簡介
在SQL Server中,數據是按頁進行存放的。而為表加上聚集索引後,SQL Server對於數據的查找就是按照聚集索引的列作為關鍵字進行了。因此對於聚集索引的選擇對性能的影響就變得十分重要了。本文從旨在從性能的角度來談聚集索引的選擇,但這僅僅是從性能方面考慮。對於有特殊業務要求的表,則需要按實際情況進行選擇。
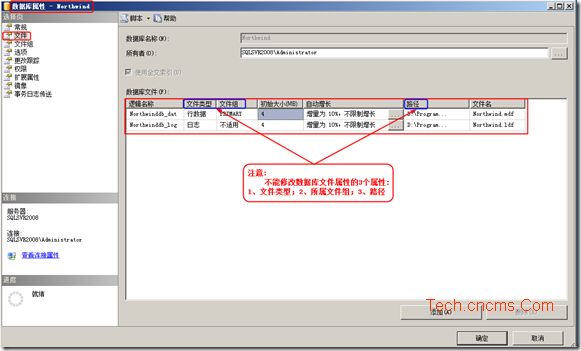
這個原因需要從數據的存放原理來談。在SQL Server中,數據的存放方式並不是以行(Row)為單位,而是以頁為單位。因此,在查找數據時,SQL Server查找的最小單位實際上是頁。也就是說即使你只查找一行很小的數據,SQL Server也會將整個頁查找出來,放到緩沖池中。
每一個頁的大小是8K。每個頁都會有一個對於SQL Server來說的物理地址。這個地址的寫法是 文件號:頁號(理解文件號需要你對文件和文件組有所了解).比如第一個文件的第50頁。則頁號為1:50。當表沒有聚集索引時,表中的數據頁是以堆(Heap)進行存放的,在頁的基礎上,SQL Server通過一個額外的行號來唯一確定每一行,這也就是傳說中的RID。RID是文件號:頁號:行號來進行表示的,假設這一行在前面所說的頁中的第5行,則RID表示為1:50:5,如圖1所示。
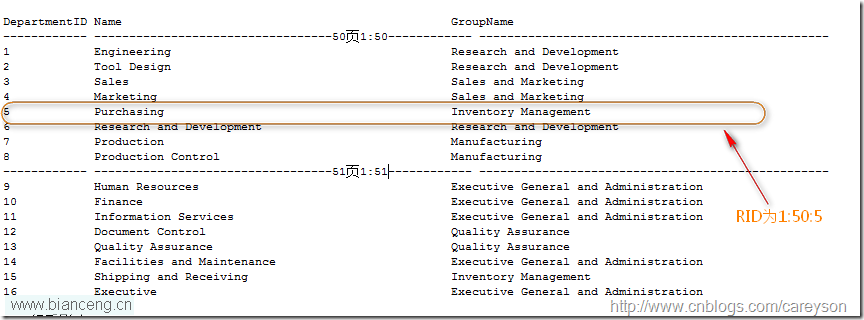
圖1.RID的示例
從RID的概念來看,RID不僅僅是SQL Server唯一確定每一行的依據,也是存放行的存放位置。當頁通過堆(Heap)進行組織時,頁很少進行移動。
而當表上建立聚集索引時,表中的頁按照B樹進行組織。此時,SQL Server尋找行不再是按RID進行查找,轉而使用了關鍵字,也就是聚集索引的列作為關鍵字進行查找。假設圖1的表中,我們設置DepartmentID列作為聚集索引列。則B樹的非葉子節點的行中只包含了DepartmentID和指向下一層節點的書簽(BookMark)。
而當我們創建的聚集索引的值不唯一時,SQL Server則無法僅僅通過聚集索引列(也就是關鍵字)唯一確定一行。此時,為了實現對每一行的唯一區分,則需要SQL Server為相同值的聚集索引列生成一個額外的標識信息進行區分,這也就是所謂的uniquifiers。而使用了uniquifier後,對性能產生的影響分為如下兩部分:
SQL Server必須在插入或者更新時對現在數據進行判斷是否和現有的鍵重復,如果重復,則需要生成uniquifier,這個是一筆額外開銷。
因為需要對相同值的鍵添加額外的uniquifier來區分,因此鍵的大小被額外的增加了。因此無論是葉子節點和非葉子節點,都需要更多的頁進行存儲。從而還影響到了非聚集索引,使得非聚集索引的書簽列變大,從而使得非聚集索引也需要更多的頁進行存儲。
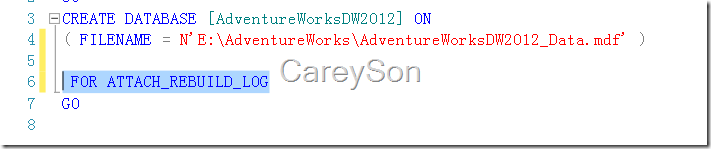
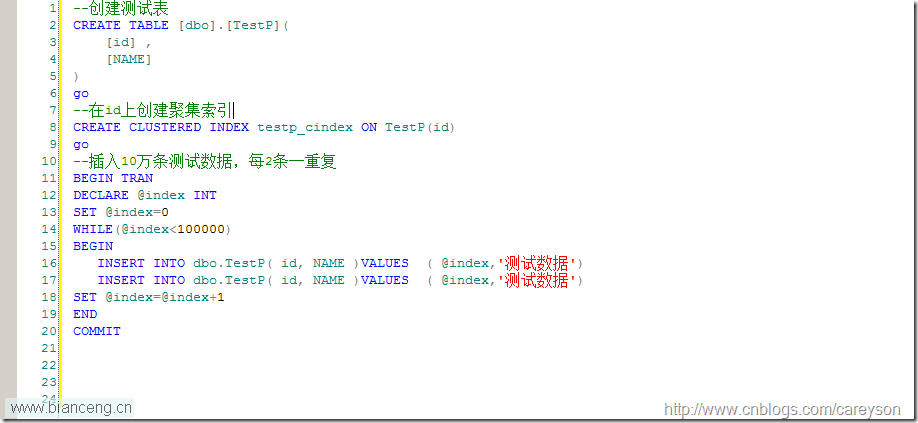
下面我們進行測試,創建一個測試表,創建聚集索引。插入10萬條測試數據,其中每2條一重復,如圖2所示。
查看本欄目
圖2.插入數據的測試代碼
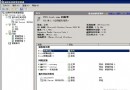
此時,我們來查看這個表所占的頁數,如圖3所示。
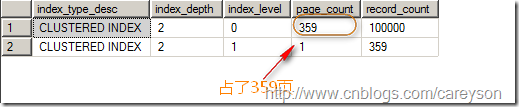
圖3.插入重復鍵後10萬數據占了359頁