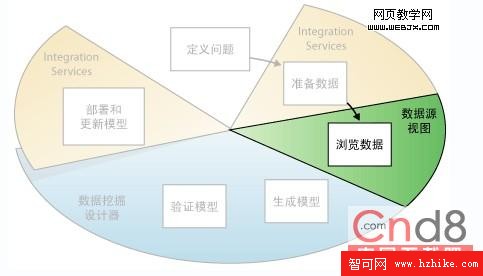
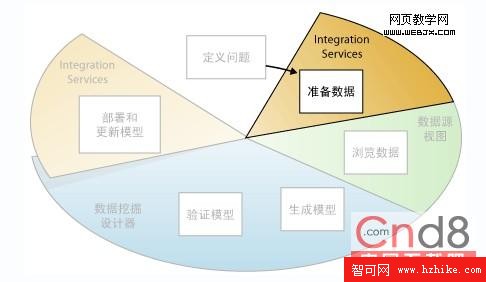
准備數據
如以下關系圖中突出顯示的那樣,數據挖掘過程的第二步就是合並和清除定義問題步驟中標識的數據。
數據可以分散在公司的各個部門並以不同的格式存儲,或者可能包含錯誤項或缺少項之類的不一致性。例如,數據可能顯示客戶在產品推向市場之前購買該產品,或者客戶在距離她家 2,000 英裡的商店定期購物。
數據清除不僅僅是刪除錯誤數據,還包括查找數據中的隱含相關性、標識最准確的數據源並確定哪些列最適合用於分析。例如,應當使用發貨日期還是訂購日期?最佳銷售影響因素是數量、總價格,還是打折價格?不完整數據、錯誤數據和輸入看似獨立,但實際上有很強的關聯性,它們可以以意想不到的方式影響模型的結果。因此,在開始生成挖掘模型之前,應確定這些問題及其解決方式。
通常,您使用的是一個非常大的數據集,並且無法仔細查看每個事務。因此,必須使用某種自動化的形式(如,在 Integration Services 中)來浏覽數據並找到這些不一致。Microsoft SQL Server 2008 Integration Services (SSIS) 包含完成該步驟所需的所有工具,步驟內容包括轉換到自動執行數據清除和合並。
需要特別注意的是用於數據挖掘的數據不必存儲在聯機分析處理 (OLAP) 多維數據集中,或者甚至不必存儲在關系數據庫中,但是您可以將它們作為數據源使用。您可以使用已被定義為 Analysis Services 數據源的任何數據源執行數據挖掘。這些數據源可以包括文本文件、Excel 工作簿或來自其他外部提供程序的數據。
浏覽數據
如以下關系圖中突出顯示的那樣,數據挖掘過程的第三步就是浏覽已准備的數據。