (select rownum as num,Employee.* from Employee) where num between 1 and 10
SQL注入 1=1永遠成立,相當於查詢所有記錄
select * from person_zdk where 1=1 or name like '%a%' and age=13;
DECODE函數
是ORACLE PL/SQL是功能強大的函數之一,目前還只有ORACLE公司的SQL提供了此函數,其他數據庫廠商的SQL實現還沒有此功能。
decode(條件,值1,翻譯值1,值2,翻譯值2,...值n,翻譯值n,缺省值)
該函數的含義如下:
IF 條件=值1 THEN
RETURN(翻譯值1)
ELSIF 條件=值2 THEN
RETURN(翻譯值2)
......
ELSIF 條件=值n THEN
RETURN(翻譯值n)
ELSE
RETURN(缺省值)
END IF
假設我們想給智星職員加工資,其標准是:工資在8000元以下的將加20%;工資在8000元以上的加15%,用DECODE函數,那麼我們就可以把這些流控制語句省略,通過SQL語句就可以直接完成。如下:select decode(sign(salary - 8000),1,salary*1.15,-1,salary*1.2,salary from employee.
SQL中的單記錄函數
1.CONCAT
連接兩個字符串;
SQL> select concat('010-','88888888')||'轉23' 高乾競電話 from dual;高乾競電話
----------------
010-88888888轉23
2.LTRIM和RTRIM
LTRIM 刪除左邊出現的字符串
RTRIM 刪除右邊出現的字符串
SQL> select ltrim(rtrim(' gao qian jing ',' '),' ') from dual;
LTRIM(RTRIM('
-------------
gao qian jing
3..SUBSTR(string,start,count)
取子字符串,從start開始,取count個
SQL> select substr('13088888888',3,8) from dual;
SUBSTR('
--------
08888888
4日期函數
如:LAST_DAY 返回本月日期的最後一天
具體參見oracle筆記.
其他主要函數:.TRUNC 按照指定的精度截取一個數;SQRT 返回數字n的根;POWER(n1,n2)返回n1的n2次方根;MOD(n1,n2) 返回一個n1除以n2的余數;FLOOR 對給定的數字取整數;REPLACE('string','s1','s2') string 希望被替換的字符或變量 s1 被替換的字符串 s2 要替換的字符串;LOWER 返回字符串,並將所有的字符小寫;UPPER返回字符串,並將所有的字符大寫;LENGTH
返回字符串的長度。
ORALCE常識 及 SQL 基本語法
1,ORACLE安裝完成後的初始口令?
internal/oracle
sys/change_on_install
system/manager
scott/tiger scott是Oracle的核心開發人員之一,tiger是他家的一只貓的名字
sysman/oem_temp
例:conn scott/tiger@jspdev;
conn system/manager@jspdev as sysdba;
2,IBM的Codd (Edgar Frank Codd)博士提出《大型共享數據庫數據的關系模型》
3,ORACLE 9i 中的 i (internet)是因特網的意思
4,ORACLE的數據庫的物理結構:數據文件、日志文件、控制文件
5,ORACLE的數據庫的邏輯結構:表空間——表——段——區間——塊
表空間 類似於SQLSERVER中數據庫的概念
6,SYSDATE 返回當前系統日期(說明:當函數沒有參數時可以省略括號)
7,在SQL PLUS中 執行緩沖區中的SQL命令的方式:
SQL> run
SQL> r
SQL> /
8,在SQL PLUS中 修改當前會話的日期顯示格式
SQL> alter session set nls_date_format = 'YYYY-MM-DD'
9,使用臨時變量,提高輸入效率
SQL> insert into emp(empno,ename,sal) values(&employeeno,'&employeename',&employeesal);
10,從其他表中復制數據並寫入表
SQL> insert into managers(id,name,salary,hiredate)
SQL> select empno,ename,sal,hiredate
SQL> from emp
SQL> where job = 'MANAGER';
11,修改表中的記錄
SQL> update table set column = value [,column = value,……] [where condition];
12,刪除表中的記錄
SQL> delete [from] table [where condition];
13,數據庫事務,事務是數據庫一組邏輯操作的集合
一個事務可能是:
多個DML語句
單個DDL語句
單個DCL語句
14,事務控制使用 savepoint,rollback,commit 關鍵字
SQL> savepoint aaa;
SQL> rollback to aaa;
SQL> commit;
15,查詢表中的數據
select * from table_name;
select column_list from table_name;
16,Number and Date 可以用於算術運算
因為 Date 類型 其實存儲為 Number 類型
17,用運算表達式產生新列
SQL> select ename,sal,sal+3000 from emp;
SQL> select ename,sal,12*sal+100 from emp;
18,算術表達式中NULL值錯誤的處理
因為任何數與NULL運算無意義,所以為避免錯誤,需要用其他值替換NULL值
例如:
SQL> select ename "姓名",12*sal+comm "年薪" from emp where ename = 'KING';
姓名 薪水
---------- ----------
KING
因為comm(提成工資)列為NULL值,結果也出現了NULL值,所以需要用0來替換NULL
注意函數nvl的使用 NVL(原值,新值)
SQL> select ename "姓名",12*sal+NVL(comm,0) "年薪" from emp where ename = 'KING';
員工姓名 員工薪水
---------- ----------
KING 60000
——————————————
19,使用友好的列名,有下面三種形式
SQL> select ename as 姓名, sal 月薪, sal*12 "年薪" from emp
20,過濾重復行,使用關鍵字 distinct
SQL> select distinct * from emp;
21,SQL PLUS訪問ORACLE數據庫的原理
SQL*Plus —> Buffer —> Server —> Query Result
22,where 子句中 字符型 是區分大小寫的,最好都轉成大寫
因為在ORACLE庫中,字符會轉換成大寫來保存
23,比較運算符:等於"=",不等於有兩種"<>"或者"!="
24,復雜的比較運算符:
between …… and ……
in (……value list……)
like (% 代表匹配至多個任意字符,_ 代表單個任意字符)
null (與NULL進行比較時,需要使用 is null 或者 is not null)
25,邏輯運算符,按優先級從高到低排列
Not , And , Or
26,Order by 子句 中 ( asc 表示 升序,desc 表示降序)
27,ORACLE 函數,分為
單行函數:每條記錄返回一個結果值
多行函數:多條記錄返回一個結果值
28,字符函數——轉換函數
LOWER:轉為小寫
UPPER:轉為大寫
INITCAP:將每個單詞的首字母大寫,其他字母小寫
29,字符函數——操縱函數(注意:ORACLE以UNICODE存儲字符)
CONCAT:連接兩個字符串,與並置運算符“||”類似
SUBSTR:substr(string,position,length) 從string中的position開始取length個字符
LENGTH:返回字符串的長度
INSTR: instr(string,value) 返回 value 在 string 的起始位置
LPAD: lpad(string,number,value) 若string不夠number位,從左起用vlaue字符串填充(不支持中文)
30,四捨五入函數 round(數值,小數位)
SQL> SELECT ROUND(45.923,2),ROUND(45.923,0),ROUND(45.923,-1) FROM DUAL;
ROUND(45.923,2) ROUND(45.923,0) ROUND(45.923,-1)
--------------- --------------- ----------------
45.92 46 50
31,數值截取函數 trunct
SQL> SELECT TRUNC(45.923,2),TRUNC(45.923,0),TRUNC(45.923,-1) FROM DUAL;
TRUNC(45.923,2) TRUNC(45.923,0) TRUNC(45.923,-1)
--------------- --------------- ----------------
45.92 45 40
32,求模函數 MOD(a,b) 返回a被b整除後的余數
33,Oracle內部默認的日期格式: DD-MON-YY (24-9月 -06)
34,DUAL :啞元系統表,是名義表,只能范圍唯一值
35,Date類型的算術運算,以天為單位
例如:部門編號為10的員工分別工作了多少年
SQL> select ename,(sysdate-hiredate)/365 as years from emp where deptno = 10;
ENAME YEARS
---------- ----------
CLARK 25.3108341
KING 24.8697382
MILLER 24.6861766
36,日期函數
MONTHS_BETWEEN 返回兩個日期之間相差多少個月
ADD_MONTHS 在日期上加上月份數
NEXT_DAY 下一個日子 select next_day(sysdate,'星期一') from dual;
LAST_DAY 該月的最後一天
ROUND 四捨五入日期 round(sysdate,'year') 或者 round(sysdate,'month')
TRUNC 截取日期 trunc(sysdate,'year') 或者 trunc(sysdate,'month')
37,數據類型轉換 —— Oracle 可隱式轉換的情況有:
From To
varchar2 or char —— number (當字符串是數字字符時)
varchar2 or char —— date
number —— varchar2
date —— varchar2
38,數據類型轉換 —— Oracle 數據類型轉換函數
to_char
to_number
to_date
39,日期格式模型字符
YYYY 代表完整的年份
YEAR 年份
MM 兩位數的月份
MONTH 月份的完整名稱
DY 每星期中天的三個字符縮寫
DAY 表示星期日——星期六
另外還有 D,DD,DDD 等。。。
40,NVL(value,substitute)
value:是可能有null的列,substitute是缺省值
這個函數的作用就是當出現null值的時候,後缺省值替換null
41,Coalesce(exp_name1,exp_name2……exp_n)
42,Decode 函數: Decode(exp,testvalue1,resultvalue1,testvalue2,resultvalue2)
例如,根據國家名稱顯示相應的國家代碼:
1>創建國家表
create table countrys
(
vCountryName varchar2(50)
);
2>寫入幾行,分別為中國、日本、韓國
insert into countrys values ('&name');
3>用DECODE函數,進行匹配和顯示
select vCountryName as "國家名稱",
DECODE(vCountryName,'中國','086','日本','116') as "國家編號" from countrys;
國家名稱 國家編號
-------------------------------------------------- ---
中國 086
日本 116
韓國
結果,在DECODE中存在且成功匹配的值將會被顯示,否則顯示為NULL
SQL語句書可以提高執行效率的方法
1、操作符號: NOT IN操作符
此操作是強列推薦不使用的,因為它不能應用表的索引。推薦方案:用NOT EXISTS 或(外連接+判斷為空)方案代替 "IS NULL", "<>", "!=", "!>", "!<", "NOT", "NOT EXISTS", "NOT IN", "NOT LIKE", "LIKE '%500'",因為他們不走索引全是表掃描。NOT IN會多次掃描表,使用EXISTS、NOT EXISTS、IN、LEFT OUTER JOIN來替代,特別是左連接,而Exists比IN更快,最慢的是NOT操作。
2、注意union和union all的區別。union比union all多做了一步distinct操作。能用union all的情況下盡量不用union。
如: 兩個表A和B都有一個序號字段ID,要求兩個表中的ID字段最大的值:
select max(id) as max_id
from(
select id from 表A
union all
select id from 表B ) t
3、查詢時盡量不要返回不需要的行、列。另外在多表連接查詢時,盡量改成連接查詢,少用子查詢。
4、盡量少用視圖,它的效率低。對視圖操作比直接對表操作慢,可以用存儲過程來代替它。特別的是不要用視圖嵌套,嵌套視圖增加了尋找原始資料的難度。
我們看視圖的本質:它是存放在服務器上的被優化好了的已經產生了查詢規劃的SQL。對單個表檢索數據時,不要使用指向多個表的視圖,
直接從表檢索或者僅僅包含這個表的視圖上讀,否則增加了不必要的開銷,查詢受到干擾.為了加快視圖的查詢,MsSQL增加了視圖索引的功能。
5、創建合理的索引,對於插入或者修改比較頻繁的表,盡量慎用索引。因為如果表中存在索引,插入和修改時也會引起全表掃描。
索引一般使用於where後經常用作條件的字段上。
6、在表中定義字段或者存儲過程、函數中定義參數時,將參數的大小設置為合適即可,勿設置太大。這樣開銷很大。
7、Between在某些時候比IN速度更快,Between能夠更快地根據索引找到范圍。用查詢優化器可見到差別。
select * from chineseresume where title in ('男','女')
Select * from chineseresume where between '男' and '女'是一樣的。由於in會在比較多次,所以有時會慢些。
8、在必要是對全局或者局部臨時表創建索引,有時能夠提高速度,但不是一定會這樣,因為索引也耗費大量的資源。他的創建同是實際表一樣。
9、WHERE後面的條件順序影響
WHERE子句後面的條件順序對大數據量表的查詢會產生直接的影響,如
Select * from zl_yhjbqk where dy_dj = '1KV以下' and xh_bz=1
Select * from zl_yhjbqk where xh_bz=1 and dy_dj = '1KV以下'
以上兩個SQL中dy_dj(電壓等級)及xh_bz(銷戶標志)兩個字段都沒進行索引,所以執行的時候都是全表掃描,如果dy_dj = '1KV以下'條件在記錄集內比率為99%,而xh_bz=1的比率只為0.5%,在進行第一條SQL的時候99%條記錄都進行dy_dj及xh_bz的 比較,而在進行第二條SQL的時候0.5%條記錄都進行dy_dj及xh_bz的比較,以此可以得出第二條SQL的CPU占用率明顯比第一條低。所以盡量 將范圍小的條件放在前面。。
10、用OR的字句可以分解成多個查詢,並且通過UNION 連接多個查詢。他們的速度只同是否使用索引有關,如果查詢需要用到聯合索引,用 UNION all執行的效率更高.多個OR的字句沒有用到索引,改寫成UNION的形式再試圖與索引匹配。一個關鍵的問題是否用到索引。
11、沒有必要時不要用DISTINCT和ORDER BY,這些動作可以改在客戶端執行。它們增加了額外的開銷。這同UNION和UNION ALL一樣的道理。
12、使用in時,在IN後面值的列表中,將出現最頻繁的值放在最前面,出現得最少的放在最後面,這樣可以減少判斷的次數
13、當用SELECT INTO時,它會鎖住系統表(sysobjects,sysindexes等等),阻塞其他的連接的存取。創建臨時表時用顯示聲明語句,在另一個連接中 SELECT * from sysobjects可以看到 SELECT INTO 會鎖住系統表, Create table 也會鎖系統表(不管是臨時表還是系統表)。所以千萬不要在事物內使用它!!!這樣的話如果是經常要用的臨時表請使用實表,或者臨時表變量。
14、一般在GROUP BY和HAVING字句之前就能剔除多余的行,所以盡量不要用它們來做剔除行的工作。他們的執行順序應該如下最優:select 的Where字句選擇所有合適的行,Group By用來分組個統計行,Having字句用來剔除多余的分組。這樣Group By和Having的開銷小,查詢快.對於大的數據行進行分組和Having十分消耗資源。如果Group BY的目的不包括計算,只是分組,那麼用Distinct更快
15、一次更新多條記錄比分多次更新每次一條快,就是說批處理好
16、慎用臨時表,臨時表存儲於tempdb庫中,操作臨時表時,會引起跨庫操作。盡量用結果集和表變量來代替它。
17、盡量將數據的處理工作放在服務器上,減少網絡的開銷,如使用存儲過程。存儲過程是編譯好、優化過,並且被組織到一個執行規劃裡、且存儲在數據庫中的 SQL語句,是控制流語言的集合,速度當然快。
18、不要在一段SQL或者存儲過程中多次使用相同的函數或相同的查詢語句,這樣比較浪費資源,建議將結果放在變量裡再調用。這樣更快。
19、按照一定的次序來訪問你的表。如果你先鎖住表A,再鎖住表B,那麼在所有的存儲過程中都要按照這個順序來鎖定它們。如果你(不經意的)某個存儲過程中先鎖定表B,再鎖定表A,這可能就會導致一個死鎖。
oracle Certification Program (OCP認證)的題目
(1) A 表中有100條記錄.
Select * FROM A Where A.COLUMN1 = A.COLUMN1
這個語句返回幾條記錄? (簡單吧,似乎1秒鐘就有答案了:)
(2) Create SEQUENCE PEAK_NO
Select PEAK_NO.NEXTVAL FROM DUAL --> 假設返回1
10秒中後,再次做
Select PEAK_NO.NEXTVAL FROM DUAL --> 返回多少?
(3) SQL> connect sys as sysdba
Connected.
SQL> insert into dual values ( 'Y');
1 row created.
SQL> commit;
Commit complete.
SQL> select count(*) from dual;
COUNT(*)
----------
2
SQL> delete from dual;
commit;
-->DUAL裡還 剩幾條記錄?
JUST TRY IT
一些高難度的SQL面試題
以 下的null代表真的null,寫在這裡只是為了讓大家看清楚
根據如下表的查詢結果,那麼以下語句的結果是(知識點:not in/not exists+null)
SQL> select * from usertable;
USERID USERNAME
----------- ----------------
1 user1
2 null
3 user3
4 null
5 user5
6 user6
SQL> select * from usergrade;
USERID USERNAME GRADE
---------- ---------------- ----------
1 user1 90
2 null 80
7 user7 80
8 user8 90
執行語句:
select count(*) from usergrade where username not in (select username from usertable);
select count(*) from usergrade g where not exists
(select null from usertable t where t.userid=g.userid and t.username=g.username);
結 果為:語句1( 0 ) 語句2 ( 3 )
A: 0 B:1 C:2 D:3 E:NULL
2
在以下的表的顯示結果中,以下語句的執行結果是(知識 點:in/exists+rownum)
SQL> select * from usertable;
USERID USERNAME
----------- ----------------
1 user1
2 user2
3 user3
4 user4
5 user5
SQL> select * from usergrade;
USERNAME GRADE
---------------- ----------
user9 90
user8 80
user7 80
user2 90
user1 100
user1 80
執行語句
Select count(*) from usertable t1 where username in
(select username from usergrade t2 where rownum <=1);
Select count(*) from usertable t1 where exists
(select 'x' from usergrade t2 where t1.username=t2.username and rownum <=1);
以上語句的執行結果 是:( ) ( )
A: 0 B: 1 C: 2 D: 3
根 據以下的在不同會話與時間點的操作,判斷結果是多少,其中時間T1原始表記錄為;
select * from emp;
EMPNO DEPTNO SALARY
----- ------ ------
100 1 55
101 1 50
select * from dept;
DEPTNO SUM_OF_SALARY
------ -------------
1 105
2
可以看到,現在因為還沒有部門2的員工,所以總薪水為null,現在,
有兩個 不同的用戶(會話)在不同的時間點(按照特定的時間順序)執行了一系列的操作,那麼在其中或最後的結果為:
time session 1 session2
----------- ------------------------------- -----------------------------------
T1 insert into emp
values(102,2,60)
T2 update emp set deptno =2
where empno=100
T3 update dept set sum_of_salary =
(select sum(salary) from emp
where emp.deptno=dept.deptno)
where dept.deptno in(1,2);
T4 update dept set sum_of_salary =
(select sum(salary) from emp
where emp.deptno=dept.deptno)
where dept.deptno in(1,2);
T5 commit;
T6 select sum(salary) from emp group by deptno;
問題一:這裡會話2的查詢結果為:
T7 commit;
=======到這裡為此,所有事務都已完成,所以以下查詢與會話已沒有關系========
T8 select sum(salary) from emp group by deptno;
問題二:這裡查詢結果為
T9 select * from dept;
問題三:這裡查詢的結果為
問題一的結果( ) 問題 二的結果是( ) 問題三的結果是( )
A: B:
---------------- ----------------
1 50 1 50
2 60 2 55
C: D:
---------------- ----------------
1 50 1 115
2 115 2 50
E: F:
---------------- ----------------
1 105 1 110
2 60 2 55
有表一的查詢結果如下,該表為學生成績表(知識點:關聯更新)
select id,grade from student_grade
ID GRADE
-------- -----------
1 50
2 40
3 70
4 80
5 30
6 90
表二為補考成績表
select id,grade from student_makeup
ID GRADE
-------- -----------
1 60
2 80
5 60
現在有一個dba通過如下語句把補考成績更新到成績表中,並提交:
update student_grade s set s.grade =
(select t.grade from student_makeup t
where s.id=t.id);
commit;
請問之後查詢:
select GRADE from student_grade where id = 3;結果為:
A: 0 B: 70 C: null D: 以上都不對
根據以下的在不同會話與時間點的操作,判斷結果是多少,
其中時間T1
session1 session2
-------------------------------------- ----------------------------------------
T1 select count(*) from t;
--顯示結果(1000)條
T2 delete from t where rownum <=100;
T3 begin
delete from t where rownum <=100;
commit;
end;
/
T4 truncate table t;
T5 select count(*) from t;
-- 這裡顯示的結果是多少
A: 1000 B: 900 C: 800 D: 0
1、表:table1(FId,Fclass,Fscore),用最高效最簡單的SQL列出各班成績最高的列表,顯示班級,成績兩個字段。
select fclass,max(fscore) from table1 group by fclass,fid
2、有一個表table1有兩個字段FID,Fno,字都非空,寫一個SQL語句列出該表中一個FID對應多個不同的Fno的紀錄。
類如:
101a1001
101a1001
102a1002
102a1003
103a1004
104a1005
104a1006
105a1007
105a1007
105a1007
結果:
102a1002
102a1003
104a1005
104a1006
select t2.* from table1 t1, table1 t2 where t1.fid = t2.fid and t1.fno <> t2.fno;
3、有員工表empinfo
(
Fempno varchar2(10) not null pk,
Fempname varchar2(20) not null,
Fage number not null,
Fsalary number not null
);
假如數據量很大約1000萬條;寫一個你認為最高效的SQL,用一個SQL計算以下四種人:
fsalary>9999 and fage > 35
fsalary>9999 and fage < 35
fsalary <9999 and fage > 35
fsalary <9999 and fage < 35
每種員工的數量;
select sum(case when fsalary > 9999 and fage > 35
then 1
else 0end) as "fsalary>9999_fage>35",
sum(case when fsalary > 9999 and fage < 35
then 1
else 0
end) as "fsalary>9999_fage<35",
sum(case when fsalary < 9999 and fage > 35
then 1
else 0
end) as "fsalary<9999_fage>35",
sum(case when fsalary < 9999 and fage < 35
then 1
else 0
end) as "fsalary<9999_fage<35"
from empinfo;
4、表A字段如下
month person income
月份 人員 收入
要求用一個SQL語句(注意是一個)的處所有人(不區分人員)每個月及上月和下月的總收入
要求列表輸出為
月份 當月收入 上月收入 下月收入
MONTHS PERSON INCOME
---------- ---------- ----------200807 mantisXF 5000200806 mantisXF2 3500200806 mantisXF3 3000200805 mantisXF1 2000200805 mantisXF6 2200200804 mantisXF7 1800200803 8mantisXF 4000200802 9mantisXF 4200200802 10mantisXF 3300200801 11mantisXF 4600200809 11mantisXF 6800
11 rows selected
select months, max(incomes), max(prev_months), max(next_months)
from (select months,
incomes,
decode(lag(months) over(order by months),
to_char(add_months(to_date(months, 'yyyymm'), -1), 'yyyymm'), lag(incomes) over(order by months), 0) as prev_months, decode(lead(months) over(order by months), to_char(add_months(to_date(months, 'yyyymm'), 1), 'yyyymm'), lead(incomes) over(order by months), 0) as next_months from (select months, sum(income) as incomes from a group by months) aa) aaagroup by months;
MONTHS MAX(INCOMES) MAX(PREV_MONTHS) MAX(NEXT_MONTHS)---------- ------------ ---------------- ----------------200801 4600 0 7500200802 7500 4600 4000200803 4000 7500 1800200804 1800 4000 4200200805 4200 1800 6500200806 6500 4200 5000200807 5000 6500 0200809 6800 0 0
5,表B
C1 c2
2005-01-01 1
2005-01-01 3
2005-01-02 5
要求的處數據
2005-01-01 4
2005-01-02 5
合計 9
試用一個Sql語句完成。
select nvl(to_char(t02,'yyyy-mm-dd'),'合計'),sum(t01)from test
group by rollup(t02)
6,數據庫1,2,3 范式的概念與理解。
7,簡述oracle行觸發器的變化表限制表的概念和使用限制,行觸發器裡面對這兩個表有什麼限制。
8、oracle臨時表有幾種。
臨時表和普通表的主要區別有哪些,使用臨時表的主要原因是什麼?
9,怎麼實現:使一個會話裡面執行的多個過程函數或觸發器裡面都可以訪問的全局變量的效果,並且要實現會話間隔離?
10,aa,bb表都有20個字段,且記錄數量都很大,aa,bb表的X字段(非空)上有索引,
請用SQL列出aa表裡面存在的X在bb表不存在的X的值,請寫出認為最快的語句,並解譯原因。
11,簡述SGA主要組成結構和用途?
12什麼是分區表?簡述范圍分區和列表分區的區別,分區表的主要優勢有哪些?
13,背景:某數據運行在archivelog,且用rman作過全備份和數據庫的冷備份,
且所有的歸檔日志都有,現控制文件全部損壞,其他文件全部完好,請問該怎麼恢復該數據庫,說一兩種方法。
14,用rman寫一個備份語句:備份表空間TSB,level 為2的增量備份。
15,有個表a(x number(20),y number(20))用最快速高效的SQL向該表插入從1開始的連續的1000萬記錄。
1、表:table1(FId,Fclass,Fscore),用最高效最簡單的SQL列出各班成績最高的列表,顯示班級,成績兩個字段。
2、有一個表table1有兩個字段FID,Fno,字都非空,寫一個SQL語句列出該表中一個FID對應多個不同的Fno的紀錄。
類如:
101 a1001
101 a1001
102 a1002
102 a1003
103 a1004
104 a1005
104 a1006
105 a1007
105 a1007
105 a1007
結果:
102 a1002
102 a1003
104 a1005
104 a1006
3、有員工表empinfo
(
Fempno varchar2(10) not null pk,
Fempname varchar2(20) not null,
Fage number not null,
Fsalary number not null
);
假如數據量很大約1000萬條;寫一個你認為最高效的SQL,用一個SQL計算以下四種人:
fsalary>9999 and fage > 35
fsalary>9999 and fage < 35
fsalary<9999 and fage > 35
fsalary<9999 and fage < 35
每種員工的數量;
4、表A字段如下
month person income
月份 人員 收入
要求用一個SQL語句(注意是一個)的處所有人(不區分人員)每個月及上月和下月的總收入
要求列表輸出為
月份 當月收入 上月收入 下月收入
5,表B
C1 c2
2005-01-01 1
2005-01-01 3
2005-01-02 5
要求的處數據
2005-01-01 4
2005-01-02 5
合計 9
試用一個Sql語句完成。
6,數據庫1,2,3 范式的概念與理解。
7,簡述oracle行觸發器的變化表限制表的概念和使用限制,行觸發器裡面對這兩個表有什麼限制。
8、oracle臨時表有幾種。
臨時表和普通表的主要區別有哪些,使用臨時表的主要原因是什麼?
9,怎麼實現:使一個會話裡面執行的多個過程函數或觸發器裡面都可以訪問的全局變量的效果,並且要實現會話間隔離?
10,aa,bb表都有20個字段,且記錄數量都很大,aa,bb表的X字段(非空)上有索引,
請用SQL列出aa表裡面存在的X在bb表不存在的X的值,請寫出認為最快的語句,並解譯原因。
11,簡述SGA主要組成結構和用途?
12什麼是分區表?簡述范圍分區和列表分區的區別,分區表的主要優勢有哪些?
13,背景:某數據運行在archivelog,且用rman作過全備份和數據庫的冷備份,
且所有的歸檔日志都有,現控制文件全部損壞,其他文件全部完好,請問該怎麼恢復該數據庫,說一兩種方法。
14,用rman寫一個備份語句:備份表空間TSB,level 為2的增量備份。
15,有個表a(x number(20),y number(20))用最快速高效的SQL向該表插入從1開始的連續的1000萬記錄。
答案:
1、select Fclass,max(Fscore) from table1 group by Fclass
2、select * from table1 where FID in (select FID from table1 group by FID having (count(Distinct Fno))>=2)
3、select sum(case when fsalary>9999 and fage>35 then 1 else 0 end),
sum(case when fsalary>9999 and fage<35 then 1 else 0 end),
sum(case when fsalary<9999 and fage>35 then 1 else 0 end),
sum(case when fsalary<9999 and fage<35 then 1 else 0 end) from empinfo
4、
Select (Select Month From Table Where Month = To_Char(Sysdate, 'mm')) 月份,
(Select Sum(Income) From Table Where Month = To_Char(Sysdate, 'mm')) 當月收入,
(Select Sum(Income) From Table Where To_Number(Month) = To_Number(Extract(Month From Sysdate)) - 1) 上月收入,
(Select Sum(Income) From Table Where To_Number(Month) = To_Number(Extract(Month From Sysdate)) + 1) 下月收入
From Dual
5、select nvl(c1,'合計'),sum(c2) from B group by rollup(c1)
6.
關系數據庫設計之時是要遵守一定的規則的。尤其是數據庫設計范式
簡單介紹1NF(第一范式),2NF(第二范式),3NF(第三范式),
第一范式(1NF):在關系模式R中的每一個具體關系r中,如果每個屬性值 都是不可再分的最小數據單位,則稱R是第一范式的關系。
例:如職工號,姓名,電話號碼組成一個表(一個人可能有一個辦公室電話 和一個家裡電話號碼) 規范成為1NF有三種方法:
一是重復存儲職工號和姓名。這樣,關鍵字只能是電話號碼。
二是職工號為關鍵字,電話號碼分為單位電話和住宅電話兩個屬性
三是職工號為關鍵字,但強制每條記錄只能有一個電話號碼。
以上三個方法,第一種方法最不可取,按實際情況選取後兩種情況。
第二范式(2NF):如果關系模式R(U,F)中的所有非主屬性都完全依賴於任意一個候選關鍵字,則稱關系R 是屬於第二范式的。
例:選課關系 SCI(SNO,CNO,GRADE,CREDIT)其中SNO為學號, CNO為課程號,GRADEGE 為成績,CREDIT 為學分。 由以上
條件,關鍵字為組合關鍵字(SNO,CNO)
在應用中使用以上關系模式有以下問題:
a.數據冗余,假設同一門課由40個學生選修,學分就 重復40次。
b.更新異常,若調整了某課程的學分,相應的元組CREDIT值都要更新,有可能會出現同一門課學分不同。
c.插入異常,如計劃開新課,由於沒人選修,沒有學號關鍵字,只能等有人選修才能把課程和學分存入。
d.刪除異常,若學生已經結業,從當前數據庫刪除選修記錄。某些門課程新生尚未選修,則此門課程及學分記錄無法保存。
原因:非關鍵字屬性CREDIT僅函數依賴於CNO,也就是CREDIT部分依賴組合關鍵字(SNO,CNO)而不是完全依賴。
解決方法:分成兩個關系模式 SC1(SNO,CNO,GRADE),C2(CNO,CREDIT)。新關系包括兩個關系模式,它們之間通過SCN中
的外關鍵字CNO相聯系,需要時再進行自然聯接,恢復了原來的關系
第三范式(3NF):如果關系模式R(U,F)中的所有非主屬性對任何候選關鍵字都不存在傳遞信賴,則稱關系R是屬於第三范式的。
例:如S1(SNO,SNAME,DNO,DNAME,LOCATION) 各屬性分別代表學號,
姓名,所在系,系名稱,系地址。
關鍵字SNO決定各個屬性。由於是單個關鍵字,沒有部分依賴的問題,肯定是2NF。但這關系肯定有大量的冗余,有關學生所在的幾個
屬性DNO,DNAME,LOCATION將重復存儲,插入,刪除和修改時也將產生類似以上例的情況。
原因:關系中存在傳遞依賴造成的。即SNO -> DNO。 而DNO -> SNO卻不存在,DNO -> LOCATION, 因此關鍵遼 SNO 對 LOCATIO
N 函數決定是通過傳遞依賴 SNO -> LOCATION 實現的。也就是說,SNO不直接決定非主屬性LOCATION。
解決目地:每個關系模式中不能留有傳遞依賴。
解決方法:分為兩個關系 S(SNO,SNAME,DNO),D(DNO,DNAME,LOCATION)
注意:關系S中不能沒有外關鍵字DNO。否則兩個關系之間失去聯系。
7.
變化表mutating table
被DML語句正在修改的表
需要作為DELETE CASCADE參考完整性限制的結果進行更新的表也是變化的
限制:對於Session本身,不能讀取正在變化的表
限制表constraining table
需要對參考完整性限制執行讀操作的表
限制:如果限制列正在被改變,那麼讀取或修改會觸發錯誤,但是修改其它列是允許的。
8.
在Oracle中,可以創建以下兩種臨時表:
a。會話特有的臨時表
CREATE GLOBAL TEMPORARY ( )
ON COMMIT PRESERVE ROWS;
b。事務特有的臨時表
CREATE GLOBAL TEMPORARY ( )
ON COMMIT DELETE ROWS;
CREATE GLOBAL TEMPORARY TABLE MyTempTable
所建的臨時表雖然是存在的,但是你試一下insert 一條記錄然後用別的連接登上去select,記錄是空的,明白了吧。
下面兩句話再貼一下:
--ON COMMIT DELETE ROWS 說明臨時表是事務指定,每次提交後ORACLE將截斷表(刪除全部行)
--ON COMMIT PRESERVE ROWS 說明臨時表是會話指定,當中斷會話時ORACLE將截斷表。
9.--個人理解就是建立一個包,將常量或所謂的全局變量用包中的函數返回出來就可以了,摘抄一短網上的解決方法
Oracle數據庫程序包中的變量,在本程序包中可以直接引用,但是在程序包之外,則不可以直接引用。對程序包變量的存取,可以為每個變量配套相應的存儲 過程<用於存儲數據>和函數<用於讀取數據>來實現。
3.2 實例
--定義程序包
create or replace package PKG_System_Constant is
C_SystemTitle nVarChar2(100):='測試全局程序變量'; --定義常數
--獲取常數<系統標題>
Function FN_GetSystemTitle
Return nVarChar2;
G_CurrentDate Date:=SysDate; --定義全局變量
--獲取全局變量<當前日期>
Function FN_GetCurrentDate
Return Date;
--設置全局變量<當前日期>
Procedure SP_SetCurrentDate
(P_CurrentDate In Date);
End PKG_System_Constant;
/
create or replace package body PKG_System_Constant is
--獲取常數<系統標題>
Function FN_GetSystemTitle
Return nVarChar2
Is
Begin
Return C_SystemTitle;
End FN_GetSystemTitle;
--獲取全局變量<當前日期>
Function FN_GetCurrentDate
Return Date
Is
Begin
Return G_CurrentDate;
End FN_GetCurrentDate;
--設置全局變量<當前日期>
Procedure SP_SetCurrentDate
(P_CurrentDate In Date)
Is
Begin
G_CurrentDate:=P_CurrentDate;
End SP_SetCurrentDate;
End PKG_System_Constant;
/
3.3 測試
--測試讀取常數
Select PKG_System_Constant.FN_GetSystemTitle From Dual;
--測試設置全局變量
Declare
Begin
PKG_System_Constant.SP_SetCurrentDate(To_Date('2001.01.01','yyyy.mm.dd'));
End;
/
--測試讀取全局變量
Select PKG_System_Constant.FN_GetCurrentDate From Dual;
10.
select aa.x from aa
where not exists (select 'x' from bb where aa.x = bb.x) ;
以上語句同時使用到了aa中x的索引和的bb中x的索引
11
SGA是Oracle為一個實例分配的一組共享內存緩沖區,它包含該實例的數據和控制信息。SGA在實例啟動時被自動分配,當實例關閉時被收回。數據庫的 所有數據操作都要通過SGA來進行。
SGA中內存根據存放信息的不同,可以分為如下幾個區域:
a.Buffer Cache:存放數據庫中數據庫塊的拷貝。它是由一組緩沖塊所組成,這些緩沖塊為所有與該實例相鏈接的用戶進程所共享。緩沖塊的數目由初始化參數 DB_BLOCK_BUFFERS確定,緩沖塊的大小由初始化參數DB_BLOCK_SIZE確定。大的數據塊可提高查詢速度。它由DBWR操作。
b. 日志緩沖區Redo Log Buffer:存放數據操作的更改信息。它們以日志項(redo entry)的形式存放在日志緩沖區中。當需要進行數據庫恢復時,日志項用於重構或回滾對數據庫所做的變更。日志緩沖區的大小由初始化參數 LOG_BUFFER確定。大的日志緩沖區可減少日志文件I/O的次數。後台進程LGWR將日志緩沖區中的信息寫入磁盤的日志文件中,可啟動ARCH後台 進程進行日志信息歸檔。
c. 共享池Shared Pool:包含用來處理的SQL語句信息。它包含共享SQL區和數據字典存儲區。共享SQL區包含執行特定的SQL語句所用的信息。數據字典區用於存放數 據字典,它為所有用戶進程所共享。
12.
使用分區方式建立的表叫分區表
范圍分區
每個分區都由一個分區鍵值范圍指定(對於一個以日期列作為分區鍵的表,“2005 年 1 月”分區包含分區鍵值為從“2005 年 1 月 1 日”
到“2005 年 1 月 31 日”的行)。
列表分區
每個分區都由一個分區鍵值列表指定(對於一個地區列作為分區鍵的表,“北美”分區可能包含值“加拿大”“美國”和“墨西哥”)。
分區功能通過改善可管理性、性能和可用性,從而為各式應用程序帶來了極大的好處。通常,分區可以使某些查詢以及維護操作的性能大大提高。此外,分區還可以 極大簡化常見的管理任務。通過分區,數據庫設計人員和管理員能夠解決前沿應用程序帶來的一些難題。分區是構建千兆字節數據系統或超高可用性系統的關鍵工 具。
13
回復的方法:
一.使用冷備份,直接將冷備份的文件全部COPY到原先的目錄下,在從新啟動數據庫就可以
二.使用歸檔日志,
1.啟動數據庫NOMOUNT
2.創建控制文件,控制文件指定數據文件和重做日志文件的位置.
3.使用RECOVER DATABASE using backup controlfile until cancel 命令回復數據庫,這時可以使用歸檔日志
4.ALETER DATABASE OPEN RESETLOGS;
5.重新備份數據庫和控制文件
14的話參考RMAN的使用手冊
15略
1、對數據庫SQL2005、ORACLE熟悉嗎?
SQL2005是微軟公司的數據庫產品。是一個RDBMS數據庫,一般應用在一些中型數據庫的應用,不能跨平台。
ORACLE是ORACLE公司的數據產品,支持海量數據存儲,支持分布式布暑,支持多用戶,跨平台,數據安全完整性控制性能優越,是一個ORDBMS, 一般用在大型公司。
2、能不能設計數據庫?如何實現數據庫導入與導出的更新
使用POWERDISINE工具的使用,一般滿足第三范式就可以了。EXP與IMP數據庫的邏輯導入與導出
3、如何只顯示重復數據,或不顯示重復數據
顯示重復:select * from tablename group by id having count(*)>1
不顯示重復:select * from tablename group by id having count(*)=1
4、什麼是數據庫的映射
就是將數據庫的表與字段對應到模型層類名與屬性的過程
5、寫分頁有哪些方法,你一般用什麼方法?用SQL語句寫一個分頁?
如何用存儲過程寫分頁?
在SQLSERVER中使用TOP分頁,在ORACLE中用ROWNUM,或分析函數ROW_NUMBER
使用TOP:
select top 20,n.* from tablename n minus select top 10,m.* from tablename m
使用分析函數:
select * from
(select n.*,row_number() over(order by columnname) num from tablename n)
where num>=10 and num <=20;
使用過程時,只要將分頁的范圍用兩個參數就可以實現。在ORACLE中,要將過程封裝在包裡,還要用動態游標變量才能實現數據集的返回。
6、ORACLE中左連接與右連接
左連接:LEFT JOIN 右連接:RIGHT JOIN
select n.column,m.column from tablename1 n left join tablename2 m
on n.columnname=m.columnname
用WHERE實現:
select n.column,m.column from tablename1 n, tablename2 m
where n.columnname(+)=m.columnname
7、什麼是反射、序列化、反序列化?事務有幾種級別?
反射是在程序運行時動態訪問DDL的一種方式。序列化是將對象對二進制、XML等方式直接向文件的存儲。反序列化是將存儲到文件的對象取出的過程。事務的 級別的三種:頁面級、應用程序級、數據庫級。
8、數據測試如何測試?
在PLSQL裡對過程或函數可能通過專用的測試工具,通過對
9、用事務的時候,如果在業務邏輯層中,調用數據庫訪問層中的方法,訪問層中有很多類,類又有很多方法,每個方法都要實現,那麼如何處理?
通用數據訪問層的實現
10、什麼時候會用到觸發器
A安全管理、B日志管理、C復雜業務邏輯實現
11、如何在數據庫中顯示樹控制?
用父ID與子ID來實現
12、如何實現數據庫的優化?
A、調整數據結構的設計。這一部分在開發信息系統之前完成,程序員需要考慮是否使用ORACLE數據庫的分區功能,對於經常訪問的數據庫表是否需要建立索 引等。
B、調整應用程序結構設計。這一部分也是在開發信息系統之前完成,程序員在這一步需要考慮應用程序使用什麼樣的體系結構,是使用傳統的 Client/Server兩層體系結構,還是使用Browser/Web/Database的三層體系結構。不同的應用程序體系結構要求的數據庫資源是 不同的。
C、調整數據庫SQL語句。應用程序的執行最終將歸結為數據庫中的SQL語句執行,因此SQL語句的執行效率最終決定了ORACLE數據庫的性能。 ORACLE公司推薦使用ORACLE語句優化器(Oracle Optimizer)和行鎖管理器(row-level manager)來調整優化SQL語句。
D、調整服務器內存分配。內存分配是在信息系統運行過程中優化配置的,數據庫管理員可以根據數據庫運行狀況調整數據庫系統全局區(SGA區)的數據緩沖 區、日志緩沖區和共享池的大小;還可以調整程序全局區(PGA區)的大小。需要注意的是,SGA區不是越大越好,SGA區過大會占用操作系統使用的內存而 引起虛擬內存的頁面交換,這樣反而會降低系統。
E、調整硬盤I/O,這一步是在信息系統開發之前完成的。數據庫管理員可以將組成同一個表空間的數據文件放在不同的硬盤上,做到硬盤之間I/O負載均衡。
F、調整操作系統參數,例如:運行在UNIX操作系統上的ORACLE數據庫,可以調整UNIX數據緩沖池的大小,每個進程所能使用的內存大小等參數。
3、BLOB和CLOB的區別在於
A CLOB只能存放字符類型的數據,而BLOB沒有任何限制
B BLOB只能存放字符類型的數據,而CLOB沒有任何限制
C CLOB只能存放小於4000字節的數據,而BLOB可以存放大於4000字節的數據
D BLOB只能存放小於4000字節的數據,而CLOB可以存放大於4000字節的數據
4、BFILE屬於()數據類型
A 簡單
B 標量
C 大對象
D 文件
三號題選A,blob和clob都是大對象數據類型,4000字節數據限制是在已被建議不再使用的long/long-raw中的限制,lob類型沒有4000字節限制。clob 指 charactor lob,blob 指 binary lob,因此 clob 只能存放字符型數據,而 blob 沒有限制。
四號題應該選 D, bfile代表文件,但是不想 lob 類型內容是存放在數據庫表內部的,而是存放在數據庫所在主機的文件系統中,因此 bfile 不是大對象。
完成下列操作,寫出相應的SQL語句
創建表空間neuspace,數據文件命名為neudata.dbf,存放在 d:\data目錄下,文件大小為200MB,設為自動增長,增量5MB,文件最大為500MB。(8分)
答:create tablespace neuspace datafile ‘d:\data\neudata.dbf’ size 200m auto extend on next 5m maxsize 500m;
2. 假設表空間neuspace已用盡500MB空間,現要求增加一個數據文件,存放在e:\appdata目錄下,文件名為appneudata,大小為 500MB,不自動增長。(5分)
答:alter tablespace neuspace add datafile ‘e:\appdata\appneudata.dbf’ size 500m;
3. 以系統管理員身份登錄,創建賬號tom,設置tom的默認表空間為neuspace。為tom分 配connect和resource系統角色,獲取基本的系統權限。然後為tom分配對用戶scott的表emp的select權限和對 SALARY, MGR屬性的update權限。(8分)
答:create user tom identified by jack default tablespace neuspace;
Grant connect, resource to tom;
Grant select, update(salary, mgr) on scott.emp to tom;
4. 按如下要求創建表class和student。(15分)
屬性
類型(長度)
默認值
約束
含義
CLASSNO
數值 (2)
無
主鍵
班級編號
CNAME
變長字符 (10)
無
非空
班級名稱
屬性
類型(長度)
默認值
約束
含義
STUNO
數值 (8)
無
主鍵
學號
SNAME
變長 字符 (12)
無
非空
姓 名
SEX
字符 (2)
男
無
性別
BIRTHDAY
日期
無
無
生日
變長字符 (20)
無
唯一
電子郵件
SCORE
數 值 (5, 2)
無
檢查
成 績
CLASSNO
數值 (2)
無
外鍵,關聯到表CLASS的CLASSNO主鍵
班級編號
答:create table class
(classno number(2) constraint class_classno_pk primary key,
cname varchar2(10) not null);
create table student
(stuno number(8) constraint student_stuno_pk primary key,
sname varchar2(12) not null,
sex char(2) default ‘男’,
birthday date,
email varchar2(20) constraint student_email_uk unique,
score number(5,2) constraint student_score_ck check(score>=0 and score<=100),
classno number(2) constraint student_classno_fk references class(classno)
);
5. 在表student的SNAME屬性上創建索引student_sname_idx(5分)
答:create index student_sname_idx on student(sname);
6. 創建序列stuseq,要求初值為20050001,增量為1,最大值為20059999。(6分)
答:create sequence stuseq increment by 1 start with 20050001 maxvalue 20059999 nocache nocycle;
7. 向表student中插入如下2行。(5分)
STUNO
SNAME
SEX
BIRTHDAY
SCORE
CLASSNO
從stuseq取值
tom
男
1979-2-3 14:30:25
tom@163.net
89.50
1
從 stuseq取值
jerry
默認值
空
空
空
2
答:insert into student values(stuseq.nextval, ’tom’, ’男’, to_date(‘1979-2-3
14:30:25’, ’yyyy-mm-dd fmhh24:mi:ss’), ’tom@163.net’, 89.50, 1);
insert into student (stuno, sname, classno) values(stuseq.nextval, ’jerry’, 2);
8. 修改表student的數據,將所有一班的學生成績加10分。(4分)
答:update student set score=score+10 where classno=1;
9. 刪除表student的數據,將所有3班出生日期小於1981年5月12日的記錄刪除。(4分)
答:delete from student where classno=3 and birthday > ’12-5月-81’;
10. 完成以下SQL語句。(40分)
(1) 按班級升序排序,成績降序排序,查詢student表的所有記錄。
答:select * from student order by classno, score desc;
(2) 查詢student表中所有二班的成績大於85.50分且出生日期大於1982-10-31日的男生的記錄。
答:select * from student where classno=2 and score>85.50 and birthday < ’31-10月-82’ and sex=’男’;
(3) 查詢student表中所有三班成績為空的學生記錄。
答:select * from student where classno=3 and score is null;
(4) 表student與class聯合查詢,要求查詢所有學生的學號,姓名,成績,班級名稱。(使用oracle與SQL 99兩種格式)
答:select s.stuno, s.sname, s.score, c.cname from student s, class c where s.classno=c.classno;
(5) 按班級編號分組統計每個班的人數,最高分,最低分,平均分,並按平均分降序排序。
答:select classno, count(*), max(score), min(score), avg(score) from student group by classno order by avg(score) desc;
(6) 查詢一班學生記錄中所有成績高於本班學生平均分的記錄。
答:select * from student where classno=1 and score > (select avg(score) from student where classno=1);
(7) 統計二班學生中所有成績大於所有班級平均分的人數。
答:select count(*) from student where classno=2 and score > all (select avg(socre) from student group by classno);
(8) 查詢平均分最高的班級編號與分數。
答:select classno, avg(score) from student group by classno having avg(score) = (select max(avg(score)) from student group by classno);
(9) 查詢所有學生記錄中成績前十名的學生的學號、姓名、成績、班級編號。
答:select stuno, sname, score, classno from (select * from student order by score desc) where rownum<=10;
(10) 創建視圖stuvu,要求視圖中包含student表中所有一班學生的stuno, sname, score, classno四個屬性,並具有with check option限制。
答:create view stuvu
as
select stuno, sname,score,classno from student where classno=1 with check option;
(1) 在關系R中,代數表達式 3 <4(R) 表示 ( )
A. 從R中選擇值為3的分量小於第4個分量的元組組成的關系
B. 從R中選擇第3個分量值小於第4個分量的元組組成的關系
C. 從R中選擇第3個分量的值小於4的元組組成的關系
D. 從R中選擇所有元組組成的關系
(2) 下面那些內容通常不屬於Oracle數據庫管理員的職責()
A.創建新用戶 B. 創建數據庫對象 C.安裝Oracle軟件 D. 操縱數據庫數據的應用程序開發
(3) 在Oracle 10G中,下面的命令快為什麼會失敗,選擇一個最佳答案()
run
{
connect target sys/oracle@ocp10g;
backup database including current controlfile();
}
A. 不能作為SYS進行連接,必須作為SYSDBA進行連接
B. 命令塊中不能出現CONNECT關鍵字
C. 命令塊中缺少ALLOCATE CHANNEL 命令
D.以上都不正確
(4)下面那些內容通常不屬於Oracle數據庫管理員的職責()
A.創建新用戶 B.創建數據庫對象
C.安裝Oracle軟件 D.操縱數據庫數據的應用程序開發
(5)Hibernate中關於使用HQL語句描述不正確的是()
A.是一種符合對象語言的查詢語句
B.能夠避免使用 sql 的情況下依賴數據庫特征的情況出現
C.能夠根據 OO 的習慣去進行實體的查詢
D.理解SQL的人很難理解HQL
(6)在使用JDBC連接到數據源過程中,我們使用了以下getConnection方法調用: Connection conn=DriverManager.getConnection( jdbc:odbc:thin:@host:1521:mydb”, “scott”, “tiger”);則( )
A該連接字符串是錯誤的
B該語句建立了一個到本地ODBC數據源的連接
C該語句建立了一個到本地Oracle數據庫的連接
D該語句建立了一個到本地JDataStore數據庫的連接
(7)試圖創建一個表空間,但是卻收到無法為這個表空間創建數據文件的錯誤信息,希望創建的數據文件的大小為3GB,同時為表空間指定了 SMALLFILE選項,指定駐留數據文件的操作系統目錄經驗證屬於與Oracle相同的用戶,並且該用戶具有完整的讀/寫權限,作為SYSTEM登錄數 據庫,而硬盤上具有足夠的磁盤空間,那麼出現錯誤的原因可能是什麼()
A指定SALLFILE選項時,不能在Oracle數據庫內創建大於2GB的文件
B操作系統無法創建大於2GB的文件
C必須為數據文件規范指定WITH OVERWRITE選項
D必須為數據文件規范指定REUSE選項
(8) Hibernate中關於使用HQL語句描述不正確的是()
A.是一種符合對象語言的查詢語句
B.能夠避免使用 sql 的情況下依賴數據庫特征的情況出現
C.能夠根據 OO 的習慣去進行實體的查詢
D.理解SQL的人很難理解HQL
(9)下列哪個術語描述了棧(Stack)類使用List的內部實例實現。()
A關聯 B特化 C泛化 D組裝
(10)有關系模式A(C,T,H,R,S),其中各屬性的含義是:C:課程 T:教員 H:上課時間 R:教室 S:學生 根據語義有如下函數依賴集:F={C→T,(H,R)→C,(H,T)→R,(H,S)→R} 現將關系模式A分解為兩個關系模式A1(C,T),A2(H,R,S),則其中的A1的規范化程度達到
A. 1NF B.2NF C.3NF D.BCNF
(11).在Oracle 10G中,下列哪個進程負責實現 Automatic Shared Memory Management ()
A. MMAN 進程
B. MMON進程
C. MMNL進程
D. PMON進程
(12) .在Oracle 10G中,下列哪一個選項不是PGA的一部分()
A.綁定信息
B.分析信息
C.會話變量
D.排序空間
(13).在Oracle 10G中,下列那些內容是創建數據庫所必須的,選擇一個最佳答案()
A. 操作系統根用戶(針對Unix/Linux系統)或Administrator(針對Windows系統)的口令
B. 運行DBCA的權限
C. RAM的大小不少於SGA的大小
D. 以上都不是
(14).在Oracle 10G中,如何能夠減少一個索引段所占有的空間()
A.聚結這個索引
B.縮小這個索引
C.重構這個索引
D.使用CASCADE選項縮小這個索引表
(15) .在Oracle 10G中,Database Control是一種多層WEB應用程序,哪一層負責窗口管理()
A.dbconsole 中間層
B.數據庫層內的過程
C.客戶浏覽
D. OC4J應用程序運行時環境
(16) 在Oracle 10G中,下列那些內容是創建數據庫所必須的,選擇一個最佳答案()
A.操作系統根用戶(針對Unix/Linux系統)或Administrator(針對Windows系統)的口令
B.運行DBCA的權限
C.RAM的大小不少於SGA的大小
D.以上都不是
(17) .有關系模式A(C,T,H,R,S),其中各屬性的含義是:
C:課程 T:教員 H:上課時間 R:教室 S:學生
根據語義有如下函數依賴集:
F={C→T,(H,R)→C,(H,T)→R,(H,S)→R}
關系模式A的規范化程度最高達到______
A 1NF
B 2NF
C 3NF
D BCNF
(18) .在Oracle 10G中,如何能夠減少一個索引段所占有的空間()
A聚結這個索引
B縮小這個索引
C重構這個索引
D使用CASCADE選項縮小這個索引表
(19) .在Oracle 10G中,閃回存在外鍵關系的兩個表的最佳方法是什麼()
A先閃回子表,然後再閃回父表
B先閃回父表,然後再閃回子表
C在一個操作中閃回這兩個表
D沒有其他辦法,閃回操作不保護外鍵約束
(20) 在Oracle 10G中,AWR快照在何時生成()
A每隔一個小時
B每隔十分鐘
C根據要求決定
D根據要求定期生成
(21) .在Oracle 10G中,打開數據庫時,下列那些文件必須被同步,選擇一個最佳答案()
A數據文件、聯機重做日志文件以及控制文件
B參數文件和口令文件
C所有多元化控制文件副本
D不需要同步任何文件,SMON進程會在打開數據庫之後通過實例恢復來同步所有文件
(22) .在Oracle 10G中,如果已經創建了一個數據庫,但是無法使用Database Control進行連接,這是什麼原因,選擇一個最佳答案()
A沒有通過操作系統的身份驗證,或者沒有進行口令文件身份驗證
B沒有運行腳本創建Database Control
CGrid Control是Database Control的必備條件
D沒有被許可使用Database Control
(23) .在Oracle 10數據庫中,如果需要以秒為單位記錄日期/時間值,下列那種數據類型的列適合存儲這個信息()
A TIME
B DATETIME
C DATE或TIMESTAMP
D 因為Oracle的內部數據類型只能存儲日期和時間,必須開發一種自定義的數據類型
實現
(24) .在Oracle 10G中,如何連接ASM實例()
A只使用操作系統身份驗證
B只使用口令文件身份驗證
C只使用數據字典身份驗證
D以上選項都不正確
(25).在Oracle 10G中,當在執行一條多記錄更新語句時會違反某個約束,那會出現什麼情況,選擇一個最佳答案()
A違反約束的更新會被回滾,這條語句的剩余部分則保持不變
B整條語句都會被回滾
C整個事務都會被回滾
D取決於是否執行了alter session enable resumable
(26) .在Oracle 10G中,自動工作負荷庫(簡寫AWR)被存儲在哪個位置()
A存儲在SYSAUX表空間內
B儲在SYSTEM表空間內
C在系統全局區內
D我們可以在數據庫創建階段選擇AWR的存儲位置,隨後還可以重新定位這個位置
(27)在關系模式R(U,F)中,X,Y,Z是U中屬性,則多值依賴的傳遞律是 ( )
A如果X→→Y,Y→→Z,則X→→Z
B如果X→→Y,Y→→Z,則X→→YZ
C如果X→→Z,Y→→Z,則X→→YZ
D如果X→→Y,Y→→Z,則X→→Z-Y
(28) .數據庫中全體數據的整體邏輯結構描述稱為 ( )
A存儲模式
B內模式
C外模式
D右外模式
(29) .在使用JDBC連接到數據源過程中,我們使用了以下getConnection方法調用: Connection conn=DriverManager.getConnection( jdbc:odbc:thin:@host:1521:mydb”, “scott”, “tiger”);則( )
A該連接字符串是錯誤的
B該語句建立了一個到本地ODBC數據源的連接
C該語句建立了一個到本地Oracle數據庫的連接
D該語句建立了一個到本地JDataStore數據庫的連接
(30) 物理結構設計的任務是設計數據庫的( )
A存儲格式
B存取方法
C存儲結構與存取方法
D存儲模式
(31)分布式數據庫兩階段提交協議是指( )
A加鎖階段、解鎖階段
B擴展階段、收縮階段
C獲取階段、運行階段
D表決階段、執行階段
(32) 在Oracle 10G中,創建一個新的用戶帳戶時,如果沒有指定TEMPORAAY TABLESPACE ,那麼該參數在這個用戶被創建時具有怎樣的值()
A SYSTEM
B TEMP
C NULL
D數據庫默認的臨時表空間
(33)在以下的DBMS中,可用於UNIX和Windows操作系統的是( )
A SQLServer 2000
B foxpro
C Sybase
D access
(34) 在Oracle 10G中,下列哪種文件可以被視為非關鍵的()
A臨時數據文件
B撤銷數據文件
C復用的控制文件
D以上所有文件
(35) 在Oracle 10G中,用戶如何改變其有效的配置文件()
A ALTER USER SET PROFILE=NewProfile
B ALTER SYSTEM SET PROFILE=NewProfile
C ALTER SESSION SET PROFILE=NewProfile
D用戶無法改變其有效的配置文件
(36)在Oracle 10G中,RDBMS實例能夠訪問ASM文件之前,ASM實例必須位於哪一種模式中()
A NOMOUNT模式
B MOUNT模式
C OPEN模式
D MOUNT或者OPEN模式
(2010年01月08日) 發表於 JavaEye博客
一、 求1-100之間的素數
declare
fag boolean:=true;
begin
for i in 1..100 loop
for j in 2..i-1 loop
if mod(i,j)=0 then
fag:=false;
end if;
end loop;
if fag then
dbms_output.put_line(i);
end if;
fag:=true;
end loop;
end;
二、 對所有員工,如果該員工職位是MANAGER,並且在DALLAS工作那麼就給他薪金加15%;如果該員工職位是CLERK,並且在NEW YORK工作那麼就給他薪金扣除5%;其他情況不作處理
declare
cursor c1 is select * from emp;
c1rec c1%rowtype;
v_loc varchar2(20);
begin
for c1rec in c1 loop
select loc into v_loc from dept where deptno = c1rec.deptno;
if c1rec.job = 'MANAGER' and v_loc = 'DALLAS' then
update emp set sal = sal * 1.15 where empno = c1rec.empno;
elsif c1rec.job='CLERK' and v_loc = 'NEW YORK' then
update emp set sal = sal * 0.95 where empno = c1rec.empno;
else
null;
end if;
end loop;
end;
三、對直接上級是'BLAKE'的所有員工,按照參加工作的時間加薪:
81年6月以前的加薪10%
81年6月以後的加薪5%
declare
cursor c1 is select * from emp where mgr = (select
empno from emp where ename='BLAKE'); --直接上級是'BLAKE'的所有員工
c1rec c1%rowtype;
begin
for c1rec in c1 loop
if c1rec.hiredate < '01-6月-81' then
update emp set sal = sal * 1.1 where empno = c1rec.empno;
else
update emp set sal = sal * 1.05 where empno = c1rec.empno;
end if;
end loop;
end;
三、 根據員工在各自部門中的工資高低排出在部門中的名次(允許並列).
<1> 一條SQL語句
select deptno,ename,sal,(select count(*) + 1
from emp where deptno = a.deptno
and sal > a.sal) as ord
from emp a
order by deptno,sal desc;
<2> PL/SQL塊
declare
cursor cc is
select * from dept;
ccrec cc%rowtype;
cursor ck(no number) is
select * from emp where deptno = no order by sal desc;
ckrec ck%rowtype;
i number;
j number;
v_sal number:=-1;
begin
for ccrec in cc loop
i := 0;
for ckrec in ck(ccrec.deptno) loop
i := i + 1;
--寫入臨時表
if ckrec.sal = v_sal then
null;
else
j:=i;
end if;
--顯示
DBMS_OUTPUT.put_line(ccrec.deptno||chr(9)||ccrec.ename||chr(9)||ckrec.sal||chr(9)||j);
v_sal := ckrec.sal;
end loop;
end loop;
end;
四、編寫一個觸發器實現如下功能:
對修改職工薪金的操作進行合法性檢查:
a) 修改後的薪金要大於修改前的薪金
b) 工資增量不能超過原工資的10%
c) 目前沒有單位的職工不能漲工資
create or replace trigger tr1
after update of sal on emp
for each row
begin
if :new.sal <= :old.sal then
raise_application_error(-20001,'修改後的薪金要大於修改前的薪金');
elsif :new.sal > :old.sal * 1.1 then
raise_application_error(-20002,'工資增量不能超過原工資的10%');
elsif :old.deptno is null then
raise_application_error(-20003,'沒有單位的職工不能漲工資');
end if;
end;
四、 編寫一個PL/SQL程序塊,對名字以"A"或"S"開始的所有雇員按他們的基本薪水的10%加薪。
DECLARE
CURSOR c1 IS
SELECT * FROM emp WHERE SUBSTR(ename,1,1)=´A´ OR SUBSTR(ename,1,1)=´S´ FOR UPDATE OF sal;
BEGIN
FOR i IN c1
LOOP
UPDATE emp SET sal=NVL(sal,0)+NVL(sal,0)*0.1 WHERE CURRENT OF c1;
END LOOP;
END;
/
五、編寫一PL/SQL,對所有的"銷售員"(SALESMAN)增加傭金500.
DECLARE
CURSOR c1 IS
SELECT * FROM emp WHERE job=´SALESMAN´ FOR UPDATE OF sal;
BEGIN
FOR i IN c1
LOOP
UPDATE emp SET sal=NVL(sal,0)+500 WHERE CURRENT OF c1;
END LOOP;
END;
/
六、編寫一PL/SQL,以提升兩個資格最老的"職員"為"高級職員"。(工作時間越長,優先級越高)
DECLARE
CURSOR c1 IS
SELECT * FROM emp WHERE job=´CLERK´ ORDER BY hiredate FOR UPDATE OF job;
--升序排列,工齡長的在前面
BEGIN
FOR i IN c1
LOOP
EXIT WHEN c1%ROWCOUNT>2;
DBMS_OUTPUT.PUT_LINE(i.ename);
UPDATE emp SET job=´HIGHCLERK´ WHERE CURRENT OF c1;
END LOOP;
END;
/
七、編寫一PL/SQL,對所有雇員按他們基本薪水的10%加薪,如果所增加的薪水大於5000,則取消加薪。
DECLARE
CURSOR c1 IS SELECT * FROM emp FOR UPDATE OF sal;
BEGIN
FOR i IN c1
LOOP
IF (i.sal+i.sal*0.1)<=5000 THEN
UPDATE emp SET sal=sal+sal*0.1 where
Empno=i.empno
DBMS_OUTPUT.PUT_LINE(i.sal);
END IF;
END LOOP;
END;
/
八、顯示EMP中的第四條記錄。
DECLARE
CURSOR c1 IS SELECT * FROM emp;
BEGIN
FOR i IN c1
LOOP
IF c1%ROWCOUNT=4 THEN
DBMS_OUTPUT.PUT_LINE(i. EMPNO || ´ ´ ||i.ENAME || ´ ´ || i.JOB || ´ ´ || i.MGR || ´ ´ || i.HIREDATE || ´ ´ || i.SAL || ´ ´ || i.COMM || ´ ´ || i.DEPTNO);
EXIT;
END IF;
END LOOP;
END;
/
九、.編寫一個給特殊雇員加薪10%的過程,這之後,檢查如果已經雇傭該雇員超過60個月,則給他額外加薪3000.
CREATE OR REPLACE PROCEDURE Raise_Sal(no IN NUMBER) AS
vhiredate DATE;
vsal emp.sal%TYPE;
BEGIN
SELECT hiredate,sal INTO vhiredate,vsal FROM emp WHERE empno=no;
IF MONTHS_BETWEEN(SYSDATE,vhiredate)>60 THEN
vsal:=NVL(vsal,0)*1.1+3000;
ELSE
vsal:=NVL(vsal,0)*1.1;
END IF;
UPDATE emp SET sal=vsal WHERE empno=no;
END;
/
VARIABLE no NUMBER
BEGIN
:no:=7369;
END;
/
十、編寫一個函數以檢查所指定雇員的薪水是否有效范圍內。不同職位的薪水范圍為:
Designation Raise
Clerk 1500-2500
Salesman 2501-3500
Analyst 3501-4500
Others 4501 and above.
如果薪水在此范圍內,則顯示消息"Salary is OK",否則,更新薪水為該范圍內的最水值。
CREATE OR REPLACE FUNCTION Sal_Level(no emp.empno%TYPE) RETURN CHAR AS
vjob emp.job%TYPE;
vsal emp.sal%TYPE;
vmesg CHAR(50);
BEGIN
SELECT job,sal INTO vjob,vsal FROM emp WHERE empno=no;
IF vjob=´CLERK´ THEN
IF vsal>=1500 AND vsal<=2500 THEN
vmesg:=´Salary is OK.´;
ELSE
vsal:=1500;
vmesg:=´Have updated your salary to ´||TO_CHAR(vsal);
END IF;
ELSIF vjob=´SALESMAN´ THEN
IF vsal>=2501 AND vsal<=3500 THEN
vmesg:=´Salary is OK.´;
ELSE
vsal:=2501;
vmesg:=´Have updated your salary to ´||TO_CHAR(vsal);
END IF;
ELSIF vjob=´ANALYST´ THEN
IF vsal>=3501 AND vsal<=4500 THEN
vmesg:=´Salary is OK.´;
ELSE
vsal:=3501;
vmesg:=´Have updated your salary to ´||TO_CHAR(vsal);
END IF;
ELSE
IF vsal>=4501 THEN
vmesg:=´Salary is OK.´;
ELSE
vsal:=4501;
vmesg:=´Have updated your salary to ´||TO_CHAR(vsal);
END IF;
END IF;
UPDATE emp SET sal=vsal WHERE empno=no;
RETURN vmesg;
END;
/
DECLARE
vmesg CHAR(50);
vempno emp.empno%TYPE;
BEGIN
vempno:=&empno;
vmesg:=Sal_Level(vempno);
DBMS_OUTPUT.PUT_LINE(vmesg);
END;
/
--SELECT empno,ename,sal,comm,hiredate FROM emp WHERE empno=:no;
十二、有如下MyTable:
日期 日產
1 3.3333
2 4.2222
3 1.5555
4 9.8888
5 ………
要求用SQL語句生成如下查詢
日期 日產 累計日產
1 3.3333 3.3333
2 4.2222 7.5555
3 1.5555 9.0000
4 9.8888 18.8888
5………
select id,quantity,(select sum(quantity)from mytable where id<=t.id) as acount from mytable t
十三、創建一個序列,第一次從5循環到10,以後再從0開始循環
create sequence test_seq
start with 5
increment by 1
maxvalue 10
minvalue 0
cycle
nocache
面試sql題
中軟面試的一個sql題。
題目:
1、每個科目的最高分。
2、java成績最高的姓名
3、java成績第二高的姓名
第一個沒什麼好說的。
對第二題和第三題,取得成績可能有多的。可以使用分析函數。DENSE_RANK
SELECT t.name,
t.kemu,
t.score,
DENSE_RANK() OVER (PARTITION BY t.kemu ORDER BY t.score) seq
FROM ke_chengji t;
一道SQL面試題
有兩個表, table1, table2,
Table table1:
SELLER | NON_SELLER
----- -----
A B
A C
A D
B A
B C
B D
C A
C B
C D
D A
D B
D C
Table table2:
SELLER | COUPON | BAL
----- --------- ---------
A 9 100
B 9 200
C 9 300
D 9 400
A 9.5 100
B 9.5 20
A 10 80
要求用SELECT 語句列出如下結果:------如A的SUM(BAL)為B,C,D的和,B的SUM(BAL)為A,C,D的和.......
且用的方法不要增加數據庫負擔,如用臨時表等.
NON-SELLER| COUPON | SUM(BAL) ------- --------
A 9 900
B 9 800
C 9 700
D 9 600
A 9.5 20
B 9.5 100
C 9.5 120
D 9.5 120
A 10 0
B 10 80
C 10 80
D 10 80
下面是我的方法,不知道哪位高手有更好的方法請出招。
select distinct(a.seller),b.coupon,
nvl((select sum(bal) from table2 where seller in
(select non_seller from table1 where seller=a.seller)
and coupon=b.coupon),0) as sumbal
from table1 a
left join table2 b on 1=1 order by b.coupon ;
一道sql面試題
題目:
表B
C1 C2
2005-01-01 1
2005-01-01 3
2005-01-02 5
要求的輸出數據
C1 C2
2005-01-01 4
2005-01-02 5
合計 9
試用一個Sql語句完成。
該題目主要考的是分析函數函數over (partition by)的使用
--創建表B
create table b
(c1 varchar2(14),c2 number);
insert into b
values('2005-01-01',1) ;
insert into b
values('2005-01-01',3) ;
insert into b
values('2005-01-02',5) ;
commit;
select c1,sum(c2) over(partition by c1)
from b
union
select '合計:',sum(c2) over(partition by null)
from b;
C1 SUM(C2)OVER(PARTITIONBYC1)
-------------- --------------------------
2005-01-01 4
2005-01-02 5
合計: 9
最近面試中sql題
一.SQL問答題
SELECT * FROM TABLE
和
SELECT * FROM TABLE
WHERE NAME LIKE '%%' AND ADDR LIKE '%%'
AND (1_ADDR LIKE '%%' OR 2_ADDR LIKE '%%'
OR 3_ADDR LIKE '%%' OR 4_ADDR LIKE '%%' )
的檢索結果為何不同?
(1).like通配符一個個比較肯定影響效率,
(2).數據庫中存在null的時候,如果字段中有null存在select * from table 可以顯示所有的內容,但是like不會通配null,所以字段為null它顯示不出來!!
二.select count(*) from table
和select count(1) from talbe的區別??
只明白count(字段)時它是不檢索null的!
但是在count中1和*現在還沒有明確答案,求高手!!!~
--1
select max(sal) ,min(sal) from emp group by deptno;
--2
select max(sal) ,min(sal) from emp where job='CLERK' group by deptno;
--3
select deptno,max(sal) ,min(sal) from emp where job='CLERK' and deptno=(select deptno from emp group by deptno having min(sal)<1000) group by deptno;
--4
select ename,deptno,sal from emp order by deptno desc,sal
--5
select ename,deptno from emp where deptno = (select deptno from emp where ename='張三')
--6
select e.ename,e.job,e.deptno,d.dname from emp e left join dept d on d.deptno=e.deptno
--7
select e.ename,e.job,e.deptno,d.dname from emp e left join dept d on d.deptno=e.deptno where e.job='CLERK'
--8
select e.ename,m.mname from emp e left join mgr m on m.mgr=e.mgr
--9
select * from (select ename, job from emp where job='CLERK') a union all select dname, deptno from dept ;
--10
select e.deptno,e.ename,e.sal from emp e left join (select deptno, avg(sal) SV from emp group by deptno) b on
b.deptno=e.deptno where e.sal>b.SV order by e.deptno ;
--11
select count(e.deptno),e.deptno from emp e left join (select deptno, avg(sal) SV from emp group by deptno) b on
b.deptno=e.deptno where e.sal>b.SV group by e.deptno order by e.deptno;
--12
select e.deptno,count(e.deptno) from emp e left join (select deptno, avg(sal) SV from emp group by deptno) b on
b.deptno=e.deptno where e.sal>b.SV group by e.deptno having count(e.deptno)>1 order by e.de......余下全文>>
1.
update t
set logdate=to_date('2003-01-01','yyyy-mm-dd')
where logdate=to_date('2001-02-11','yyyy-mm-dd');
2.
select *
from t
where name in (select name from t group by name having coung(*)>1)
order by name;--沒說清楚,到底是升序還是降序
3.
select ID,NAME,ADDRESS,PHONE,LOGDATE
from
(
select t.*,row_number() over(partition by name order by name) rn
from t
)
where rn = 1;
4.
update t
set (address,phone)=
(select address,phone from e where e.name=t.name);
5.
select *
from t
where rownum <=5
minus
select *
from t
where rownum <=2;
也沒什麼特別的地方,有些題目用oracle特有的函數去做會比較簡單,像在第三題中用到的oracle的分析函數,以及在第一題中用到的oracle的to_char()函數。
這幾個題目主要是看你能不能使用oracle的函數去處理