作為一個DBA,排除SQL Server問題是我們的職責之一,每個月都有很多人給我們帶來各種不能解釋卻要解決的性能問題。
我就多次聽到,以前的SQL Server的性能問題都還好且在正常范圍內,但現在一切已經改變,SQL Server開始糟糕, 瘋狂的事情不能解釋。在這個情況下我介入,分析下整個SQL Server的安裝,最後用一些神奇的調查方法找出性能問題的根源。
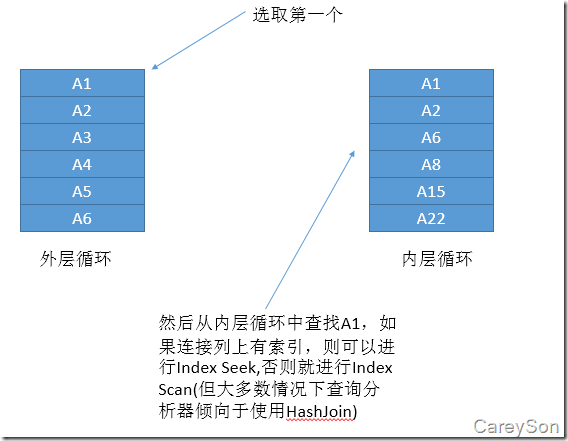
但很多時候問題的根源是一樣的:所謂的計劃回歸(Plan Regression),即特定查詢的執行計劃已經改變。昨天SQL Server已經緩存了在計劃緩存裡緩存了一個好的執行計劃,今天就生成、緩存最後重用了一個糟糕的執行計劃——不斷重復。
進入SQL Server 2016後,我就變得有點多余了,以為微軟引進了查詢存儲(Query Store)。這是這個版本最熱門的功能!查詢存儲幫助你很容易找出你的性能問題是不是計劃回歸造成的。如果你找到了計劃回歸,這很容易強制一個特定計劃不使用計劃向導。聽起來很有意思?讓我們通過一個特定的場景,向你展示下在SQL Server 2016裡,如何使用查詢存儲來找出並最終修正計劃回歸。
查詢存儲(Query Store)——我的對手
在SQL Server 2016裡,在你使用查詢存儲功能前,你要對這個數據庫啟用它。這是通過ALTER DATABASE語句實現,如你所見的下列代碼:
CREATE DATABASE QueryStoreDemo GO USE QueryStoreDemo GO -- Enable the Query Store for our database ALTER DATABASE QueryStoreDemo SET QUERY_STORE = ON GO -- Configure the Query Store ALTER DATABASE QueryStoreDemo SET QUERY_STORE ( OPERATION_MODE = READ_WRITE, CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 367), DATA_FLUSH_INTERVAL_SECONDS = 900, INTERVAL_LENGTH_MINUTES = 1, MAX_STORAGE_SIZE_MB = 100, QUERY_CAPTURE_MODE = ALL, SIZE_BASED_CLEANUP_MODE = OFF ) GO
在線幫助為你提供了各個選項的詳細信息。接下來我創建一個簡單的表,創建一個非聚集索引,最後插入80000條記錄。
-- Create a new table CREATE TABLE Customers ( CustomerID INT NOT NULL PRIMARY KEY CLUSTERED, CustomerName CHAR(10) NOT NULL, CustomerAddress CHAR(10) NOT NULL, Comments CHAR(5) NOT NULL, Value INT NOT NULL ) GO -- Create a supporting new Non-Clustered Index. CREATE UNIQUE NONCLUSTERED INDEX idx_Test ON Customers(Value) GO -- Insert 80000 records DECLARE @i INT = 1 WHILE (@i <= 80000) BEGIN INSERT INTO Customers VALUES ( @i, CAST(@i AS CHAR(10)), CAST(@i AS CHAR(10)), CAST(@i AS CHAR(5)), @i ) SET @i += 1 END GO
為了訪問我們的表,我額創建了一個簡單的存儲過程,傳入value值作為過濾謂語。
-- Create a simple stored procedure to retrieve the data CREATE PROCEDURE RetrieveCustomers ( @Value INT ) AS BEGIN SELECT * FROM Customers WHERE Value < @Value END GO
現在我用80000的參數值來執行存儲過程。
-- Execute the stored procedure. -- This generates an execution plan with a Key Lookup (Clustered). EXEC RetrieveCustomers 80000 GO
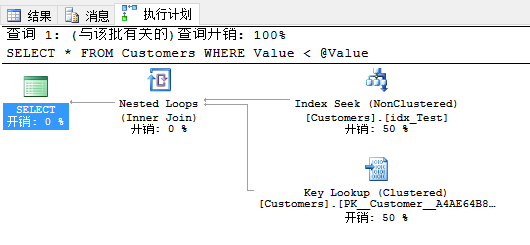
現在當你查看實際的執行計劃時,你會看到查詢優化器已經選擇了有419個邏輯讀的聚集索引掃描運算符。SQL Server並沒有使用非聚集索引,因為這樣沒有意義,由於臨界點。這個查詢結果並沒有選擇性。
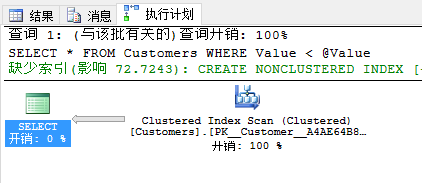
現在假設SQL Server發生了些事情(例如重啟,故障轉移),SQL Server忽略已經緩存的計劃,這裡我通過執行DBCC FREEPROCCACHE從計劃緩存裡抹掉每個緩存的計劃來模擬SQL Server重啟(不要在生產環境裡使用!)。
-- Get rid of the cached execution plan... DBCC FREEPROCCACHE GO
現在有人再次調用你的存儲過程,這次輸入參數值是1。這次執行計劃不一樣,因為現在在執行計劃裡你會有書簽查找。SQL Server估計行數是1,在非聚集索引裡沒有找到任何行。因此與非聚集索引查找結合的書簽查找才有意義,因為這個查詢是有選擇性的。
現在我再執行用80000參數值的查詢。
-- Execute the stored procedure EXEC RetrieveCustomers 1 GO -- Execute the stored procedure again -- This introduces now a plan regression, because now we get a Clustered Index Scan -- instead of the Key Lookup (Clustered). EXEC RetrieveCustomers 80000 GO
當你再次看STATISTICS IO的輸出,你會看到這個查詢現在產生了160139個邏輯讀——剛才的查詢只有419個邏輯讀。這個時候DBA的手機就會響起,性能問題。但今天我們要不同的方式解決——使用剛才啟用的查詢存儲。
當你再次看實際的執行計劃,在你面前你會看到有一個計劃回歸,因為SQL Server剛重用了書簽查找的的計劃緩存。剛才你有聚集索引掃描運算符的執行計劃。這是SQL Server裡參數嗅探的副作用。
讓我們通過查詢存儲來詳細了解這個問題。在SSMS裡的對象資源管理器裡,SQL Server 2016提供了一個新的結點叫查詢存儲,這裡你會看到一些報表。
【前幾個資源使用查詢】向你展示了最昂貴的查詢,基於你選擇的維度。這裡切換到【邏輯讀取次數】。
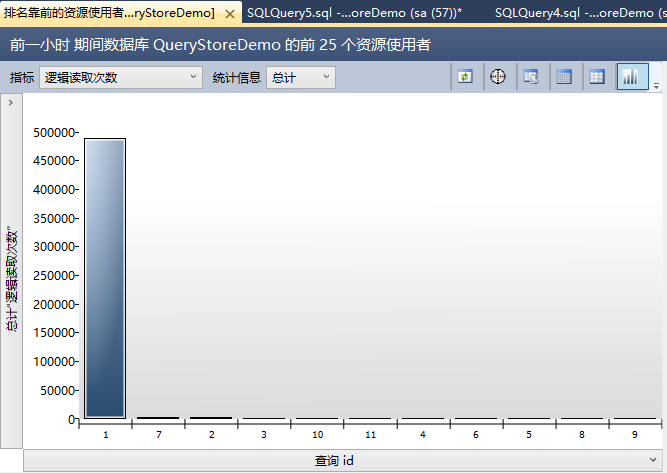
這裡在你面前有一些查詢。最昂貴的查詢生成了近500000個邏輯讀。這是我們的初始語句。這已經是第一個WOW效果的的查詢存儲:SQL Server重啟後,查詢存儲的數據還是存在的!第2個是你存儲過程裡的SELECT語句。在查詢存儲裡每個捕獲的查詢都有一個標示號——這裡是7。最後當你看報告的右邊,你會看這個查詢的不同執行計劃。
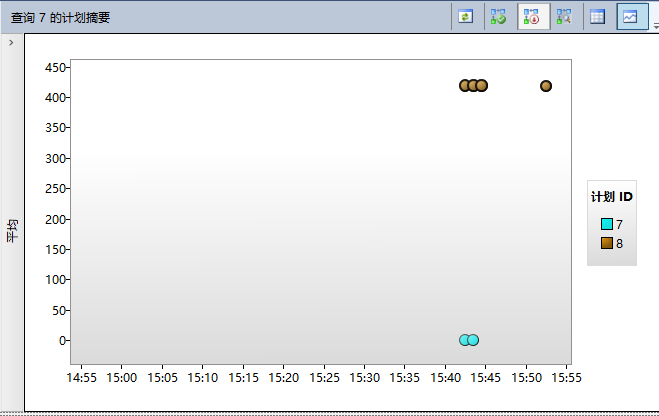
如你所見,查詢存儲捕獲了2個不同的執行計劃,一個ID是7,一個ID是8。當你點擊計劃ID時,SQL Server會在報表的最下面為你顯示估計的執行計劃。
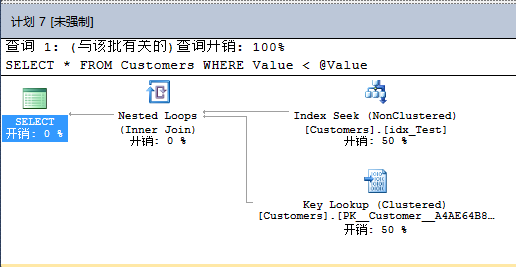
計劃8是聚集索引掃描,計劃7是書簽查找。如你所見,使用查詢存儲分析計劃回歸非常簡單。但你現在還沒結束。你現在可以對指定的查詢強制執行計劃。 現在你知道包含聚集索引掃描的執行計劃有更好的性能。因此現在你可以通過點擊【強制執行計劃】強制查詢7使用執行計劃。

搞定,我們已經解決問題了!
現在當你執行存儲過程(用80000的輸入參數值),在執行計劃裡你可以看到聚集索引掃描,執行計劃只生成419個邏輯讀——很簡單,是不是?絕對不是!!!!
微軟告訴我們只給修正SQL Server性能相關的“新方式”。你只是強制了特定的計劃,一切都還好。這個方法有個大的問題,因為性能問題的根源並沒有解決!這個問題的關鍵是因為書簽查找計劃沒有穩定性。取決於首次執行計劃默認的輸入值,執行計劃因此就被不斷重用。
通常我會建議調整下你的索引設計,創建一個覆蓋索引來保證計劃的穩定性。但強制特定執行計劃只是臨時解決問題——你還是要修正你問題的根源。
小結
不要誤解我:SQL Server 2016裡的查詢存儲功能很棒,可以幫你更容易理解計劃回歸。它也會幫你“臨時”強制特定的執行計劃。但性能調優的目標還是一樣:你要找到問題根源,嘗試解決問題——不要在外面晃蕩!