在下面的五個章節中,我們比較和對比了五種使用SQL Server 2005分析服務來模型化實體的方法。我們發現,沒有一種簡單的方法能夠實現所有環境中的關系型模型化。我們發現最好根據運行時可用的存儲、所允許的計算來選擇使用的方法,從而實現更有彈性的廠商分析模型。
方法#1- 創建單獨的真實維度
我們實現的第一種方法是創建了五個真實維度(每個都對應一種廠商類型),並從Item維度表中加載。這種技術很直接,並且很容易實現。然而,它存在一些缺點。首先是它在Cube中帶來了一些額外的復雜性。終端用戶不得不多使用增加的五個維度。並且在維度存儲上也增加了五倍以上(因為每個維度完全不依賴於其它的維度)。最終要的缺點是這種技術不可能實現交叉的廠商分析。例如,考慮“Abrams, Harry N., Inc.”這個廠商。因為Abrams有五個成員,因此無法通過廠商直接的來分離,除非你假定,Abrams在五個維度中都有相同的拼寫,並且確保在所有五個維度中都選中這個相同的切片。
方法#2 – 使用屬性層次來代替物理維度
這個方法相比於前面的方法,使得貨品和廠商之間的關系更加密切。在這種方法中,我們去掉了第一種方法中使用的物理維度,而是在Item維度上添加了五個屬性或者用戶定義的層次。這五個新的Item層次是:Item.Return Vendor,Item.Purchase Vendor,Item.Original Purchase Vendor,Item.Source Vendor和Item.DC Vendor。使用這種方法,有以下幾個優點。首先,因為五個屬性是從一個屬性鍵下構建的,因此只需要一個存儲位置。第二,因為我們將五個維度轉換成五個屬性層次(或者用戶定義層次),因此這降低了最終Cube的復雜度(維度)。對於一些終端用戶,這點很重要,這能使得他們在Cube之間導航更加簡單。然而,這種方法也不允許覆蓋多個廠商的分析。
方法#3 – 為Vendor和Vendor類型創建多對多的維度
第三個方法是在三個維度(Item, Vendor和 Vendor Type.)之間創建一個多對多的維度,這是一個不常用的方法,這會帶來大量的成本。Item維度並沒有任何變化。Vendor維度需要在五中類型的廠商上將所有可能的廠商合並(並去除重復的項)。最後,Vendor Type已經有五個成員,分別為Return、Purchase、Original Purchase、Source和DC服務。一旦維度就緒後,就創建一個度量組,用來表示每個Item和它的五中類型。度量組看上去的效果如圖21所示。
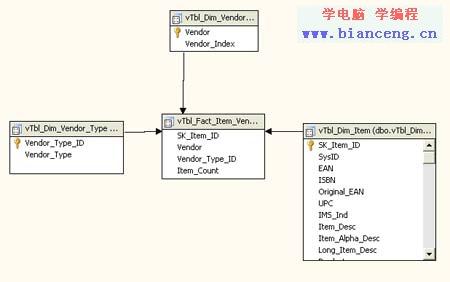
圖21:一個在Item、Vendor、Vendor Type維度表之間多對多的維度
如同你看到的一樣,這個度量組確實非常大。在完整的維度中,我們會有超過六百萬個項貨品,每項有五種類型,以及約4萬個廠商。這意味著,在這個多對多的度量(在Cube設計中被稱為Item Vendor)組中,我們會有超過3千萬項記錄。
這個方法的主要缺點是為了完成對廠商的分析,你必須構建一個在正被分析的分割表數據之間的百萬對百萬級別的交叉連接和一個多對多的度量組(也包含幾百萬條記錄)。這意味著,在第二種方法中只需要幾秒的查詢,在這種方法中會慢上許多(例如幾十妙)。但是,這種方法也帶來了巨大的好處。現在,你可以用一個獨立的成員表示一個成員。這能夠讓成員更容易被區分,並能夠直接的比較。如圖22所示。
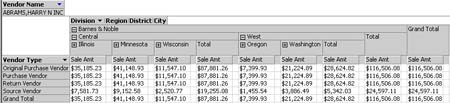
圖22:通過Vendor Type查找一個Vendor的銷售情況
這在其它技術中是不可能實現的,除非你手工的把五個切片設置成相同的值。