您必須了解數據,以便在創建挖掘模型時作出正確的決策。浏覽技術包括計算最小值和最大值,計算平均偏差和標准偏差,以及查看數據的分布。例如,通過查看最大值、最小值和平均值,您可以確定數據並不能代表客戶或業務流程,因此您必須獲取更多均衡數據或查看您的預期結果所依據的假定。標准偏差和其他分發值可以提供有關結果的穩定性和准確性的有用信息。大型標准偏差可以指示添加更多數據可以幫助改進模型。與標准分發偏差很大的數據可能已被扭曲,抑或准確反映了現實問題,但很難使模型適合數據。
借助您自己對業務問題的理解來浏覽數據,您可以確定數據集是否包含缺陷數據,隨後您可以設計用於解決該問題的策略或者更深入地理解業務的典型行為。
BI Development Studio 中的數據源視圖設計器包含數種可用於浏覽數據的工具。
此外,在創建模型時,Analysis Services 還會針對該模型中包含的數據自動創建統計摘要,您可以進行查詢以便用於報告或進一步分析。
生成模型
如以下關系圖中突出顯示的那樣,數據挖掘過程的第四步就是生成一個或多個挖掘模型。您將使用從浏覽數據步驟中獲得的知識來幫助定義和創建模型。
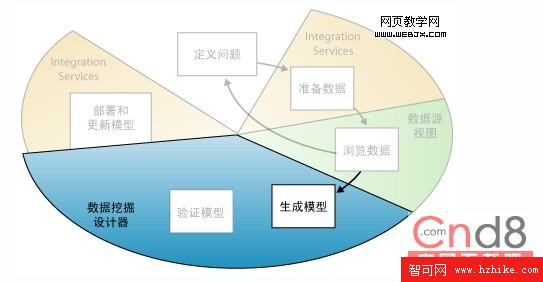
通過創建挖掘結構定義要使用的數據。挖掘結構定義數據源,但只有對挖掘結構進行處理後,該結構才會包含任何數據。處理挖掘結構時,Analysis Services 生成可用於分析的聚合信息以及其他統計信息。基於該結構的所有挖掘模型均可使用該信息。
在處理模型之前,數據挖掘模型只是一個容器,指定用於輸入的列、要預測的屬性以及指示算法如何處理數據的參數。處理模型也稱為“定型”。定型表示向結構中的數據應用特定數學算法以便提取模式的過程。在定型過程中找到的模式取決於選擇的定型數據、所選算法以及如何配置該算法。SQL Server 2008 包含多種不同算法,每種算法都適合不同的任務類型,並且每種算法都創建不同的模型類型。
此外,還可以使用參數調整每種算法,並向定型數據應用篩選器,以便僅使用數據子集,進而創建不同結果。在通過模型傳遞數據之後,即可查詢挖掘模型對象包含的摘要和模式,並將其用於預測。
您可以在 BI Development Studio 中使用數據挖掘向導或使用數據挖掘擴展插件 (DMX) 語言來定義新的模型。
務必記住,只要數據發生更改,必須更新數據挖掘結構和挖掘模型。重新處理挖掘結構以進行更新時,Analysis Services 檢索源中的數據,包括任何新數據(如果動態更新源),並重新填充挖掘結構。如果您具有基於結構的模型,則可以選擇更新基於該結構的模型,這表示可以根據新數據保留模型,或者也可以使模型保持原樣。