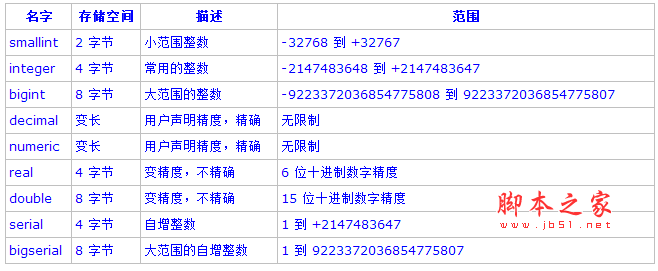
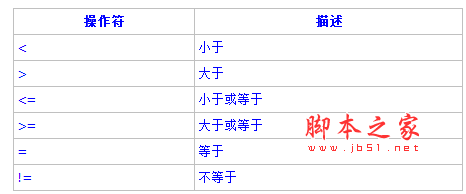
七、pg_dump:
pg_dump是一個用於備份PostgreSQL數據庫的工具。它甚至可以在數據庫正在並發使用時進行完整一致的備份,而不會阻塞其它用戶對數據庫的訪問。該工具生成的轉儲格式可以分為兩種,腳本和歸檔文件。其中腳本格式是包含許多SQL命令的純文本格式,這些SQL命令可以用於重建該數據庫並將之恢復到生成此腳本時的狀態,該操作需要使用psql來完成。至於歸檔格式,如果需要重建數據庫就必須和pg_restore工具一起使用。在重建過程中,可以對恢復的對象進行選擇,甚至可以在恢復之前對需要恢復的條目進行重新排序。該命令的使用方式如下:
復制代碼 代碼如下:
pg_dump [option...] [dbname]
1. 命令行選項列表:
選項 說明 -a(--data-only) 只輸出數據,不輸出模式(數據對象的定義)。這個選項只是對純文本格式有意義。對於歸檔格式,你可以在調用pg_restore時指定選項。 -b(--blobs) 在dump中包含大對象。 -c(--clean) 在輸出創建數據庫對象的SQL命令之前,先輸出刪除該數據庫對象的SQL命令。這個選項只是對純文本格式有意義。對於歸檔格式,你可以在調用 pg_restore時指定選項。 -C(--create) 先輸出創建數據庫的命令,之後再重新連接新創建的數據庫。對於此種格式的腳本,在運行之前是和哪個數據庫進行連接就不這麼重要了。這個選項只是對純文本格式有意義。對於歸檔格式,你可以在調用pg_restore時指定選項。 -Eencoding 以指定的字符集創建該dump文件。 -ffile 輸出到指定文件,如果沒有該選項,則輸出到標准輸出。 -Fformat
p(plain): 純文本格式的SQL腳本文件(缺省)。c(custom): 輸出適合於pg_restore的自定義歸檔格式。 這是最靈活的格式,它允許對裝載的數據和對象定義進行重新排列。這個格式缺省的時候是壓縮的。t(tar): 輸出適合於pg_restore的tar歸檔文件。使用這個歸檔允許在恢復數據庫時重新排序和/或把數據庫對象排除在外。同i時也可能可以在恢復的時候限制對哪些數據進行恢復。
-n schema 只轉儲schema的內容。如果沒有聲明該選項,目標數據庫中的所有非系統模式都會被轉儲。該選項也可以被多次指定,以指定不同pattern的模式。 -Nschema 不轉儲匹配schema的內容,其他規則和-n一致。 -o(--oids) 作為數據的一部分,為每個表都輸出對象標識(OID)。 -O(--no-owner) 不輸出設置對象所有權的SQL命令。 -s(--schema-only) 只輸出對象定義(模式),不輸出數據。 -Susername 指定關閉觸發器時需要用到的超級用戶名。它只有在使用--disable-triggers的時候才有關系。 -ttable 只輸出表的數據。很可能在不同模式裡面有多個同名表,如果這樣,那麼所有匹配的表都將被轉儲。通過多次指定該參數,可以一次轉儲多張表。這裡還可以指定和psql一樣的pattern,以便匹配更多的表。(關於pattern,基本的使用方式是可以將它視為unix的通配符,即*表示任意字符,?表示任意單個字符,.(dot)表示schema和object之間的分隔符,如a*.b*,表示以a開頭的schema和以b開頭的數據庫對象。如果沒有.(dot),將只是表示數據庫對象。這裡也可以使用基本的正則表達式,如[0-9]表示數字。) -Ttable 排除指定的表,其他規則和-t選項一致。 -x(--no-privileges) 不導出訪問權限信息(grant/revoke命令)。 -Z0..9 聲明在那些支持壓縮的格式中使用的壓縮級別。 (目前只有自定義格式支持壓縮) --column-inserts 導出數據用insert into table_name(columns_list) values(values_list)命令表示,這樣的操作相對其它操作而言是比較慢的,但是在特殊情況下,如數據表字段的位置有可能發生變化或有新的字段插入到原有字段列表的中間等。由於columns_list被明確指定,因此在導入時不會出現數據被導入到錯誤字段的問題。 --inserts 導出的數據用insert命令表示,而不是copy命令。即便使用insert要比copy慢一些,但是對於今後導入到其他非PostgreSQL的數據庫是比較有意義的。 --no-tablespaces 不輸出設置表空間的命令,如果帶有這個選項,所有的對象都將恢復到執行pg_restore時的缺省表空間中。 --no-unlogged-table-data 對於不計入日志(unlogged)的數據表,不會導出它的數據,至於是否導出其Schema信息,需要依賴其他的選項而定。 -h(--host=host) 指定PostgreSQL服務器的主機名。 -p(--port=port) 指定服務器的偵聽端口,如不指定,則為缺省的5432。 -U(--username=username) 本次操作的登錄用戶名,如果-O選項沒有指定,此數據庫的Owner將為該登錄用戶。 -w(--no-password) 如果當前登錄用戶沒有密碼,可以指定該選項直接登錄。2. 應用示例:
復制代碼 代碼如下:
# -h: PostgreSQL服務器的主機為192.168.149.137。
# -U: 登錄用戶為postgres。
# -t: 導出表名以test開頭的數據表,如testtable。
# -a: 僅僅導出數據,不導出對象的schema信息。
# -f: 輸出文件是當前目錄下的my_dump.sql
# mydatabase是此次操作的目標數據庫。
/> pg_dump -h 192.168.149.137 -U postgres -t test* -a -f ./my_dump.sql mydatabase
#-c: 先輸出刪除數據庫對象的SQL命令,在輸出創建數據庫對象的SQL命令,這對於部署干淨的初始系統或是搭建測試環境都非常方便。
/> pg_dump -h 192.168.220.136 -U postgres -c -f ./my_dump.sql mydatabase
#導出mydatabase數據庫的信息。在通過psql命令導入時可以重新指定數據庫,如:/> psql -d newdb -f my_dump.sql
/> pg_dump -h 192.168.220.136 -U postgres -f ./my_dump.sql mydatabase
#導出模式為my_schema和以test開頭的數據庫對象名,但是不包括my_schema.employee_log對象。
/> pg_dump -t 'my_schema.test*' -T my_schema.employee_log mydatabase > my_dump.sql
#導出east和west模式下的所有數據庫對象。下面兩個命令是等同的,只是後者使用了正則。
/> pg_dump -n 'east' -n 'west' mydatabase -f my_dump.sql
/> pg_dump -n '(east|west)' mydatabase -f my_dump.sql
八、pg_restore:
pg_restore用於恢復pg_dump導出的任何非純文本格式的文件,它將數據庫重建成保存它時的狀態。對於歸檔格式的文件,pg_restore可以進行有選擇的恢復,甚至也可以在恢復前重新排列數據的順序。
pg_restore可以在兩種模式下操作。如果指定數據庫,歸檔將直接恢復到該數據庫。否則,必須先手工創建數據庫,之後再通過pg_restore恢復數據到該新建的數據庫中。該命令的使用方式如下:
復制代碼 代碼如下:
pg_restore [option...] [filename]
1. 命令行選項列表:
選項 說明 filename 指定要恢復的備份文件,如果沒有聲明,則使用標准輸入。 -a(--data-only) 只恢復數據,而不恢復表模式(數據對象定義)。 -c(--clean) 創建數據庫對象前先清理(刪除)它們。 -C(--create) 在恢復數據庫之前先創建它。(在使用該選項時,數據庫名需要由-d選項指定,該選項只是執行最基本的CREATE DATABASE命令。需要說明的是,歸檔文件中所有的數據都將恢復到歸檔文件裡指定的數據庫中)。 -ddbname 與數據庫dbname建立連接並且直接恢復數據到該數據庫中。 -e(--exit-on-error)
如果在向數據庫發送SQL命令的時候遇到錯誤,則退出。缺省是繼續執行並且在恢復結束時顯示一個錯誤計數。
-Fformat 指定備份文件的格式。由於pg_restore會自動判斷格式,因此指定格式並不是必須的。如果指定,它可以是以下格式之一:t(tar): 使用該格式允許在恢復數據庫時重新排序和/或把表模式信息排除出去,同時還可能在恢復時限制裝載的數據。 c(custom):該格式是來自pg_dump的自定義格式。這是最靈活的格式,因為它允許重新對數據排序,也允許重載表模式信息,缺省情況下這個格式是壓縮的。 -I index 只恢復指定的索引。 -l(--list) 列出備份中的內容,這個操作的輸出可以作為-L選項的輸入。注意,如果過濾選項-n或-t連同-l選項一起使用的話,他們也將限制列出的條目。 -L list-file 僅恢復在list-file中列出的條目,恢復的順序為各個條目在該文件中出現的順序,你也可以手工編輯該文件,並重新排列這些條目的位置,之後再進行恢復操作,其中以分號(;)開頭的行為注釋行,注釋行不會被導入。 -n namespace 僅恢復指定模式(Schema)的數據庫對象。該選項可以和-t選項聯合使用,以恢復指定的數據對象。 -O(--no-owner) 不輸出設置對象所有權的SQL命令。 -Pfunction-name(argtype [, ...])只恢復指定的命名函數。該名稱應該和轉儲的內容列表中的完全一致。
-s(--schema-only) 只恢復表結構(數據定義)。不恢復數據,序列值將重置。 -Susername 指定關閉觸發器時需要用到的超級用戶名。它只有在使用--disable-triggers的時候才有關系。 -t table 只恢復指定表的Schema和/或數據,該選項也可以連同-n選項指定模式。 -x(--no-privileges) 不恢復訪問權限信息(grant/revoke命令)。 -1(--single-transaction) 在一個單一事物中執行恢復命令。這個選項隱含包括了--exit-on-error選項。 --no-tablespaces 不輸出設置表空間的命令,如果帶有這個選項,所有的對象都將恢復到執行pg_restore時的缺省表空間中。 --no-data-for-failed-tables 缺省情況下,即使創建表失敗了,如該表已經存在,數據加載的操作也不會停止,這樣的結果就是很容易導致大量的重復數據被插入到該表中。如果帶有該選項,那麼一旦出現針對該表的任何錯誤,對該數據表的加載將被忽略。 --role=rolename 以指定的角色名執行restore的操作。通常而言,如果連接角色沒有足夠的權限用於本次恢復操作,那麼就可以利用該選項在建立連接之後再切換到有足夠權限的角色。 -h(--host=host) 指定PostgreSQL服務器的主機名。 -p(--port=port) 指定服務器的偵聽端口,如不指定,則為缺省的5432。 -U(--username=username) 本次操作的登錄用戶名,如果-O選項沒有指定,此數據庫的Owner將為該登錄用戶。 -w(--no-password) 如果當前登錄用戶沒有密碼,可以指定該選項直接登錄。 2. 應用示例:
復制代碼 代碼如下:
#先通過createdb命令,以myuser用戶的身份登錄,創建帶恢復的數據newdb
/> createdb -U myuser newdb
#用pg_restore命令的-l選項導出my_dump.dat備份文件中導出數據庫對象的明細列表。
/> pg_restore -l my_dump.dat > db.list
/> cat db.list
2; 145344 TABLE species postgres
4; 145359 TABLE nt_header postgres
6; 145402 TABLE species_records postgres
8; 145416 TABLE ss_old postgres
10; 145433 TABLE map_resolutions postgres
#將以上列表文件中的內容修改為以下形式。
#主要的修改是注釋掉編號為2、4和8的三個數據庫對象,同時編號10的對象放到該文件的頭部,這樣在基於該列表
#文件導入時,2、4和8等三個對象將不會被導入,在恢復的過程中將先導入編號為10的對象的數據,再導入對象6的數據。
/> cat new_db.list
10; 145433 TABLE map_resolutions postgres
;2; 145344 TABLE species postgres
;4; 145359 TABLE nt_header postgres
6; 145402 TABLE species_records postgres
;8; 145416 TABLE ss_old postgres
#恢復時指定的數據庫是newdb,導入哪些數據庫對象和導入順序將會按照new_db.list文件中提示的規則導入。
/> pg_restore -d newdb -L new_db.list my_dump.dat
九、psql:
PostgreSQL的交互終端,等同於Oracle中的sqlplus。
1. 常用命令行選項列表:
選項 說明 -c command 指定psql執行一條SQL命令command(用雙引號括起),執行後退出。 -d dbname 待連接的數據庫名稱。 -E 回顯由\d和其他反斜槓命令生成的實際查詢。 -f filename 使用filename文件中的數據作為命令輸入源,而不是交互式讀入查詢。在處理完文件後,psql結束並退出。 -h hostname 聲明正在運行服務器的主機名 -l 列出所有可用的數據庫,然後退出。 -L filename 除了正常的輸出源之外,把所有查詢記錄輸出到文件filename。 -o filename 將所有查詢重定向輸出到文件filename。 -p port 指定PostgreSQL服務器的監聽端口。 -q --quiet 讓psql安靜地執行所處理的任務。缺省時psql將輸出打印歡迎和許多其他信息。 -t --tuples-only 關閉打印列名稱和結果行計數腳注等信息。 -U username 以用戶username代替缺省用戶與數據庫建立連接。
2. 應用示例:
復制代碼 代碼如下:
#先通過createdb命令,以myuser用戶的身份登錄,創建帶恢復的數據newdb
/> createdb -U myuser newdb
#用pg_restore命令的-l選項導出my_dump.dat備份文件中導出數據庫對象的明細列表。
/> pg_restore -l my_dump.dat > db.list
/> cat db.list
2; 145344 TABLE species postgres
4; 145359 TABLE nt_header postgres
6; 145402 TABLE species_records postgres
8; 145416 TABLE ss_old postgres
10; 145433 TABLE map_resolutions postgres
#將以上列表文件中的內容修改為以下形式。
#主要的修改是注釋掉編號為2、4和8的三個數據庫對象,同時編號10的對象放到該文件的頭部,這樣在基於該列表
#文件導入時,2、4和8等三個對象將不會被導入,在恢復的過程中將先導入編號為10的對象的數據,再導入對象6的數據。
/> cat new_db.list
10; 145433 TABLE map_resolutions postgres
;2; 145344 TABLE species postgres
;4; 145359 TABLE nt_header postgres
6; 145402 TABLE species_records postgres
;8; 145416 TABLE ss_old postgres
#恢復時指定的數據庫是newdb,導入哪些數據庫對象和導入順序將會按照new_db.list文件中提示的規則導入。
/> pg_restore -d newdb -L new_db.list my_dump.dat
3. 內置命令列表:
psql內置命令的格式為反斜槓後面緊跟一個命令動詞,之後是任意參數。參數與命令動詞以及其他參數之間可以用空白符隔開,如果參數裡面包含空白符,該參數必須用單引號括起,如果參數內包含單引號,則需要用反斜槓進行轉義,此外單引號內的參數還支持類似C語言printf函數所支持的轉義關鍵字,如\t、\n等。
命令 說明 \a 如果目前的表輸出格式是不對齊的,切換成對齊的。如果是對齊的,則切換成不對齊。 \cd [directory] 把當前工作目錄切換到directory。沒有參數則切換到當前用戶的主目錄。 \C [title] 為查詢結果添加表頭(title),如果沒有參數則取消當前的表頭。 \c[dbname[username] ] 連接新的數據庫,同時斷開當前連接。如果dbname參數為-,表示仍然連接當前數據庫。如果忽略username,則表示繼續使用當前的用戶名。 \copy 其參數類似於SQL copy,功能則幾乎等同於SQL copy,一個重要的差別是該內置命令可以將表的內容導出到本地,或者是從本地導入到數據庫指定的表,而SQL copy則是將表中的數據導出到服務器的某個文件,或者是從服務器的文件導入到數據表。由此可見,SQL copy的效率要優於該內置命令。 \d [pattern] 顯示和pattern匹配的數據庫對象,如表、視圖、索引或者序列。顯示所有列,它們的類型,表空間(如果不是缺省的)和任何特殊屬性。 \db [pattern] 列出所有可用的表空間。如果聲明了pattern, 那麼只顯示那些匹配模式的表空間。 \db+ [pattern] 和上一個命令相比,還會新增顯示每個表空間的權限信息。 \df [pattern] 列出所有可用函數,以及它們的參數和返回的數據類型。如果聲明了pattern,那麼只顯示匹配(正則表達式)的函數。 \df+ [pattern] 和上一個命令相比,還會新增顯示每個函數的附加信息,包括語言和描述。 \distvS [pattern] 這不是一個單獨命令名稱:字母 i、s、t、v、S 分別代表索引(index)、序列(sequence)、表(table)、視圖(view)和系統表(system table)。你可以以任意順序聲明部分或者所有這些字母獲得這些對象的一個列表。 \dn [pattern] 列出所有可用模式。如果聲明了pattern,那麼只列出匹配模式的模式名。 \dn+ [pattern] 和上一個命令相比,還會新增顯示每個對象的權限和注釋。 \dp [pattern] 生成一列可用的表和它們相關的權限。如果聲明了pattern, 那麼只列出名字可以匹配模式的表。 \dT [pattern] 列出所有數據類型或只顯示那些匹配pattern的。 \du [pattern] 列出所有已配置用戶或者只列出那些匹配pattern的用戶。 \echotext [ ... ] 向標准輸出打印參數,用一個空格分隔並且最後跟著一個新行。如:\echo `date` \g[{filename ||command}] 把當前的查詢結果緩沖區的內容發送給服務器並且把查詢的輸出存儲到可選的filename或者把輸出定向到一個獨立的在執行 command的Unix shell。 \ifilename 從文件filename中讀取並把其內容當作從鍵盤輸入的那樣執行查詢。 \l 列出服務器上所有數據庫的名字和它們的所有者以及字符集編碼。 \o[{filename ||command}] 把後面的查詢結果保存到文件filename裡或者把後面的查詢結果定向到一個獨立的shell command。 \p 打印當前查詢緩沖區到標准輸出。 \q 退出psql程序。 \r 重置(清空)查詢緩沖區。 \s [filename] 將命令行歷史打印出或是存放到filename。如果省略filename,歷史將輸出到標准輸出。 \t 切換是否輸出列/字段名的信息頭和行記數腳注。 \w{filename ||command} 將當前查詢緩沖區輸出到文件filename或者定向到Unix命令command。 \z [pattern] 生成一個帶有訪問權限列表的數據庫中所有表,視圖和序列的列表。如果給出任何pattern,則被當成一個規則表達式,只顯示匹配的表,視圖和序列。 \! [command] 返回到一個獨立的Unix shell或者執行Unix命令command。參數不會被進一步解釋,shell將看到全部參數。
4. 內置命令應用示例:
在psql中,大部分的內置命令都比較易於理解,因此這裡只是給出幾個我個人認為相對容易混淆的命令。
復制代碼 代碼如下:
# \c: 其中橫線(-)表示仍然連接當前數據庫,myuser是新的用戶名。
postgres=# \c - myuser
Password for user myuser:
postgres=> SELECT user;
current_user
--------------
myuser
(1 row)
# 執行任意SQL語句。
postgres=# SELECT * FROM testtable WHERE i = 2;
i
---
2
(1 row)
# \g 命令會將上一個SQL命令的結果輸出到指定文件。
postgres=# \g my_file_for_command_g
postgres=# \! cat my_file_for_command_g
i
---
2
(1 row)
# \g 命令會將上一個SQL命令的結果從管道輸出到指定的Shell命令,如cat。
postgres=# \g | cat
i
---
2
(1 row)
# \p 打印上一個SQL命令。
postgres=# \p
SELECT * FROM testtable WHERE i = 2;
# \w 將上一個SQL命令輸出到指定的文件。
postgres=# \w my_file_for_option_w
postgres=# \! cat my_file_for_option_w
SELECT * FROM testtable WHERE i = 2;
# \o 和\g相反,該命令會將後面psql命令的輸出結果輸出到指定的文件,直到遇到下一個獨立的\o,
# 此後的命令結果將不再輸出到該文件。
postgres=# \o my_file_for_option_o
postgres=# SELECT * FROM testtable WHERE i = 1;
# 終止後面的命令結果也輸出到my_file_for_option_o文件中。
postgres=# \o
postgres=# \! cat my_file_for_option_o
i
---
1
(1 row)