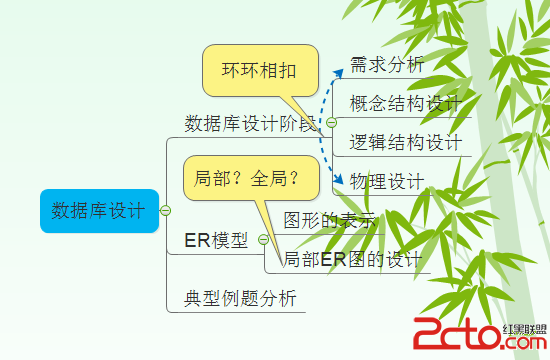
混合內存系統包含每個節點上的索引和數據,操縱與物理存儲的互動。它還包括用於自動移除就數據的模塊以及碎片整理等模塊。
Aerospike可以將數據存儲在DRAM,傳統磁盤及SSD硬盤,每個namespace可以分別進行配置。這種配置彈性允許應用程序開發者在內存中配置一個小但頻繁訪問的namespace,在相對廉價的SSD硬盤中配置一個大的namespace。
在SSD上優化數據存儲的重要工作已完成,包括穿透文件系統利用底層SSD讀寫模式。
不同於 Large Data Types,一條記錄的所有數據存儲在一起。每行的存儲限制默認為 1 MB。
存儲寫時復制(copy-on-write),由碎片整理進程回收空間。
每個namespace配置固定大小的存儲。每個節點必須有一樣的namespace,並且每個namespace大小一致。
存儲可以配置為純內存無持久化,內存並持久化,或者閃存(SSD)
持久化存儲(磁盤)必須是閃存或高性能塊存儲設備(雲),或者是任何存儲設備上的文件。
內存中的數據-無持久化-好處是高吞吐量。即使是高性能的現代閃存存儲性能依舊不及內存,內存的價格也在快速下降。
數據通過 JEMalloc 分配器進行分配。JEMalloc允許分配到不同的池。長期分配-比如那些為存儲層所做的-可以單獨分配。我們發現JEMalloc分配器在低碎片的情況下具有超常性能。
通過DRAM的多副本可以獲得高級別的可靠性。由於Aerospike在集群節點損壞或節點加入時重新進行數據分配和數據復制,可以獲得高級別的"k-safety" 。自動從數據副本中恢復節點數據。
由於Aerospike的隨機數據分布( data distribution),當幾個節點失敗時數據不可用風險相當小。例如,在一個有兩個數據拷貝的10節點集群中,如果兩個節點失效。失效數據的數量大約2%,1/50的數據。
當持久層被配置,讀發生在內存副本。通過數據路徑進行寫入。
當數據被寫入,為避免相同記錄寫入沖突會在行上加寫入闩。在某些集群狀態下,數據需要從其他節點讀入並解決沖突問題。
當寫入被確認,內存中的記錄在主節點被更新。被寫入的數據添加到寫緩沖區。如果寫緩沖區滿了,排隊寫入磁盤。類似最大行數,依賴於寫緩沖區大小和寫吞吐量,這裡存在一些未提交數據的風險。
如果有副本,當更新時他們的索引同時更新。當多有內存中的副本都被更新,結果將返回客戶端。
系統可以被配置為在所有寫完成之前返回結果-延遲一致性。
Aerospike數據包括整型、字符串、二進制對象、原生序列化類型、列表、映射及LDTs。
除了更高效的"single bin mode",bin-Aerospike的列-每個bin有一個bin名稱,它用一個字符串表進行存儲。每個列的名稱被存儲移除,一個namespace中可以存儲32K個唯一bin名稱。
如果需要更多的bin名稱,可以考慮使用map。利用map,你可以存儲任意數量的鍵值對,通過UDF訪問高效訪問數據。
如果通過類似java class這樣的復雜語言類型訪問數據。Aerospike客戶端將使用語言原生的序列化系統。數據將被存儲為語言指定的 "blob type"。這允許相同語言的客戶端使用清晰的代碼讀取數據,但是大多數語言的默認序列化很簡陋。
整型以8字節存儲,這限制了當前版本整型的值。Aerospike網絡協議允許變長整型。
String以 UTF-8字符集存儲。對大多數字符串UTF-8比unicode更緊湊。為了允許誇語言兼容,客戶端函數庫將原始的unicode字符轉換成UTF-8.
最有效率的方式是使用二進制對象 (blobs)。其大小限制於記錄大小限制相當。許多部署使用自己的序列化,可能對對象壓縮後直接存儲。這樣做意味著數據不能容易的通過UDF訪問
復雜類型呈現為msgpack本地存儲。復雜對象在客戶端被序列化,利用寫協議發送。當應用到簡單的get/put操作,網絡格式無需序列化或轉換,直接寫入存儲。
碎片整理器追蹤磁盤上每個塊上的活動記錄數量,回收低於最低使用的塊。碎片整理器不斷掃描活動快,查找那些有一定數量空閒空間的塊。
碎片整理器追蹤磁盤上每個塊上的活動記錄數量,回收低於最低使用的塊。清除器負責移除過期記錄,當系統到達預設的高水位線時回收內存。當配置namespace時,管理員指定namespace使用內存的最大值。通常操作下,清理器查找過期數據,釋放內存和磁盤空間。清理器也通過namespace追蹤內存使用情況,如果內存達到預設的高水位線,即使記錄不是必須過期,清理器也會釋放比較舊的記錄。當系統內存達到使用上限時,通過允許清理器移除老的數據,Aerospike可以被作為一個高效的LRU(最近最少使用算法) cache使用。注意,記錄的年齡通過其最後一次修改時間來度量,應用程序可以在任何時間修改記錄的存活期。應用程序也可以指定記錄永遠不被自動回收。
為了支持大對象的存儲能力,Aerospike支持新的底層存儲模型,這就是所說的“子記錄”(sub-records)。子記錄(sub-records)與常規記錄很相似,主要的不同點事不能直接訪問。子記錄鏈接在父記錄上並通過父記錄進行訪問。子記錄與父記錄共享分區ID和內部記錄鎖,所以在遷移時與父記錄一起移動,與父記錄一起通過一樣的隔離機制保護。
Aerospike LDT 使用這種存儲算法構建。LDT bins/records(具有LDT類型bin的記錄)不是連續存儲的相關記錄,而是劃分為多個子記錄(大小在2k至1M)。一個子記錄至於一個bin有關,可以包含多個項目(例如,8k的子記錄可以持有100個80bytes的字符串數據)。子記錄之間是互連的,鏈接在父記錄上來提供有效的更新和查找。
因此,LDT對象利用Aerospike健壯的復制,再平衡及遷移算法來確保即時一致性和高可用。LDT對象通過客戶端API在數據庫服務器端處理。
子記錄機制有如下好處
利用SSD能力執行隨機讀不需要任何其他開銷,也不需要想傳統數據庫實施時所擔心的數據在存儲上的排列問題。當執行指定的LDT操作(例如插入100bytes)成本只相當於與更新LDT條目,客戶端與服務器直接也沒有LDT的交互成本。