開始
這是去年的問題了,今天在整理郵件的時候才發現這個問題,感覺頂有意思的,特記錄下來。
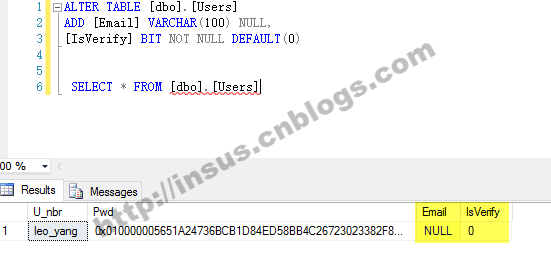
在表RelationGraph中,有三個字段(ID,Node,RelatedNode),其中Node和RelatedNode兩個字段描述兩個節點的連接關系;現在要求,找出從節點"p"至節點"j",最短路徑(即經過的節點最少)。
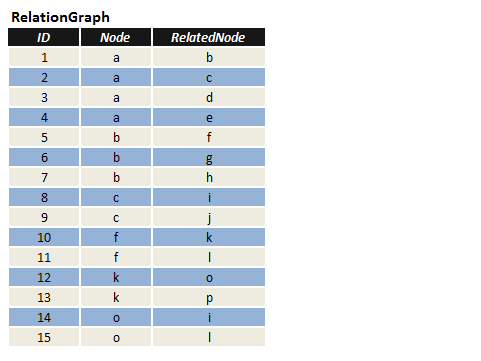
圖1.
解析:
了能夠更好的描述表RelationGraph中字段Node和 RelatedNode的關系,我在這裡特意使用一個圖形來描述,
如圖2.
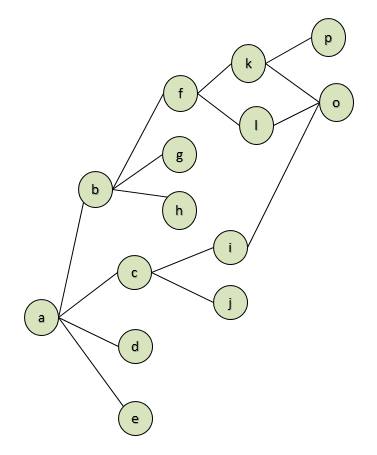
圖2.
在圖2,可清晰的看出各個節點直接如何相連,也可以清楚的看出節點"p"至節點"j"的的幾種可能路徑。
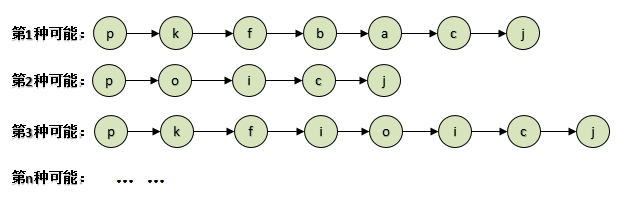
從上面可以看出第2種可能路徑,經過的節點最少。
為了解決開始的問題,我參考了兩種方法,
第1方法是,
參考單源最短路徑算法:Dijkstra(迪傑斯特拉)算法,主要特點是以起始點為中心向外層層擴展,直到擴展到終點為止。
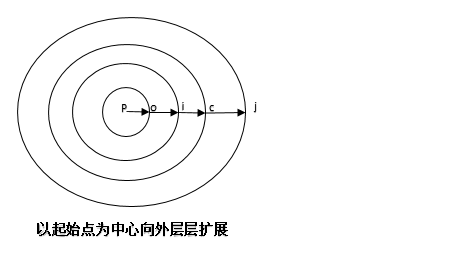
圖3.
第2方法是,
針對第1種方法的改進,就是采用多源點方法,這裡就是以節點"p"和節點"j"為中心向外層擴展,直到兩圓外切點,如圖4. :
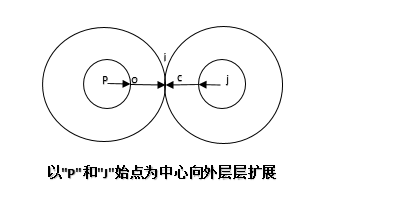
圖4.
實現:
在接下來,我就描述在SQL Server中,如何實現。當然我這裡采用的前面說的第2種方法,以"P"和"J"為始點像中心外層層擴展。
這裡提供有表RelactionGraph的create& Insert數據的腳本:
復制代碼 代碼如下:
use TestDB
go
if object_id('RelactionGraph') Is not null drop table RelactionGraph
create table RelactionGraph(ID int identity,Item nvarchar(50),RelactionItem nvarchar(20),constraint PK_RelactionGraph primary key(ID))
go
create nonclustered index IX_RelactionGraph_Item on RelactionGraph(Item) include(RelactionItem)
create nonclustered index IX_RelactionGraph_RelactionItem on RelactionGraph(RelactionItem) include(Item)
go
insert into RelactionGraph (Item, RelactionItem ) values
('a','b'),('a','c'),('a','d'),('a','e'),
('b','f'),('b','g'),('b','h'),
('c','i'),('c','j'),
('f','k'),('f','l'),
('k','o'),('k','p'),
('o','i'),('o','l')
go
編寫一個存儲過程up_GetPath
復制代碼 代碼如下:
use TestDB
go
--Procedure:
if object_id('up_GetPath') Is not null
Drop proc up_GetPath
go
create proc up_GetPath
(
@Node nvarchar(50),
@RelatedNode nvarchar(50)
)
As
set nocount on
declare
@level smallint =1, --當前搜索的深度
@MaxLevel smallint=100, --最大可搜索深度
@Node_WhileFlag bit=1, --以@Node作為中心進行搜索時候,作為能否循環搜索的標記
@RelatedNode_WhileFlag bit=1 --以@RelatedNode作為中心進行搜索時候,作為能否循環搜索的標記
--如果直接找到兩個Node存在直接關系就直接返回
if Exists(select 1 from RelationGraph where (Node=@Node And RelatedNode=@RelatedNode) or (Node=@RelatedNode And RelatedNode=@Node) ) or @Node=@RelatedNode
begin
select convert(nvarchar(2000),@Node + ' --> '+ @RelatedNode) As RelationGraphPath,convert(smallint,0) As StopCount
return
end
--
if object_id('tempdb..#1') Is not null Drop Table #1 --臨時表#1,存儲的是以@Node作為中心向外擴展的各節點數據
if object_id('tempdb..#2') Is not null Drop Table #2 --臨時表#2,存儲的是以@RelatedNode作為中心向外擴展的各節點數據
create table #1(
Node nvarchar(50),--相對源點
RelatedNode nvarchar(50), --相對目標
Level smallint --深度
)
create table #2(Node nvarchar(50),RelatedNode nvarchar(50),Level smallint)
insert into #1 ( Node, RelatedNode, Level )
select Node, RelatedNode, @level from RelationGraph a where a.Node =@Node union --正向:以@Node作為源查詢
select RelatedNode, Node, @level from RelationGraph a where a.RelatedNode = @Node --反向:以@Node作為目標進行查詢
set @Node_WhileFlag=sign(@@rowcount)
insert into #2 ( Node, RelatedNode, Level )
select Node, RelatedNode, @level from RelationGraph a where a.Node =@RelatedNode union --正向:以@RelatedNode作為源查詢
select RelatedNode, Node, @level from RelationGraph a where a.RelatedNode = @RelatedNode --反向:以@RelatedNode作為目標進行查詢
set @RelatedNode_WhileFlag=sign(@@rowcount)
--如果在表RelationGraph中找不到@Node 或 @RelatedNode 數據,就直接跳過後面的While過程
if not exists(select 1 from #1) or not exists(select 1 from #2)
begin
goto While_Out
end
while not exists(select 1 from #1 a inner join #2 b on b.RelatedNode=a.RelatedNode) --判斷是否出現切點
and (@Node_WhileFlag|@RelatedNode_WhileFlag)>0 --判斷是否能搜索
And @level<@MaxLevel --控制深度
begin
if @Node_WhileFlag >0
begin
insert into #1 ( Node, RelatedNode, Level )
--正向
select a.Node,a.RelatedNode,@level+1
From RelationGraph a
where exists(select 1 from #1 where RelatedNode=a.Node And Level=@level) And
Not exists(select 1 from #1 where Node=a.Node)
union
--反向
select a.RelatedNode,a.Node,@level+1
From RelationGraph a
where exists(select 1 from #1 where RelatedNode=a.RelatedNode And Level=@level) And
Not exists(select 1 from #1 where Node=a.RelatedNode)
set @Node_WhileFlag=sign(@@rowcount)
end
if @RelatedNode_WhileFlag >0
begin
insert into #2 ( Node, RelatedNode, Level )
--正向
select a.Node,a.RelatedNode,@level+1
From RelationGraph a
where exists(select 1 from #2 where RelatedNode=a.Node And Level=@level) And
Not exists(select 1 from #2 where Node=a.Node)
union
--反向
select a.RelatedNode,a.Node,@level+1
From RelationGraph a
where exists(select 1 from #2 where RelatedNode=a.RelatedNode And Level=@level) And
Not exists(select 1 from #2 where Node=a.RelatedNode)
set @RelatedNode_WhileFlag=sign(@@rowcount)
end
select @level+=1
end
While_Out:
--下面是構造返回的結果路徑
if object_id('tempdb..#Path1') Is not null Drop Table #Path1
if object_id('tempdb..#Path2') Is not null Drop Table #Path2
;with cte_path1 As
(
select a.Node,a.RelatedNode,Level,convert(nvarchar(2000),a.Node+' -> '+a.RelatedNode) As RelationGraphPath,Convert(smallint,1) As PathLevel From #1 a where exists(select 1 from #2 where RelatedNode=a.RelatedNode)
union all
select b.Node,a.RelatedNode,b.Level,convert(nvarchar(2000),b.Node+' -> '+a.RelationGraphPath) As RelationGraphPath ,Convert(smallint,a.PathLevel+1) As PathLevel
from cte_path1 a
inner join #1 b on b.RelatedNode=a.Node
and b.Level=a.Level-1
)
select * Into #Path1 from cte_path1
;with cte_path2 As
(
select a.Node,a.RelatedNode,Level,convert(nvarchar(2000),a.Node) As RelationGraphPath,Convert(smallint,1) As PathLevel From #2 a where exists(select 1 from #1 where RelatedNode=a.RelatedNode)
union all
select b.Node,a.RelatedNode,b.Level,convert(nvarchar(2000),a.RelationGraphPath+' -> '+b.Node) As RelationGraphPath ,Convert(smallint,a.PathLevel+1)
from cte_path2 a
inner join #2 b on b.RelatedNode=a.Node
and b.Level=a.Level-1
)
select * Into #Path2 from cte_path2
;with cte_result As
(
select a.RelationGraphPath+' -> '+b.RelationGraphPath As RelationGraphPath,a.PathLevel+b.PathLevel -1 As StopCount,rank() over(order by a.PathLevel+b.PathLevel) As Result_row
From #Path1 a
inner join #Path2 b on b.RelatedNode=a.RelatedNode
and b.Level=1
where a.Level=1
)
select distinct RelationGraphPath,StopCount From cte_result where Result_row=1
go
上面的存儲過程,主要分為兩大部分,第1部分是實現如何搜索,第2部分實現如何構造返回結果。其中第1部分的代碼根據前面的方法2,通過@Node 和 @RelatedNode 兩個節點向外層搜索,每次搜索返回的節點都保存至臨時表#1和#2,再判斷臨時表#1和#2有沒有出現切點,如果出現就說明已找到最短的路徑(經過多節點數最少),否則就繼續循環搜索,直到循環至最大的搜索深度(@MaxLevel smallint=100)或找到切點。要是到100層都沒搜索到切點,將放棄搜索。這裡使用最大可搜索深度@MaxLevel,目的是控制由於數據量大可能會導致性能差,因為在這裡數據量與搜索性能成反比。代碼中還說到一個正向和反向搜索,主要是相對Node 和 RelatedNode來說,它們兩者互為參照對象,進行向外搜索使用。
下面是存儲過程的執行:
復制代碼 代碼如下:
use TestDB
go
exec dbo.up_GetPath
@Node = 'p',
@RelatedNode = 'j'
go

你可以根據需要來,賦予@Node 和 @RelatedNode不同的值。
拓展:
前面的例子,可擴展至城市的公交路線,提供兩個站點,搜索經過這兩個站點最少站點公交路線;可以擴展至社區的人際關系的搜索,如一個人與另一個人想認識,那麼他們直接要經過多少個人才可以。除了人與人直接有直接的朋友、親戚關聯,還可以通過人與物有關聯找到人與人關聯,如幾個作家通過出版一個本,那麼就說明這幾個人可以通過某一本書的作者列表中找到他們存在共同出版書籍的關聯,這為搜索兩個人認識路徑提供參考。這問題可能會非常大復雜,但可以這樣的擴展。
小結:
這裡只是找兩個節點的所有路徑中,節點數最少的路徑,在實際的應用中,可能會碰到比這裡更復雜的情況。在其他的環境或場景可能會帶有長度,時間,多節點,多作用域等一些信息。無論如何,一般都要參考一些原理,算法來實現。