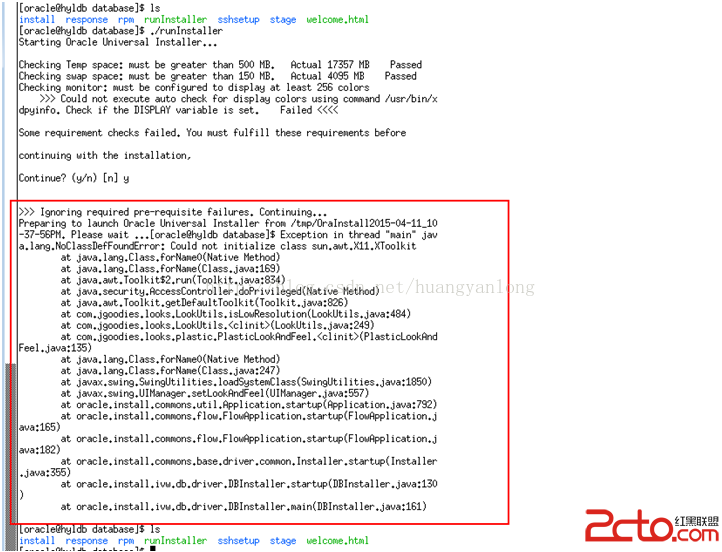
hr@ora10g > create table t1 as select object_id as id,object_name from dba_objects; hr@ora10g > update t1 set id=1 where rownum<=10000; hr@ora10g > commit; hr@ora10g > create index idx_t1 on t1(id);
這樣,該表裡id為的1記錄有一萬條,而id為其他值的記錄都只有一條。從而,我們構建出一個分布不均勻的測試用表。然後,我們收集一下統計信息。注意,這裡要收集直方圖,為的是要讓CBO知道id列上的數據分布不均勻。
hr@ora10g> begin 2 dbms_stats.gather_table_stats( 3 user, 4 't1', 5 cascade => true, 6 method_opt => 'for columns id size 254' 7 ); 8 end; 9 / 我們找到表t1裡最大的id,然後以該id作為第一個綁定變量傳入,可以想象,該綁定變量將導致走索引。注意,我們這裡設定的優化器目標為all_rows。
從上面結果可以看出,在為綁定變量傳入第一個值為13871時,由於返回的記錄條數較少,導致走索引掃描。當我們第二次傳入綁定變量值1時,oracle不再生成新的執行計劃,而直接拿索引掃描的執行路徑來用。
但是,如果先傳入1的綁定變量值,然後再傳入13871的綁定變量值時,會怎樣?我們繼續測試。
hr@ora10g> alter system flush shared_pool; hr@ora10g> set autotrace traceonly exp stat; hr@ora10g> exec :v_id := 1; hr@ora10g> select * from t1 where id=:v_id; hr@ora10g > begin 2 select sql_id into :v_sql_id from v$sql 3 where sql_text like 'select * from t1 where id=:v_id%'; 4 end; 5 / hr@ora10g > select * from table(dbms_xplan.display_cursor(:v_sql_id)); PLAN_TABLE_OUTPUT -------------------------------------------------------------------------------- SQL_ID djwq30cpbcz7k, child number 0 ------------------------------------- select * from t1 where id=:v_id Plan hash value: 3617692013 -------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | 13 (100)| | |* 1 | TABLE ACCESS FULL | T1 | 8738 | 179K | 13 (0) | 00:00:01 | -------------------------------------------------------------------------- ...... hr@ora10g > exec :v_id := 13871; hr@ora10g > select * from t1 where id=:v_id; hr@ora10g > begin 2 select sql_id into :v_sql_id from v$sql 3 where sql_text like 'select * from t1 where id=:v_id%'; 4 end; 5 / hr@ora10g > select * from table(dbms_xplan.display_cursor(:v_sql_id)); PLAN_TABLE_OUTPUT -------------------------------------------------------------------------------- SQL_ID djwq30cpbcz7k, child number 0 ------------------------------------- select * from t1 where id=:v_id Plan hash value: 3617692013 -------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | 13 (100)| | |* 1 | TABLE ACCESS FULL | T1 | 8738 | 179K | 13 (0) | 00:00:01 | -------------------------------------------------------------------------- 很明顯,先傳入1的綁定變量時將導致生成的執行計劃走全表掃描。後面傳入的13871的綁定變量的最佳執行路徑應該是索引掃描,但是由於CBO並不知道這一點,而是直接拿第一次生成的執行計劃來用了,於是也走全表掃描了。
2. 11g之後的動態綁定變量窺視
而從11g開始,這個尴尬的問題開始得到了改善。因此從11g開始,引入了所謂的自適應游標共享(Adaptive Cursor Sharing)。該特性是一個非常復雜的技術,用來平衡游標共享和SQL優化這兩個矛盾的目標。11g裡不會盲目的共享游標,而是會去查看每個綁定變量,並為不同的綁定變量來產生不同的執行計劃。而oracle這麼做的前提是,使用多個執行計劃的所帶來的收益,要比產生多個執行計劃所引起的CPU開銷要更大。
使用自適應游標共享時,會遵循下面的步驟:
1) 一條新的SQL語句第一次傳入shared pool時,還是和以前一樣,進行硬解析。而且進行綁定變量窺視,計算where條件各個列的selectivity,同時如果綁定變量所在的列上存在直方圖的話,也會去參考該直方圖來計算selectivity。該游標會被標記為是一個綁定敏感的游標(bind-sensitive cursor)。同時,oracle還會保留包含綁定變量的where條件的其他信息,比如selectivity等。Oracle會為該謂詞的selectivity維持一個范圍,oracle叫做立方體(cube)。只要傳入的綁定變量所產生的selectivity落在該范圍裡面,也就是落在該cube裡面,就不產生新的執行計劃,而直接拿該cube所對應的執行計劃來用。
2) 下次再次執行相同的SQL時,傳入了新的綁定變量,假設使用新的綁定變量的謂詞的selectivity落在已經存在的cube范圍裡,於是這次SQL的執行會使用該cube所對應的執行計劃。
3) 相同的查詢再次執行時,假設所使用的新的綁定變量導致這時候的selectivity不再落在已經存在的cube裡了,於是也就找不到對應的執行計劃。於是系統會進行一個硬解析,這將產生第二個新的執行計劃。而且新的selectivity以及對應的cube也會保存下來。也就是說,這時,我們分別有兩個cube以及兩個執行計劃。
4) 相同的查詢再次執行時,假設所使用的新的綁定變量導致這時候的selectivity不落在現存的兩個cube中的任何一個,所以系統又會進行硬解析。假設這時硬解析所產生的執行計劃與第一次產生執行計劃一樣,也就是說,在第一次評估selectivity的cube時過於保守,導致cube過小,進而導致了這一次的不必要的硬解析。於是,oracle會將第一次產生的cube與這次產生的cube合並成一個新的更大的cube。那麼,下次再次進行軟解析的時候,如果selectivity落在新的cube裡,則會使用第一次所產生的執行計劃。
我們從這裡可以看到,11g對這個問題的處理非常精彩。這樣做的結果是,系統開始運行時,CPU消耗可能會比較嚴重,但是隨著系統不斷運行,cube的不斷合並從而不斷擴大,於是系統的CPU消耗會不斷下降,同時執行計劃也會更加的合理。
我們來做個試驗進行驗證。我們采用11g新引入的執行計劃管理特性來驗證該特性。
與10g中的測試一樣,創建一個數據分布不均勻的表,在數據分布不均勻的列上創建索引,並收集統計信息,收集時注意要收集直方圖,從而讓CBO知道該列上的數據分布不均勻。
hr@ora11g > create table t1 as select object_id as id,object_name from dba_objects; hr@ora11g > select count(*) from t1; COUNT(*) ---------- 12064 hr@ora11g > update t1 set id=1 where rownum<=10000; hr@ora11g > commit; hr@ora11g > create index idx_t1 on t1(id); hr@ora11g > begin 2 dbms_stats.gather_table_stats( 3 user, 4 't1', 5 cascade => true, 6 method_opt => 'for columns id size 254' 7 ); 8 end; 9 /
我們找到表t1裡最大的id,然後以該id作為第一個綁定變量傳入,可以想象,該綁定變量將導致走索引。
hr@ora11g > select max(id) from t1; MAX(ID) ---------- 12462 我們將optimizer_capture_plan_baselines設置為true,從而讓oracle自動獲取plan baseline。 hr@ora11g > alter system set OPTIMIZER_CAPTURE_PLAN_BASELINES=true; hr@ora11g > alter system flush shared_pool; hr@ora11g > var v_id number; hr@ora11g > exec :v_id := 12462; hr@ora11g > select * from t1 where id=:v_id; hr@ora11g > select * from t1 where id=:v_id;
我們運行兩遍select * from t1 where id=:v_id,從而讓oracle捕獲plan baseline。我們知道id為12462的記錄只有一條,因此該SQL應該使用索引掃描。然後我們再為綁定變量傳入1,我們知道id為1的記錄有一萬條,所以較好的執行計劃不應該走已經生成的執行計劃,而應該走全表掃描。
hr@ora11g > exec :v_id := 1; hr@ora11g > set autotrace traceonly stat; --之所以設置stat是為了讓該sql實際執行,但不要返回所有記錄, hr@ora11g > select * from t1 where id=:v_id; hr@ora11g > select sql_handle,plan_name,origin,enabled,accepted 2 from dba_sql_plan_baselines where sql_text like 'select * from t1%'; SQL_HANDLE PLAN_NAME ORIGIN ENA ACC ----------------------- ----------------------------- -------------- --- --- SYS_SQL_ea05bbed6f2f670c SYS_SQL_PLAN_6f2f670c844cb98a AUTO-CAPTURE YES YES SYS_SQL_ea05bbed6f2f670c SYS_SQL_PLAN_6f2f670cdbd90e8e AUTO-CAPTURE YES NO
我們可以發現,現在該SQL語句存在兩個執行計劃了,其中第一個執行計劃,也就是accepted為YES的執行計劃為v_id等於12462得到的,而第二個執行計劃,也就是accepted為NO的是由v_id等於1得到的。第二個執行計劃還沒有被加入plan baseline,所以優化器不會使用該執行計劃。我們將第二個執行計劃的accepted改為YES,從而讓oracle考慮使用該計劃。
hr@ora11g > var cnt number; hr@ora11g > begin 2 :cnt := dbms_spm.alter_sql_plan_baseline( 3 sql_handle => 'SYS_SQL_ea05bbed6f2f670c', 4 plan_name => 'SYS_SQL_PLAN_6f2f670cdbd90e8e', 5 attribute_name => 'ACCEPTED', attribute_value => 'YES'); 6 end; 7 /
我們來看一下這兩個執行計劃分別是怎樣的。
注意:在這裡我們要驗證oracle會為不同綁定變量生成不同的執行計劃時,不能使用set autotrace traceonly exp stat等其他方式。因為set autotrace得出的執行計劃始終都是第一次生成的執行計劃。我們通過plan baseline從側面來驗證它。當然,我們也可以通過設置sql_trace=true從而將執行計劃轉儲出來進行驗證。
SQL> select * from table(dbms_xplan.display_sql_plan_baseline
2 ('SYS_SQL_ea05bbed6f2f670c','SYS_SQL_PLAN_6f2f670c844cb98a'));
......
--------------------------------------------------------------------------------
Plan hash value: 50753647
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 6 | 126 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| T1 | 6 | 126 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_T1 | 6 | | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------
......
SQL> select * from table(dbms_xplan.display_sql_plan_baseline
2 ('SYS_SQL_ea05bbed6f2f670c','SYS_SQL_PLAN_6f2f670cdbd90e8e'));
......
--------------------------------------------------------------------------------
Plan hash value: 3617692013
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU) | Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 6 | 126 | 16 (0) | 00:00:01 |
|* 1 | TABLE ACCESS FULL | T1 | 6 | 126 | 16 (0) | 00:00:01 |
--------------------------------------------------------------------------
......
很明顯,第一個是索引掃描,第二個是全表掃描。同樣,我們來看一下v$sql裡該sql語句有幾條記錄。
hr@ora11g > select sql_text,sql_id,child_number,plan_hash_value 2 from v$sql where sql_text like 'select * from t1 where%'; SQL_TEXT SQL_ID CHILD_NUMBER PLAN_HASH_VALUE --------------------------------- ------------- ------------ ---------------- select * from t1 where id=:v_id 7y7tt6xyhas1g 0 50753647
可以看到,該SQL語句目前在內存裡只存在一個執行計劃,其plan hash value就等於我們在前面plan baseline裡看到的第一個走索引的執行計劃的hash value。我們把該執行計劃顯示出來進行確認。
hr@ora11g > select * from table(dbms_xplan.display_cursor('7y7tt6xyhas1g',0));
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
SQL_ID 7y7tt6xyhas1g, child number 0
-------------------------------------
select * from t1 where id=:v_id
Plan hash value: 50753647
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
| 0 | SELECT STATEMENT | | | | 2 (100) | |
| 1 | TABLE ACCESS BY INDEX ROWID| T1 | 1 | 21 | 2 (0) | 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_T1 | 1 | | 1 (0) | 00:00:01 |
......
結果很明顯,正是走索引的執行計劃。然後我們繼續為幫定變量傳入1,多執行幾次。
hr@ora11g > exec :v_id := 1;
hr@ora11g > set autotrace traceonly stat;
hr@ora11g > select * from t1 where id=:v_id;
hr@ora11g > select * from t1 where id=:v_id;
hr@ora11g > select * from t1 where id=:v_id;
注意:這裡,我們之所以要多執行幾次,主要是因為如果只是執行一次或兩次,oracle能夠認識到你傳入的綁定變量落在了第一次的綁定變量(12462)所在的cube之外,但是oracle認為你可能只是偶爾執行該綁定變量,所以並不一定會使用另外那個全表掃描的執行計劃。多執行幾次以後,你會發現consistent gets突然從1390直線下降到了715,這時就說明oracle開始使用新的全表掃描的執行計劃了。
然後,這時我們再去查看v$sql裡該sql語句有幾條記錄。
hr@ora11g > select sql_text,sql_id,child_number,plan_hash_value 2 from v$sql where sql_text like 'select * from t1 where%'; SQL_TEXT SQL_ID CHILD_NUMBER PLAN_HASH_VALUE --------------------------------- ------------- ------------ ---------------- select * from t1 where id=:v_id 7y7tt6xyhas1g 0 50753647 select * from t1 where id=:v_id 7y7tt6xyhas1g 1 3617692013
我們發現,該SQL語句在內存裡存在兩條記錄了,也就是存在兩個子游標了,分別對應了不同的執行計劃。同樣,我們來看一下新產生的子游標,也就是child_number為1的執行計劃是怎樣的。
SQL> select * from table(dbms_xplan.display_cursor('7y7tt6xyhas1g',1));
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
SQL_ID 7y7tt6xyhas1g, child number 1
-------------------------------------
select * from t1 where id=:v_id
Plan hash value: 3617692013
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 16 (100) | |
|* 1 | TABLE ACCESS FULL| T1 | 9974 | 204K | 16 (0) | 00:00:01 |
......
我們還可以從另外的角度來驗證11g裡的動態綁定變量窺視,也就是設置sql_trace的方式。這個方式比較簡單,只要先發出:alter session set sql_trace=true以後,傳入兩個不同的綁定變量,然後分別就不同的綁定變量多執行幾次。最後調用tkprof對跟蹤文件進行分析。這裡注意兩個地方,第一是跟蹤文件位於ADR中,不再位於user_dump_dest參數所指定的目錄裡了。就這裡的跟蹤文件而言,其所在位置缺省為:$ORACLE_HOME/diag/rdbms/<DB name>/<SID>/trace目錄下;第二個要注意的是使用tkprof時,添加aggregate=no選項,缺省會將相同SQL語句合並,這樣你就發現不到對於相同SQL語句的不同的執行計劃了。
這裡節選部分使用tkprof得到的文件內容,如下所示。
...... SQL ID : 7y7tt6xyhas1g select * from t1 where id=:v_id ...... Rows Row Source Operation ------- --------------------------------------------------- 10000 TABLE ACCESS BY INDEX ROWID T1 (cr=1390 pr=0 pw=0 time=446 us cost=2 size=21 card=1) 10000 INDEX RANGE SCAN IDX_T1 (cr=687 pr=0 pw=0 time=228 us cost=1 size=0 card=1)(object id 12463) ...... SQL ID : 7y7tt6xyhas1g select * from t1 where id=:v_id ...... Rows Row Source Operation ------- --------------------------------------------------- 10000 TABLE ACCESS FULL T1 (cr=715 pr=0 pw=0 time=142 us cost=16 size=209454 card=9974) ......
從這裡也可以很清楚的看到,對於不同的綁定變量,oracle能夠自行選擇是否應該生成更好的執行計劃並使用該執行計劃。