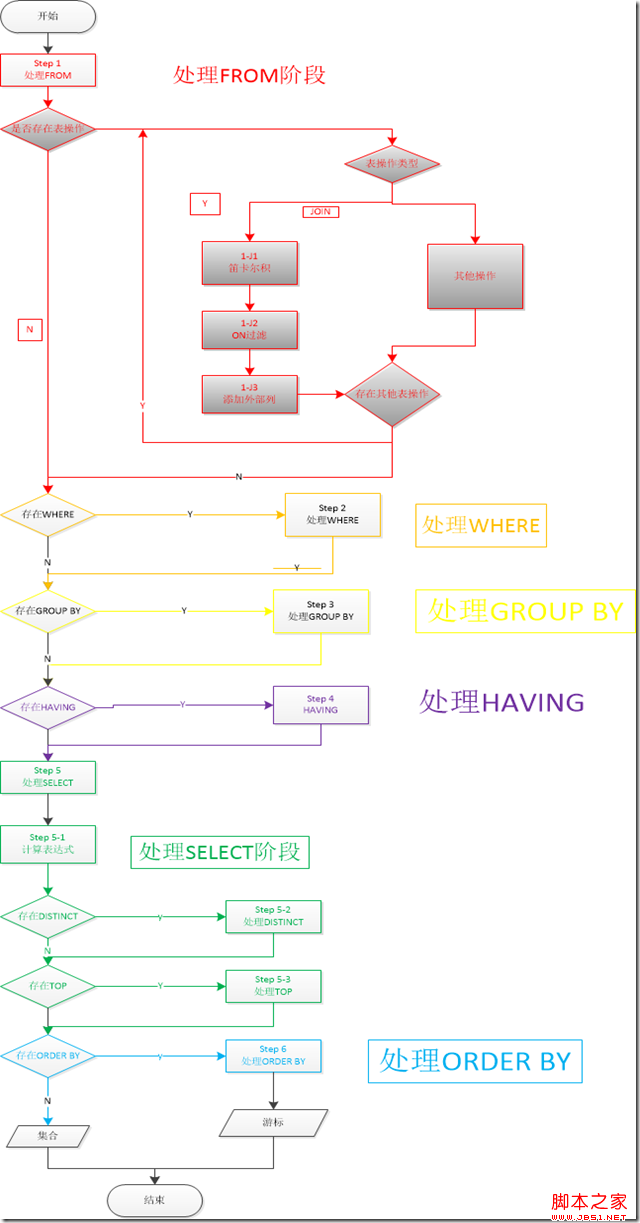
鎖機制
NOLOCK和READPAST的區別。
1. 開啟一個事務執行插入數據的操作。
BEGIN TRAN t INSERT INTO Customer SELECT 'a','a'
2. 執行一條查詢語句。
SELECT * FROM Customer WITH (NOLOCK)
結果中顯示”a”和”a”。當1中事務回滾後,那麼a將成為髒數據。(注:1中的事務未提交) 。NOLOCK表明沒有對數據表添加共享鎖以阻止其它事務對數據表數據的修改。
SELECT * FROM Customer
這條語句將一直死鎖,直到排他鎖解除或者鎖超時為止。(注:設置鎖超時SET LOCK_TIMEOUT 1800)
SELECT * FROM Customer WITH (READPAST)
這條語句將顯示a未提交前的狀態,但不鎖定整個表。這個提示指明數據庫引擎返回結果時忽略加鎖的行或數據頁。
3. 執行一條插入語句。
BEGIN TRAN t INSERT INTO Customer SELECT 'b','b' COMMIT TRAN t
這個時候,即使步驟1的事務回滾,那麼a這條數據將丟失,而b繼續插入數據庫中。
NOLOCK
1. 執行如下語句。
BEGIN TRAN ttt SELECT * FROM Customer WITH (NOLOCK) WAITFOR delay '00:00:20' COMMIT TRAN ttt
注:NOLOCK不加任何鎖,可以增刪查改而不鎖定。
INSERT INTO Customer SELECT 'a','b' –不鎖定 DELETE Customer where ID=1 –不鎖定 SELECT * FROM Customer –不鎖定 UPDATE Customer SET Title='aa' WHERE ID=1 –不鎖定
ROWLOCK
1. 執行一條帶行鎖的查詢語句。
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ -- (必須) BEGIN TRAN ttt SELECT * FROM Customer WITH (ROWLOCK) WHERE ID=17 WAITFOR delay '00:00:20' COMMIT TRAN ttt
注:在刪除和更新正在查詢的數據時,會鎖定數據。對其他未查詢的行和增加,查詢數據無影響。
INSERT INTO Customer SELECT 'a','b' –不等待 DELETE Customer where ID=17 –等待 DELETE Customer where ID<>17 –不等待 SELECT * FROM Customer –不等待 UPDATE Customer SET Title='aa' WHERE ID=17–等待 UPDATE Customer SET Title='aa' WHERE ID<>17–不等待
HOLDLOCK,TABLOCK和TABLOCKX
1. 執行HOLDLOCK
BEGIN TRAN ttt SELECT * FROM Customer WITH (HOLDLOCK) WAITFOR delay '00:00:10' COMMIT TRAN ttt
注:其他事務可以讀取表,但不能更新刪除
update Customer set Title='aa' —要等待10秒中。
SELECT * FROM Customer —不需要等待
2. 執行TABLOCKX
BEGIN TRAN ttt SELECT * FROM Customer WITH (TABLOCKX) WAITFOR delay '00:00:10' COMMIT TRAN ttt
注:其他事務不能讀取表,更新和刪除
update Customer set Title='aa' —要等待10秒中。
SELECT * FROM Customer —要等待10秒中。
3. 執行TABLOCK
BEGIN TRAN ttt SELECT * FROM Customer WITH (TABLOCK) WAITFOR delay '00:00:10' COMMIT TRAN ttt
注:其他事務可以讀取表,但不能更新刪除
update Customer set Title='aa' —要等待10秒中。
SELECT * FROM Customer —不需要等待
UDPLOCK
1. 在A連接中執行。
BEGIN TRAN ttt SELECT * FROM Customer WITH (UPDLOCK) WAITFOR delay '00:00:10' COMMIT TRAN ttt
2. 在其他連接中執行。
update Customer set Title='aa' where ID=1—要等10秒
SELECT * FROM Customer –不用等
insert into Customer select 'a','b'–不用等
注:對於UDPLOCK鎖,只對更新數據鎖定。
注:使用這些選項將使系統忽略原先在SET語句設定的事務隔離級別(SET Transaction Isolation Level)。
事務隔離級別
髒讀:READ UNCOMMITTED
髒讀就是指當一個事務正在訪問數據,並且對數據進行了修改,而這種修改還沒有提交到數據庫中,這時,另外一個事務也訪問這個數據,然後使用了這個數據。因為這個數據是還沒有提交的數據,那麼另外一個事務讀到的這個數據是髒數據,依據髒數據所做的操作可能是不正確的。
1. 在A連接中執行。
BEGIN TRAN t INSERT INTO Customer SELECT '123','123' WAITFOR delay '00:00:20' COMMIT TRAN t
2. 在B連接中執行。
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED SELECT * FROM Customer
這個時候,未提交的數據會'123'會顯示出來,當A事務回滾時就導致了髒數據。相當於(NOLOCK)
提交讀:READ COMMITTED
1. 在A連接中執行。
BEGIN TRAN t INSERT INTO Customer SELECT '123','123' WAITFOR delay '00:00:20' COMMIT TRAN t
2. 在B連接中執行。
SET TRANSACTION ISOLATION LEVEL READ COMMITTED SELECT * FROM Customer
這個時候,未提交的數據會'123'不會顯示出來,當A事務提交以後B中才能讀取到數據。避免了髒讀。
不可重復讀:REPEATABLE READ
不可重復讀是指在一個事務內,多次讀同一數據。在這個事務還沒有結束時,另外一個事務也訪問該同一數據。那麼,在第一個事務中的兩次讀數據之間,由於第二個事務的修改,那麼第一個事務兩次讀到的數據可能是不一樣的。這樣就發生了在一個事務內兩次讀到的數據是不一樣的,因此稱為是不可重復讀。
例如:
1. 在A連接中執行如下語句。
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ BEGIN TRAN ttt SELECT * FROM Customer WHERE ID=17 WAITFOR delay '00:00:30' SELECT * FROM Customer WHERE ID=17 COMMIT TRAN ttt
2. 在B連接中執行如下語句,而且要在第一個事物的三十秒等待內。
UPDATE Customer SET Title='d' WHERE ID=17
這個時候,此連接將鎖住不能執行,一直等到A連接結束為止。而且A連接中兩次讀取到的數據相同,不受B連接干擾。
注,對於Read Committed和Read UnCommitted情況下,B連接不會鎖住,等到A連接執行完以後,兩條查詢語句結果不同,即第二條查詢的Title變成了d。
序列化讀:SERIALIZABLE
1. 在A連接中執行。
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE BEGIN TRAN t UPDATE Customer SET Title='111' WAITFOR delay '00:00:20' COMMIT TRAN t
2. 在B連接中執行,並且要在A執行後的20秒內。
BEGIN TRAN tt INSERT INTO Customer SELECT '2','2' COMMIT TRAN tt
在A連接的事務提交之前,B連接無法插入數據到表中,這就避免了幻覺讀。
注:幻覺讀是指當事務不是獨立執行時發生的一種現象,例如 第一個事務對一個表中的數據進行了修改,這種修改涉及到表中的全部數據行。同時,第二個事務也修改這個表中的數據,這種修改是向表中插入一行新數據。那麼,以後就會發生操作第一個事務的用戶發現表中還有沒有修改的數據行,就好像發生了幻覺一樣。
共享鎖
共享鎖(S 鎖)允許並發事務在封閉式並發控制(請參閱並發控制的類型)下讀取 (SELECT) 資源。資源上存在共享鎖(S 鎖)時,任何其他事務都不能修改數據。讀取操作一完成,就立即釋放資源上的共享鎖(S 鎖),除非將事務隔離級別設置為可重復讀或更高級別,或者在事務持續時間內用鎖定提示保留共享鎖(S 鎖)。
更新鎖
更新鎖(U 鎖)可以防止常見的死鎖。在可重復讀或可序列化事務中,此事務讀取數據 [獲取資源(頁或行)的共享鎖(S 鎖)],然後修改數據 [此操作要求鎖轉換為排他鎖(X 鎖)]。如果兩個事務獲得了資源上的共享模式鎖,然後試圖同時更新數據,則一個事務嘗試將鎖轉換為排他鎖(X 鎖)。共享模式到排他鎖的轉換必須等待一段時間,因為一個事務的排他鎖與其他事務的共享模式鎖不兼容;發生鎖等待。第二個事務試圖獲取排他鎖(X 鎖)以進行更新。由於兩個事務都要轉換為排他鎖(X 鎖),並且每個事務都等待另一個事務釋放共享模式鎖,因此發生死鎖。
若要避免這種潛在的死鎖問題,請使用更新鎖(U 鎖)。一次只有一個事務可以獲得資源的更新鎖(U 鎖)。如果事務修改資源,則更新鎖(U 鎖)轉換為排他鎖(X 鎖)。
排他鎖
排他鎖(X 鎖)可以防止並發事務對資源進行訪問。使用排他鎖(X 鎖)時,任何其他事務都無法修改數據;僅在使用 NOLOCK 提示或未提交讀隔離級別時才會進行讀取操作。
數據修改語句(如 INSERT、UPDATE 和 DELETE)合並了修改和讀取操作。語句在執行所需的修改操作之前首先執行讀取操作以獲取數據。因此,數據修改語句通常請求共享鎖和排他鎖。例如,UPDATE 語句可能根據與一個表的聯接修改另一個表中的行。在此情況下,除了請求更新行上的排他鎖之外,UPDATE 語句還將請求在聯接表中讀取的行上的共享鎖。
您好!鎖是數據庫中的一個非常重要的概念,它主要用於多用戶環境下保證數據庫完整性和一致性。
我們知道,多個用戶能夠同時操縱同一個數據庫中的數據,會發生數據不一致現象。即如果沒有鎖定且多個用戶同時訪問一個數據庫,則當他們的事務同時使用相同的數據時可能會發生問題。這些問題包括:丟失更新、髒讀、不可重復讀和幻覺讀。數據庫加鎖就是為了解決以上的問題。
當然,加鎖固然好,但是一定要避免死鎖的出現。
在數據庫系統中,死鎖是指多個用戶(進程)分別鎖定了一個資源,並又試圖請求鎖定對方已經鎖定的資源,這就產生了一個鎖定請求環,導致多個用戶(進程)都處於等待對方釋放所鎖定資源的狀態。這種死鎖是最典型的死鎖形式, 例如在同一時間內有兩個事務A和B,事務A有兩個操作:鎖定表part和請求訪問表supplier;事務B也有兩個操作:鎖定表supplier和請求訪問表part。結果,事務A和事務B之間發生了死鎖。死鎖的第二種情況是,當在一個數據庫中時,有若干個長時間運行的事務執行並行的操作,當查詢分析器處理一種非常復雜的查詢例如連接查詢時,那麼由於不能控制處理的順序,有可能發生死鎖現象。
在應用程序中就可以采用下面的一些方法來盡量避免死鎖了: (1)合理安排表訪問順序。 (2)在事務中盡量避免用戶干預,盡量使一個事務處理的任務少些, 保持事務簡短並在一個批處理中。 (3)數據訪問時域離散法, 數據訪問時域離散法是指在客戶機/服務器結構中,采取各種控制手段控制對數據庫或數據庫中的對象訪問時間段。主要通過以下方式實現: 合理安排後台事務的執行時間,采用工作流對後台事務進行統一管理。工作流在管理任務時,一方面限制同一類任務的線程數(往往限制為1個),防止資源過多占用; 另一方面合理安排不同任務執行時序、時間,盡量避免多個後台任務同時執行,另外, 避免在前台交易高峰時間運行後台任務。 (4)數據存儲空間離散法。數據存儲空間離散法是指采取各種手段,將邏輯上在一個表中的數據分散到若干離散的空間上去,以便改善對表的訪問性能。主要通過以下方法實現: 第一,將大表按行或列分解為若干小表; 第二,按不同的用戶群分解。 (5)使用盡可能低的隔離性級別。隔離性級別是指為保證數據庫數據的完整性和一致性而使多用戶事務隔離的程度,SQL92定義了4種隔離性級別:未提交讀、提交讀、可重復讀和可串行。如果選擇過高的隔離性級別,如可串行,雖然系統可以因實現更好隔離性而更大程度上保證數據的完整性和一致性,但各事務間沖突而死鎖的機會大大增加,大大影響了系統性能。 (6)使用綁定連接, 綁定連接允許兩個或多個事務連接共享事務和鎖,而且任何一個事務連接要申請鎖如同另外一個事務要申請鎖一樣,因此可以允許這些事務共享數據而不會有加鎖的沖突。
總之,了解SQL Server的鎖機制,掌握數據庫鎖定方法, 對一個合格的DBA來說是很重要的。
你開兩個進程(比如同一個工具開兩個)
設置 不自動提交。
一個程序對同一個表進行操作,另一個 程序 去讀取數據
就可以看出區別。
這個你搜索一下,應該有現成的例子。