Sybase數據庫簡介 Sybase公司成立於1984年,公司名稱“Sybase”取自“system”和“database”相結合的含義。Sybase公司的第一個關系數據庫產品是1987年5月推出的Sybase SQLServer1.0。Sybase首先提出Client/Server 數據庫體系結構的思想,並率先在Sybase SQLServer 中實現。Sybase覺得單靠一家力量,難以把SQLServer(那時不叫ASE)做到老大,於是聯合微軟,共同開發。後來1994年,兩家公司合作終止。截止此時,應該是都擁有一套完全相同的SQLServer代碼。Sybase SQLServer後來為了與微軟的MS SQL Server相區分,改名叫:Sybase ASE(Adaptive Server Enterprise),其實,應該改名字的是微軟。Sybase ASE仍然保持著大型數據庫廠商的地位。在電信、交通、市政、銀行等領域,擁有強大的市場。
Indexes are the most important physical design element in improving database performance:
Indexes help prevent table scans. Instead of reading hundreds of data pages, a few index pages and data pages can satisfy many queries.
For some queries, data can be retrieved from a nonclustered index without ever accessing the data rows.
Clustered indexes can randomize data inserts, avoiding insert “hot spots” on the last page of a table.
Indexes can help avoid sorts, if the index order matches the order of columns in an order by clause.
In addition to their performance benefits, indexes can enforce the uniqueness of data.
Indexes are database objects that can be created for a table to speed direct access to specific data rows. Indexes store the values of the key(s) that were named when the index was created, and logical pointers to the data pages or to other index pages.
Although indexes speed data retrieval, they can slow down data modifications, since most changes to the data also require updating the indexes.
索引可以防止全表掃描,對某些查詢無需訪問數據頁(復合索引),聚集索引避免頻繁插入新數據到最後一頁,避免排序。Adaptive Server provides two types of indexes:
Clustered indexes, where the table data is physically stored in the order of the keys on the index:
For allpages-locked tables, rows are stored in key order on pages, and pages are linked in key order.
For data-only-locked tables, indexes are used to direct the storage of data on rows and pages, but strict key ordering is not maintained.
Nonclustered indexes, where the storage order of data in the table is not related to index keys
You can create only one clustered index on a table because there is only one possible physical ordering of the data rows. You can create up to 249 nonclustered indexes per table.
A table that has no clustered index is called a heap. The rows in the table are in no particular order, and all new rows are added to the end of the table. Chapter 8, “Data Storage,” discusses heaps and SQL operations on heaps.
聚集索引的數據頁上的數據是根據索引鍵排好序的,因此一張表只能有一個聚集索引。沒有聚集索引的表也叫堆。Index entries are stored as rows on index pages in a format similar to the format used for data rows on data pages. Index entries store the key values and pointers to lower levels of the index, to the data pages, or to individual data rows.
Adaptive Server uses B-tree indexing, so each node in the index structure can have multiple children.
Index entries are usually much smaller than a data row in a data page, and index pages are much more densely populated than data pages. If a data row has 200 bytes (including row overhead), there are 10 rows per page.
An index on a 15-byte field has about 100 rows per index page (the pointers require 4–9 bytes per row, depending on the type of index and the index level).
Indexes can have multiple levels:
Root level
Leaf level
Intermediate level
The root level is the highest level of the index. There is only one root page. If an allpages-locked table is very small, so that the entire index fits on a single page, there are no intermediate or leaf levels, and the root page stores pointers to the data pages.
Data-only-locked tables always have a leaf level between the root page and the data pages.
For larger tables, the root page stores pointers to the intermediate level index pages or to leaf-level pages.
對於很小的表,只需一個根索引頁即可。大表可能會有很多中間頁。The lowest level of the index is the leaf level. At the leaf level, the index contains a key value for each row in the table, and the rows are stored in sorted order by the index key:
For clustered indexes on allpages-locked tables, the leaf level is the data. No other level of the index contains one index row for each data row.
For nonclustered indexes and clustered indexes on data-only-locked tables, the leaf level contains the index key value for each row, a pointer to the page where the row is stored, and a pointer to the rows on the data page.
The leaf level is the level just above the data; it contains one index row for each data row. Index rows on the index page are stored in key value order.
All levels between the root and leaf levels are intermediate levels. An index on a large table or an index using long keys may have many intermediate levels. A very small allpages-locked table may not have an intermediate level at all; the root pages point directly to the leaf level.
Table 12-1 describes the new limits for index size for APL and DOL tables:
Page size
User-visible index row-size limit
Internal index row-size limit
2K (2048 bytes)
600
650
4K (4096bytes)
1250
1310
8K (8192 bytes)
2600
2670
16K (16384 bytes)
5300
5390
Because you can create tables with columns wider than the limit for the index key, these columns become non-indexable. For example, if you perform the following on a 2K page server, then try to create an index on c3, the command fails and Adaptive Server issues an error message because column c3 is larger than the index row-size limit (600 bytes).
create table t1 (c1 int,c2 int,c3 char(700))
“Non-indexable” does not mean that you cannot use these columns in search clauses. Even though a column is non-indexable (as in c3, above), you can still create statistics for it. Also, if you include the column in a where clause, it will be evaluated during optimization.
列的長度不能大於索引項的最大長度,否則會報錯。In clustered indexes on allpages-locked tables, leaf-level pages are also the data pages, and all rows are kept in physical order by the keys.
Physical ordering means that:
All entries on a data page are in index key order.
By following the “next page” pointers on the data pages, Adaptive Server reads the entire table in index key order.
On the root and intermediate pages, each entry points to a page on the next level.
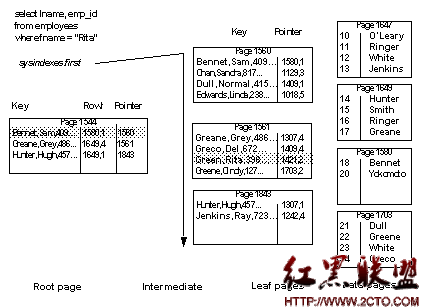
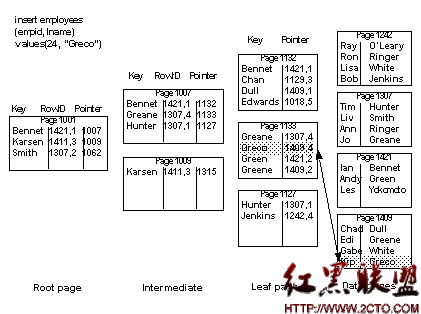
To select a particular last name using a clustered index, Adaptive Server first uses sysindexes to find the root page. It examines the values on the root page and then follows page pointers, performing a binary search on each page it accesses as it traverses the index. See Figure 12-1 below.
Figure 12-1: Selecting a row using a clustered index, allpages-locked table
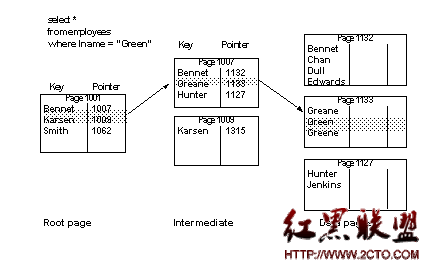
On the root level page, “Green” is greater than “Bennet,” but less than Karsen, so the pointer for “Bennet” is followed to page 1007. On page 1007, “Green” is greater than “Greane,” but less than “Hunter,” so the pointer to page 1133 is followed to the data page, where the row is located and returned to the user.
This retrieval via the clustered index requires:
One read for the root level of the index
One read for the intermediate level
One read for the data page
These reads may come either from cache (called a logical read) or from disk (called a physical read). On tables that are frequently used, the higher levels of the indexes are often found in cache, with lower levels and data pages being read from disk.
When you insert a row into an allpages-locked table with a clustered index, the data row must be placed in physical order according to the key value on the table.
Other rows on the data page move down on the page, as needed, to make room for the new value. As long as there is room for the new row on the page, the insert does not affect any other pages in the database.
The clustered index is used to find the location for the new row.
Figure 12-2 shows a simple case where there is room on an existing data page for the new row. In this case, the key values in the index do not need to change.
Figure 12-2: Inserting a row into an allpages-locked table with a clustered index
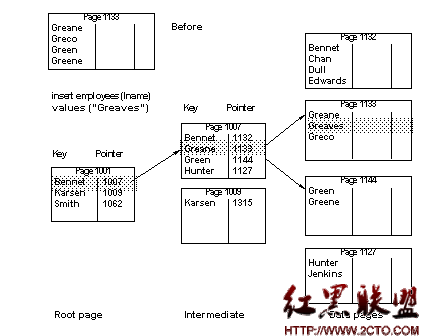 因為插入時要保證數據頁的物理順序,所以要用聚集索引找到插入值的位置。
因為插入時要保證數據頁的物理順序,所以要用聚集索引找到插入值的位置。
If there is not enough room on the data page for the new row, a page split must be performed.
A new data page is allocated on an extent already in use by the table. If there is no free page available, a new extent is allocated.
The next and previous page pointers on adjacent pages are changed to incorporate the new page in the page chain. This requires reading those pages into memory and locking them.
Approximately half of the rows are moved to the new page, with the new row inserted in order.
The higher levels of the clustered index change to point to the new page.
If the table also has nonclustered indexes, all pointers to the affected data rows must be changed to point to the new page and row locations.
In some cases, page splitting is handled slightly differently.
See “Exceptions to page splitting”.
In Figure 12-3, the page split requires adding a new row to an existing index page, page 1007.
Figure 12-3: Page splitting in an allpages-locked table with a clustered index
將有一半的數據挪到新建的數據頁上。索引頁的分離與數據頁類似。
If a new row needs to be added to a full index page, the page split process on the index page is similar to the data page split.
A new page is allocated, and half of the index rows are moved to the new page.
A new row is inserted at the next highest level of the index to point to the new index page.
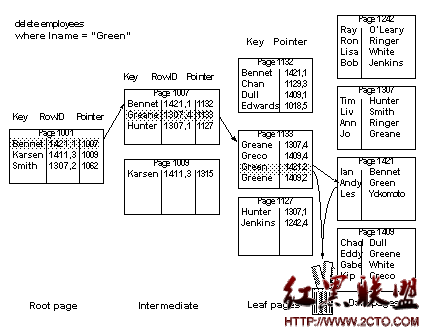
When you delete a row from an allpages-locked table that has a clustered index, other rows on the page move up to fill the empty space so that the data remains contiguous on the page.
Figure 12-5 shows a page that has four rows before a delete operation removes the second row on the page. The two rows that follow the deleted row are moved up.
Figure 12-5: Deleting a row from a table with a clustered index
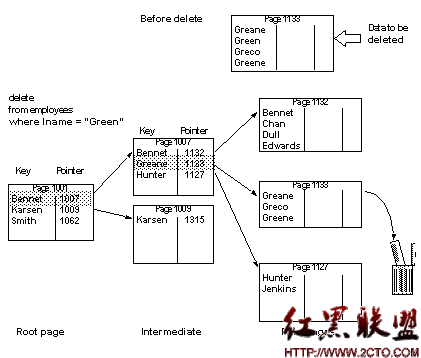
If you delete the last row on a data page, the page is deallocated and the next and previous page pointers on the adjacent pages are changed.
The rows that point to that page in the leaf and intermediate levels of the index are removed.
If the deallocated data page is on the same extent as other pages belonging to the table, it can be used again when that table needs an additional page.
If the deallocated data page is the last page on the extent that belongs to the table, the extent is also deallocated and becomes available for the expansion of other objects in the database.
In Figure 12-6, which shows the table after the deletion, the pointer to the deleted page has been removed from index page 1007 and the following index rows on the page have been moved up to keep the used space contiguous.
Figure 12-6: Deleting the last row on a page (after the delete)

If you delete a pointer from an index page, leaving only one row on that page, the row is moved onto an adjacent page, and the empty page is deallocated. The pointers on the parent page are updated to reflect the changes.
The B-tree works much the same for nonclustered indexes as it does for clustered indexes, but there are some differences. In nonclustered indexes:
The leaf pages are not the same as the data pages.
The leaf level stores one key-pointer pair for each row in the table.
The leaf-level pages store the index keys and page pointers, plus a pointer to the row offset table on the data page. This combination of page pointer plus the row offset number is called the row ID.
The root and intermediate levels store index keys and page pointers to other index pages. They also store the row ID of the key’s data row.
With keys of the same size, nonclustered indexes require more space than clustered indexes.
聚集索引中數據頁是按照索引項排好序的,因此索引頁只需保存頁號,找到數據頁後二分查找。但非聚集索引中數據頁是亂序的,所以索引頁還要保存行偏移(應該是為了提高效率,不然只能順序查找),跟頁號一起組成rowID。根索引頁和中間索引頁除了保存指向下層節點指針外,也要保存rowID(原因見下)。並且聚集索引中數據頁就是頁級別索引頁,綜合上述兩點,聚集索引占據空間更小。The leaf page of an index is the lowest level of the index where all of the keys for the index appear in sorted order.
In clustered indexes on allpages-locked tables, the data rows are stored in order by the index keys, so by definition, the data level is the leaf level. There is no other level of the clustered index that contains one index row for each data row. Clustered indexes on allpages-locked tables are sparse indexes.
The level above the data contains one pointer for every data page, not data row.
In nonclustered indexes and clustered indexes on data-only-locked tables, the level just above the data is the leaf level: it contains a key-pointer pair for each data row. These indexes are dense. At the level above the data, they contain one index row for each data row.
索引頁的總結:聚集索引中,數據頁(即頁級別)的上層節點層(即中間或根)只需涵蓋所有數據頁即可。而非聚集索引中,數據頁的上層節點層(即頁級別)要涵蓋每一行數據。所以非聚集索引是密集型的。The table in Figure 12-7 shows a nonclustered index on lname. The data rows at the far right show pages in ascending order by employee_id (10, 11, 12, and so on) because there is a clustered index on that column.
The root and intermediate pages store:
The key value
The row ID
The pointer to the next level of the index
The leaf level stores:
The key value
The row ID
The row ID in higher levels of the index is used for indexes that allow duplicate keys. If a data modification changes the index key or deletes a row, the row ID positively identifies all occurrences of the key at all index levels.
Figure 12-7: Nonclustered index structure
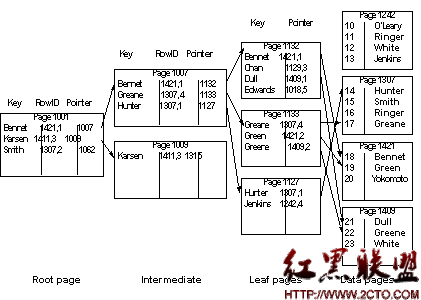 聚集索引和非聚集索引同時存在時的結構。Employee_id上存在聚集索引,Name上存在非聚集索引。
非頁級別的節點中保存rowID是為了避免重復的鍵值,即索引可能不是unique索引。
聚集索引和非聚集索引同時存在時的結構。Employee_id上存在聚集索引,Name上存在非聚集索引。
非頁級別的節點中保存rowID是為了避免重復的鍵值,即索引可能不是unique索引。
When you select a row using a nonclustered index, the search starts at the root level. sysindexes.root stores the page number for the root page of the nonclustered index.
In Figure 12-8, “Green” is greater than “Bennet,” but less than “Karsen,” so the pointer to page 1007 is followed.
“Green” is greater than “Greane,” but less than “Hunter,” so the pointer to page 1133 is followed. Page 1133 is the leaf page, showing that the row for “Green” is row 2 on page 1421. This page is fetched, the “2” byte in the offset table is checked, and the row is returned from the byte position on the data page.
Figure 12-8: Selecting rows using a nonclustered index
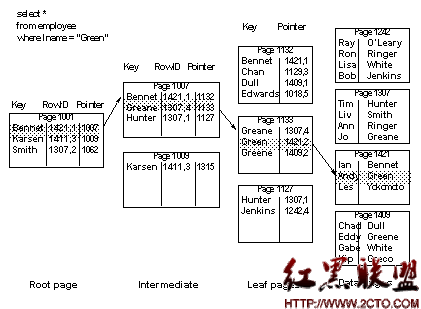
The query in Figure 12-8 requires the following I/O:
One read for the root level page
One read for the intermediate level page
One read for the leaf-level page
One read for the data page
If your applications use a particular nonclustered index frequently, the root and intermediate pages will probably be in cache, so only one or two physical disk I/Os need to be performed.
When you insert rows into a heap that has a nonclustered index and no clustered index, the insert goes to the last page of the table.
If the heap is partitioned, the insert goes to the last page on one of the partitions. Then, the nonclustered index is updated to include the new row.
If the table has a clustered index, it is used to find the location for the row. The clustered index is updated, if necessary, and each nonclustered index is updated to include the new row.
Figure 12-9 shows an insert into a heap table with a nonclustered index. The row is placed at the end of the table. A row containing the new key value and the row ID is also inserted into the leaf level of the nonclustered index.
Figure 12-9: An insert into a heap table with a nonclustered index
 如果只存在非聚集索引,則插入數據到最後一頁並新建一個索引項(需要查找在哪裡添加,因為頁級別索引頁中的索引項是按照索引鍵排序的)。如果存在聚集索引,先更新聚集索引(用聚集索引確定插入值位置然後更新),再新建非聚集索引項。
如果只存在非聚集索引,則插入數據到最後一頁並新建一個索引項(需要查找在哪裡添加,因為頁級別索引頁中的索引項是按照索引鍵排序的)。如果存在聚集索引,先更新聚集索引(用聚集索引確定插入值位置然後更新),再新建非聚集索引項。
When you delete a row from a table, the query can use a nonclustered index on the columns in the where clause to locate the data row to delete, as shown in Figure 12-10.
The row in the leaf level of the nonclustered index that points to the data row is also removed. If there are other nonclustered indexes on the table, the rows on the leaf level of those indexes are also deleted.
Figure 12-10: Deleting a row from a table with a nonclustered index
If the delete operation removes the last row on the data page, the page is deallocated and the adjacent page pointers are adjusted in allpages-locked tables. Any references to the page are also deleted in higher levels of the index.
If the delete operation leaves only a single row on an index intermediate page, index pages may be merged, as with clustered indexes.
See “Index page merges”.
There is no automatic page merging on data pages, so if your applications make many random deletes, you may end up with data pages that have only a single row, or a few rows, on a page.
由於非聚集索引的數據頁是無序的,可以看出插入,刪除操作的維護比較簡單。Index covering can produce dramatic performance improvements when all columns needed by the query are included in the index.
You can create indexes on more than one key. These are called composite indexes. Composite indexes can have up to 31 columns adding up to a maximum 600 bytes.
If you create a composite nonclustered index on each column referenced in the query’s select list and in any where, having, group by, and order by clauses, the query can be satisfied by accessing only the index.
Since the leaf level of a nonclustered index or a clustered index on a data-only-locked table contains the key values for each row in a table, queries that access only the key values can retrieve the information by using the leaf level of the nonclustered index as if it were the actual table data. This is called index covering.
There are two types of index scans that can use an index that covers the query:
The matching index scan
The nonmatching index scan
For both types of covered queries, the index keys must contain all the columns named in the query. Matching scans have additional requirements.
“Choosing composite indexes” describes query types that make good use of covering indexes.
Lets you skip the last read for each row returned by the query, the read that fetches the data page.
For point queries that return only a single row, the performance gain is slight — just one page.
For range queries, the performance gain is larger, since the covering index saves one read for each row returned by the query.
For a covering matching index scan to be used, the index must contain all columns named in the query. In addition, the columns in the where clauses of the query must include the leading column of the columns in the index.
For example, for an index on columns A, B, C, and D, the following sets can perform matching scans: A, AB, ABC, AC, ACD, ABD, AD, and ABCD. The columns B, BC, BCD, BD, C, CD, or D do not include the leading column and can be used only for nonmatching scans.
When doing a matching index scan, Adaptive Server uses standard index access methods to move from the root of the index to the nonclustered leaf page that contains the first row.
In Figure 12-11, the nonclustered index on lname, fname covers the query. The where clause includes the leading column, and all columns in the select list are included in the index, so the data page need not be accessed.
Figure 12-11: Matching index access does not have to read the data row
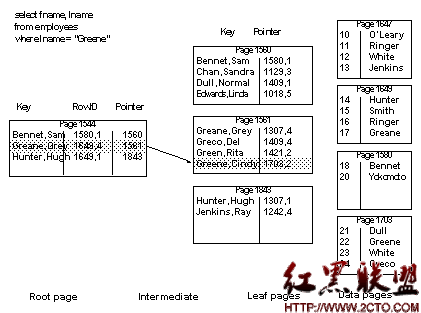 范圍查詢的性能會大幅提高。
范圍查詢的性能會大幅提高。
When the columns specified in the where clause do not include the leading column in the index, but all columns named in the select list and other query clauses (such as group by or having) are included in the index, Adaptive Server saves I/O by scanning the entire leaf level of the index, rather than scanning the table.
It cannot perform a matching scan because the first column of the index is not specified.
The query in Figure 12-12 shows a nonmatching index scan. This query does not use the leading columns on the index, but all columns required in the query are in the nonclustered index on lname, fname, emp_id.
The nonmatching scan must examine all rows on the leaf level. It scans all leaf level index pages, starting from the first page. It has no way of knowing how many rows might match the query conditions, so it must examine every row in the index. Since it must begin at the first page of the leaf level, it can use the pointer insysindexes.first rather than descending the index.
Figure 12-12: A nonmatching index scan