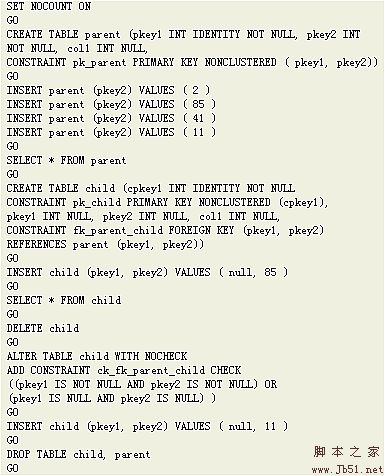
在SQL Server中,我們所常見的表與表之間的Inner Join,Outer Join都會被執行引擎根據所選的列,數據上是否有索引,所選數據的選擇性轉化為Loop Join,Merge Join,Hash Join這三種物理連接中的一種。理解這三種物理連接是理解在表連接時解決性能問題的基礎,下面我來對這三種連接的原理,適用場景進行描述。
嵌套循環連接(Nested Loop Join)
循環嵌套連接是最基本的連接,正如其名所示那樣,需要進行循環嵌套,嵌套循環是三種方式中唯一支持不等式連接的方式,這種連接方式的過程可以簡單的用下圖展示: 
圖1.循環嵌套連接的第一步

圖2.循環嵌套連接的第二步
由上面兩個圖不難看出,循環嵌套連接查找內部循環表的次數等於外部循環的行數,當外部循環沒有更多的行時,循環嵌套結束。另外,還可以看出,這種連接方式需要內部循環的表有序(也就是有索引),並且外部循環表的行數要小於內部循環的行數,否則查詢分析器就更傾向於Hash Join(會在本文後面講到)。通過嵌套循環連接也可以看出,隨著數據量的增長這種方式對性能的消耗將呈現出指數級別的增長,所以數據量到一定程度時,查詢分析器往往就會采用這種方式。
下面我們通過例子來看一下循環嵌套連接,利用微軟的AdventureWorks數據庫:

圖3.一個簡單的嵌套循環連接
圖3中ProductID是有索引的,並且在循環的外部表中(Product表)符合ProductID=870的行有4688條,因此,對應的SalesOrderDetail表需要查找4688次。讓我們在上面的查詢中再考慮另外一個例子,如圖4所示。

圖4.額外的列帶來的額外的書簽查找
由圖4中可以看出,由於多選擇了一個UnitPrice列,導致了連接的索引無法覆蓋所求查詢,必須通過書簽查找來進行,這也是為什麼我們要養成只Select需要的列的好習慣,為了解決上面的問題,我們既可以用覆蓋索引,也可以減少所需的列來避免書簽查找。另外,上面符合ProductID的行僅僅只有5條,所以查詢分析器會選擇書簽查找,假如我們將符合條件的行進行增大,查詢分析器會傾向於表掃描(通常來說達到表中行數的1%以上往往就會進行table scan而不是書簽查找,但這並不絕對),如圖5所示。

圖5.查詢分析器選擇了表掃描
可以看出,查詢分析器此時選擇了表掃描來進行連接,這種方式效率要低下很多,因此好的覆蓋索引和Select *都是需要注意的地方。另外,上面情況即使涉及到表掃描,依然是比較理想的情況,更糟糕的情況是使用多個不等式作為連接時,查詢分析器即使知道每一個列的統計分布,但卻不知道幾個條件的聯合分布,從而產生錯誤的執行計劃,如圖6所示。

圖6.由於無法預估聯合分布,導致的偏差
由圖6中,我們可以看出,估計的行數和實際的行數存在巨大的偏差,從而應該使用表掃描但查詢分析器選擇了書簽查找,這種情況對性能的影響將會比表掃描更加巨大。具體大到什麼程度呢?我們可以通過強制表掃描和查詢分析器的默認計劃進行比對,如圖7所示。

圖7.強制表掃描性能反而更好
合並連接(Merge Join)
談到合並連接,我突然想起在西雅圖參加SQL Pass峰會晚上酒吧排隊點酒,由於我和另外一哥們站錯了位置,貌似我們兩個在插隊一樣,我趕緊說:I'm sorry,i thought here is end of line。對方無不幽默的說:”It's OK,In SQL Server,We called it merge join”。
由上面的小故事不難看出,Merge Join其實上就是將兩個有序隊列進行連接,需要兩端都已經有序,所以不必像Loop Join那樣不斷的查找循環內部的表。其次,Merge Join需要表連接條件中至少有一個等號查詢分析器才會去選擇Merge Join。
Merge Join的過程我們可以簡單用下面圖進行描述:

圖8.Merge Join第一步
Merge Join首先從兩個輸入集合中各取第一行,如果匹配,則返回匹配行。加入兩行不匹配,則有較小值的輸入集合+1,如圖9所示。
圖9.更小值的輸入集合向下進1
用C#代碼表示Merge Join的話如代碼1所示。
復制代碼 代碼如下:因此,通常來說Merge Join如果輸入兩端有序,則Merge Join效率會非常高,但是如果需要使用顯式Sort來保證有序實現Merge Join的話,那麼Hash Join將會是效率更高的選擇。但是也有一種例外,那就是查詢中存在order by,group by,distinct等可能導致查詢分析器不得不進行顯式排序,那麼對於查詢分析器來說,反正都已經進行顯式Sort了,何不一石二鳥的直接利用Sort後的結果進行成本更小的MERGE JOIN?在這種情況下,Merge Join將會是更好的選擇。
另外,我們可以由Merge Join的原理看出,當連接條件為不等式(但不包括!=),比如說> < >=等方式時,Merge Join有著更好的效率。
下面我們來看一個簡單的Merge Join,這個Merge Join是由聚集索引和非聚集索引來保證Merge Join的兩端有序,如圖10所示。

圖10.由聚集索引和非聚集索引保證輸入兩端有序
當然,當Order By,Group By時查詢分析器不得不用顯式Sort,從而可以一箭雙雕時,也會選擇Merge Join而不是Hash Join,如圖11所示。

圖11.一箭雙雕的Merge Join
哈希匹配(Hash Join)哈希匹配連接相對前面兩種方式更加復雜一些,但是哈希匹配對於大量數據,並且無序的情況下性能均好於Merge Join和Loop Join。對於連接列沒有排序的情況下(也就是沒有索引),查詢分析器會傾向於使用Hash Join。
哈希匹配分為兩個階段,分別為生成和探測階段,首先是生成階段,第一階段生成階段具體的過程可以如圖12所示。

圖12.哈希匹配的第一階段
圖12中,將輸入源中的每一個條目經過散列函數的計算都放到不同的Hash Bucket中,其中Hash Function的選擇和Hash Bucket的數量都是黑盒,微軟並沒有公布具體的算法,但我相信已經是非常好的算法了。另外在Hash Bucket之內的條目是無序的。通常來講,查詢優化器都會使用連接兩端中比較小的哪個輸入集來作為第一階段的輸入源。
接下來是探測階段,對於另一個輸入集合,同樣針對每一行進行散列函數,確定其所應在的Hash Bucket,在針對這行和對應Hash Bucket中的每一行進行匹配,如果匹配則返回對應的行。
通過了解哈希匹配的原理不難看出,哈希匹配涉及到散列函數,所以對CPU的消耗會非常高,此外,在Hash Bucket中的行是無序的,所以輸出結果也是無序的。圖13是一個典型的哈希匹配,其中查詢分析器使用了表數據量比較小的Product表作為生成,而使用數據量大的SalesOrderDetail表作為探測。

圖13.一個典型的哈希匹配連接
上面的情況都是內存可以容納下生成階段所需的內存,如果內存吃緊,則還會涉及到Grace哈希匹配和遞歸哈希匹配,這就可能會用到TempDB從而吃掉大量的IO。這裡就不細說了,有興趣的同學可以移步:http://msdn.microsoft.com/zh-cn/library/aa178403(v=SQL.80).aspx。