全局聲明式臨時表
臨時表常常用來存儲臨時數據和中間結果。因為它們不需要日志記錄,也不出現在系統編目中,所以可以提高性能。另外,因為臨時表只允許單一連接,所以不需要鎖。
只有聲明(創建)聲明式全局臨時表 (DGTT) 的連接才能訪問它。當這個數據庫連接結束時,臨時表被刪除。
要想創建 DGTT,需要執行 DECLARE GLOBAL TEMPORARY TABLE 語句。下面是這個語句的語法圖:
清單 1. 全局臨時表聲明的語法
.-,---------------------.
V |
>--+-(----| column-definition |-+--)-----------------------------+-->
+-LIKE--+-table-name1-+--+------------------+-----------------+
| '-vIEw-name---' '-| copy-options |-' |
'-AS--(--fullselect--)--DEFINITION ONLY--+------------------+-'
'-| copy-options |-'
.-ON COMMIT DELETE ROWS---.
>--?--+-------------------------+--?---------------------------->
'-ON COMMIT PRESERVE ROWS-'
>--+-------------------------------------------+---------------->
| .-ON ROLLBACK DELETE ROWS---. |
'-NOT LOGGED--+---------------------------+-'
'-ON ROLLBACK PRESERVE ROWS-'
>--?--+--------------+--?--+---------------------+-------------->
'-WITH REPLACE-' '-IN--tablespace-name-'
>--?--+------------------------------------------------------------+--?-><
| .-,-----------. |
| V | .-USING HASHING-. |
'-PARTITIONING KEY--(----column-name-+--)--+---------------+-'
column-definition
|--column-name--| data-type |--+--------------------+-----------|
'-| column-options |-'
請注意,當指定 WITH REPLACE 子句時,會刪除同名的現有 DGTT 並替換為新的表定義。
定義同名的聲明式全局臨時表的每個會話擁有自己的獨特的臨時表描述。當會話終止時,表行和臨時表描述被刪除。
下面解釋一些選項:
ON COMMIT DELETE ROWS:在執行 COMMIT 操作時,如果表上沒有打開 WITH HOLD 游標,就刪除表中的所有行。這是默認設置。
ON COMMIT PRESERVE ROWS:在執行 COMMIT 操作時,保留表中的所有行。
ON ROLLBACK DELETE ROWS:在執行 ROLLBACK(或 ROLLBACK to SAVEPOINT)操作時,如果已經修改了表數據,就刪除表中的所有行。這是默認設置。
ON ROLLBACK PRESERVE ROWS:在執行 ROLLBACK(或 ROLLBACK to SAVEPOINT)操作時,保留表中的所有行。
注意,BLOB、CLOB、DBCLOB、LONG VARCHAR、LONG VARGRAPHIC、XML、引用和結構化類型不能用作聲明式全局臨時表的列的數據類型。
按照以下步驟使用 DB2 GDTT:
步驟 1. 確保有用戶臨時表空間存在。如果沒有用戶臨時表空間,那麼使用以下語法執行 CREATE USER TEMPORARY TABLESPACE 語句:
CREATE USER TEMPORARY TABLESPACE usr_tbsp MANAGED BY SYSTEM USING
('c:tempusertempspace') ;
步驟 2. 使用前面提供的語法在應用程序中執行 DECLARE GLOBAL TEMPORARY TABLE 語句。例如:
清單 2. DGTT 聲明的示例
DECLARE GLOBAL TEMPORARY TABLE temp_proj
(projno CHAR(6), projname VARCHAR(24), proJSdate DATE, projedate DATE,)
WITH REPLACE
ON COMMIT PRESERVE ROWS
NOT LOGGED
IN usr_tbsp ;
聲明式臨時表的數據庫模式總是 SESSION。
步驟 3. 當在過程中引用臨時表時,需要在臨時表名前面加上模式名 SESSION。下面的示例演示臨時表的使用方法:
清單 3. 臨時表的使用示例
CREATE PROCEDURE DB2ADMIN.temp_table ( )
P1: BEGIN
DECLARE GLOBAL TEMPORARY TABLE temp1 AS
( SELECT deptnumb as dnum,
deptname as name,
manager as mgr
FROM org )
DEFINITION ONLY ON COMMIT PRESERVE ROWS;
BEGIN
DECLARE c1 CURSOR WITH RETURN FOR
SELECT dnum, mgr FROM SESSION.temp1;
INSERT INTO SESSION.temp1 (dnum, name, mgr)
(SELECT deptnumb, deptname, manager
FROM org);
OPEN c1;
END;
END
層次化查詢
在關系數據庫中表達層次化關系
當使用關系數據庫中的層次化數據時,獲取和顯示數據都比較困難。遞歸式 SQL 語句提供了一種使用這些復雜邏輯結構的方法。
在遞歸式 SQL 語句中,會對結果集重復應用一個 SQL 語句,以便生成進一步的結果。采用一種引用本身的通用表表達式構建這種 SQL 語句(即,它使用自己的定義)。這種查詢 “with (…) as tabname” 也稱為通用表表達式 (CTE)。
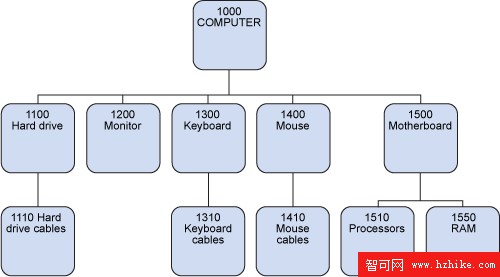
這種數據結構的示例往往包含很多數據。下面的表表示計算機硬件信息,這些信息形成一個層次結構。在此示例中,計算機包含硬盤驅動器、監視器、鍵盤、鼠標和主板等部件。部件本身可以分解為子部件或組件,比如主板包含處理器和 RAM。
表 1. bill_of_materials 表中的示例數據
ASSEMBLY_ID SUB_ASSEMBLY_ID ASSEMBLY_NM 1000 Computer 1000 1100 Hard Drive 1000 1200 Monitor 1000 1300 Keyboard 1000 1400 Mouse 1100 1110 Hard drive Cables 1300 1310 Keyboard Cables 1400 1410 Mouse 1000 1500 Motherboard 1500 1510 Processors 1500 1550 RAM
下面的語句執行一個遞歸式查詢。WITH 語句定義一個名為 ASSEMBLY 的臨時表。UNION ALL 的上半部分只被調用一次。它在配件表中填充五行,這五行的配件 ID 都是 1000。
UNION ALL 的下半部分遞歸地執行,直到沒有匹配為止。也就是說,這個遞歸式查詢逐行循環遍歷 bill_of_materials 表,創建最終的結果集,然後輸入給遞歸式查詢的下一次迭代。
最後,SELECT 語句返回剛才用 CTE 創建的臨時表 ASSEMBLY 中的行。
清單 4. WITH 語句
WITH assembly
(sub_assembly_id, assembly_nm, assembly_id) AS
(SELECT sub_assembly_id, assembly_nm, assembly_id
FROM bill_of_materials
WHERE assembly_id=1000
UNION ALL
SELECT child.sub_assembly_id,
child.assembly_nm,
child.assembly_id
FROM bill_of_materials child, assembly p
WHERE child.assembly_id = p.sub_assembly_id)
SELECT assembly_id, sub_assembly_id, assembly_nm from assembly;
WITH 語句返回的最終結果集如下:
清單 5. WITH 語句返回的最終結果集
ASSEMBLY_ID SUB_ASSEMBLY_ID ASSEMBLY_NM
1000 1100 Hard Drive
1000 1200 Monitor
1000 1300 Keyboard
1000 1400 Mouse
1000 1500 Motherboard
1100 1110 Hard drive Cables
1300 1310 Keyboard Cables
1400 1410 Mouse Cables
1500 1510 Processors
1500 1550 RAM
10 record(s) selected.
圖 1 給出這些結果的圖形化視圖。
圖 1. 層次化查詢的示例
MERGE 語句
使用 MERGE 語句組合有條件更新、插入或刪除操作
MERGE 語句 使用來自源表的數據更新目標表或可更新視圖。在一次操作期間,可以對目標表中與源表匹配的行進行更新或刪除,同時插入目標表中不存在的行。
例如,假設 EMPLOYEE 表是目標表,其中包含關於一家大公司的職員的最新信息。分支機構辦公室通過維護自己的 EMPLOYEE 表版本 MY_EMP 來更新本地職員記錄。通過使用 MERGE 語句,可以用 MY_EMP 表中的信息更新 EMPLOYEE 表,MY_EMP 表作為合並操作的源表。
下面的語句把職員編號為 000015 的新職員記錄插入 MY_EMP 表中。
清單 6. 插入新職員的記錄
INSERT INTO my_emp (empno, firstnme, midinit, lastname, workdept,
phoneno, hiredate, job, edlevel, sex, birthdate, salary)
VALUES ('000015', 'MARIO', 'M', 'MALFA', 'A00',
'6669', '05/05/2000', 'ANALYST', 15, 'M', '04/02/1973', 59000.00)
下面的語句把職員編號為 000010 的現有職員的更新工資數據插入 MY_EMP 表中。
INSERT INTO my_emp (empno, firstnme, midinit, lastname, edlevel, salary)
VALUES ('000010', 'CHRISTINE', 'I', 'HAAS', 18, 66600.00)
現在,插入的數據只存在於 MY_EMP 表中,因為它還沒有與 EMPLOYEE 表合並。清單 7 給出的 MERGE 語句獲取 MY_EMP 表的內容並把它們合並到 EMPLOYEE 表中。
清單 7. MERGE 語句
MERGE INTO employee AS e
USING (SELECT
empno, firstnme, midinit, lastname, workdept, phoneno,
hiredate, job, edlevel, sex, birthdate, salary
FROM my_emp) AS m
ON e.empno = m.empno
WHEN MATCHED THEN
UPDATE SET (salary) = (m.salary)
WHEN NOT MATCHED THEN
INSERT (empno, firstnme, midinit, lastname, workdept, phoneno,
hiredate, job, edlevel, sex, birthdate, salary)
VALUES (m.empno, m.firstnme, m.midinit, m.lastname,
m.workdept, m.phoneno, m.hiredate, m.job, m.edlevel,
m.sex, m.birthdate, m.salary)
這裡給源表和目標表分配了關聯名,從而避免搜索條件中的表引用出現歧義。此語句指定 MY_EMP 表中應該考慮的列。語句還指定在 MY_EMP 表中的行與 EMPLOYEE 表匹配和不匹配時分別執行的操作。
現在,對 EMPLOYEE 表執行以下查詢會返回職員 000015 的記錄:
SELECT * FROM employee WHERE empno = '000015'
以下查詢返回職員 000010 的記錄,其中的 SALARY 列包含更新後的值:
SELECT * FROM employee WHERE empno = '000010'
系統過程 ADMIN_CMD
DB2 在 SYSPROC 模式中提供 ADMIN_CMD 過程,從而允許使用 CALL 語句從應用程序或另一個過程直接運行管理命令。不能從 UDF 或觸發器調用此過程。
ADMIN_CMD 有一個 CLOB(2M) 類型的輸入參數,其中包含要執行的一個管理命令。調用此過程的語法如下: CALL ADMIN_CMD(command_string);
當前,此過程支持許多 DB2 v9.5 管理命令。下面是最常用的管理命令:
DESCRIBE
EXPORT
FORCE APPLICATION
IMPORT
LOAD
REORG INDEXES/TABLE
RUNSTATS
UPDATE DATABASE CONFIGURATION
在 IBM DB2 9.5 Information Center 上可以找到支持的命令的完整列表。
下面的示例演示此過程的使用方法:
清單 8. ADMIN_CMD 過程的使用示例
CREATE PROCEDURE test_admin_cmd ( )
P1: BEGIN
DECLARE sql_string VARCHAR(200);
SET sql_string ='LOAD FROM C:DB9.5_testorg_exp.txt OF DEL
METHOD P (1, 2, 3, 4, 5) INSERT INTO DB2ADMIN.ORG1
(DEPTNUMB, DEPTNAME, MANAGER, DIVISION, LOCATION)
COPY NO INDEXING MODE AUTOSELECT';
CALL SYSPROC.ADMIN_CMD(sql_string);
END P1
GET DIAGNOSTIC 語句
SQL PL 提供一個 GET DIAGNOSTICS 語句,用於獲取前面執行的 SQL 語句的相關信息。例如,如果需要查明一個 INSERT、DELETE 或 UPDATE 語句影響的行數,就可以使用帶 ROW_COUNT 選項的 GET DIAGNOSTICS 語句提供此信息。
清單 9 是 GET DIAGNOSTICS 語句的語法圖:
清單 9. GET DIAGNOSTICS 語句的語法
>>-GET DIAGNOSTICS---------------------------------------------->
>--+-SQL-variable-name--=--+-ROW_COUNT---------+-+-------------><
| '-DB2_RETURN_STATUS-' |
'-| condition-information |
-------------------'
condition-information
|--EXCEPTION--1------------------------------------------------->
.-,------------------------------------------.
V |
>----SQL-variable-name--=--+-MESSAGE_TEXT-----+-+---------------|
'-DB2_TOKEN_STRING-'
可以使用 GET DIAGNOSTICS 語句獲取以下信息:
前面執行的 SQL 語句處理的行數
與前一個 CALL 語句相關聯的過程返回的狀態值
前面執行的 SQL 語句返回的 DB2 錯誤或警告消息文本
SQL-variable 聲明取決於希望獲得的信息。如果要存儲 ROW_COUNT 或 DB2_RETURN_STATUS,就需??把它聲明為 INTEGER;如果要存儲錯誤或警告消息,就應該聲明為 varchar(70)。
請注意,GET DIAGNOSTICS 語句不會改變特殊變量 SQLSTATE 和 SQLCODE 的內容。
下面的示例演示 GET DIAGNOSTICS 語句的使用方法:
清單 10. 通過 Get DIAGNOSTICS 語句獲取 ROW_COUNT
CREATE PROCEDURE UPDATE_RCOUNT(sales_corr INT, qtr int, OUT row_updated INT)
P1: BEGIN
UPDATE SALESBYQUARTER
SET sales = sales+sales_corr
WHERE y < year(current date)
and q = qtr;
GET DIAGNOSTICS row_updated = ROW_COUNT;
END P1
清單 11. 通過 GET DIAGNOSTICS 語句獲取消息文本
CREATE PROCEDURE mess_text1 (num int, new_status varchar(10),
OUT p_err_mess varchar(70))
P1: BEGIN
DECLARE SQLCODE INTEGER default 0;
DECLARE SQLSTATE CHAR(5) default '';
DECLARE v_trunc int default 0;
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION
BEGIN
GET DIAGNOSTICS EXCEPTION 1 p_err_mess = MESSAGE_TEXT;
SET v_trunc = 2;
END;
INSERT INTO tab1 VALUES (num, new_status);
RETURN v_trunc;
END P1
DB2_RETURN_STATUS 返回調用的 SQL 過程的狀態值。如果調用的過程成功執行,它會返回零值,否則返回表示失敗的正值。
清單 12. 通過 GET DIAGNOSTICS 語句獲取狀態值
CREATE PROCEDURE myproc1 ()
A1:BEGIN
DECLARE RETVAL INTEGER DEFAULT 0;
…
CALL MYPROC2;
GET DIAGNOSTICS RETVAL = DB2_RETURN_STATUS;
IF RETVAL <> 0 THEN
…
LEAVE A1;
ELSE
…
END IF;
END A1
保存點
保存點提供一種在工作單元(事務)內實現子事務的方法。實現的辦法是在事務內創建多個以後可以引用的引用點(保存點)。例如,在一個應用程序中,可以設置多個保存點;在創建保存點之後的任何時候,都可以把工作回滾到保存點,而不影響在此保存點之前執行的任何工作。
下面是設置保存點的語法:
SAVEPOINT savepoint-name ON ROLLBACK RETAIN CURSORS
下面給出一個對嵌套的保存點執行回滾操作的示例。首先,創建一個名為 T1 的表。然後,在 T1 表中插入一行。執行插入之後,創建第一個保存點 (SAVEPOINT1)。創建這個保存點之後,在 T1 表中插入另一行並創建另一個保存點 (SAVEPOINT2)。然後,在 T1 表中插入第三行。然後,創建最後一個保存點 (SAVEPOINTS3)。最後,在 SAVEPOINT3 後面插入另一行。現在,在 T1 表中有四行(‘A’、‘B’、‘C’ 和 ‘D’)。
現在,回滾到 savepoint3,這會從 T1 表中刪除 ‘D’ 行。接下來,回滾到 savepoint1,這會刪除 ‘C’ 和 ‘B’ 行。然後,提交事務,這會導致保存點不再可用。然後,在 T1 表中插入 ‘E’ 行。現在,在 T1 表中有兩行(‘A’ 和 ‘E’)。
清單 13 給出實現這些操作的命令。
清單 13. 使用保存點
CREATE PROCEDURE p1()
BEGIN
CREATE TABLE T1 (C1 CHAR);
INSERT INTO T1 VALUES ('A');
SAVEPOINT SAVEPOINT1 ON ROLLBACK RETAIN CURSORS;
INSERT INTO T1 VALUES ('B');
SAVEPOINT SAVEPOINT2 ON ROLLBACK RETAIN CURSORS;
INSERT INTO T1 VALUES ('C');
SAVEPOINT SAVEPOINT3 ON ROLLBACK RETAIN CURSORS;
INSERT INTO T1 VALUES ('D');
ROLLBACK TO SAVEPOINT SAVEPOINT3;
ROLLBACK TO SAVEPOINT SAVEPOINT1;
COMMIT WORK;
INSERT INTO T1 VALUES ('E');
END_cnnew1@
PureXML 和存儲過程
DB2 9.5 是一種混合型數據庫,它支持 XML 數據類型的列以及用於操作 XML 數據的方法和函數。SQL 過程支持 XML 數據類型的參數和變量。這些變量還可以作為參數傳遞給 XMLEXISTS、XMLQUERY 和 XMLTABLE 表達式中的 XQuery 表達式。
下面的存儲過程返回的結果集包含一個關系列和來自 XML 列的屬性(客戶名):
清單 14. 存儲過程示例
CREATE PROCEDURE proc_wXML ( )
DYNAMIC RESULT SETS 1
------------------------------------------------------------------------
-- SQL Stored Procedure
------------------------------------------------------------------------
P1: BEGIN
-- Declare cursor
DECLARE cursor1 CURSOR WITH RETURN FOR
SELECT cid, XMLquery('declare default element namespace
"http://posample.org";
$cu/customerinfo/name/text()' passing d.info as "cu")
from customer d;
-- Cursor left open for clIEnt application
OPEN cursor1;
END P1
The next procedure is accepting XML as input variable along with integer parameter
and inset row into CUSTOMER table that has INFO column declared as XML:
CREATE PROCEDURE PROC_INS_XML1 ( v_cid int, v_info XML)
DYNAMIC RESULT SETS 1
------------------------------------------------------------------------
-- SQL Stored Procedure
------------------------------------------------------------------------
P1: BEGIN
INSERT INTO CUSTOMER (CID, INFO)
VALUES (v_cid, v_info);
END P1
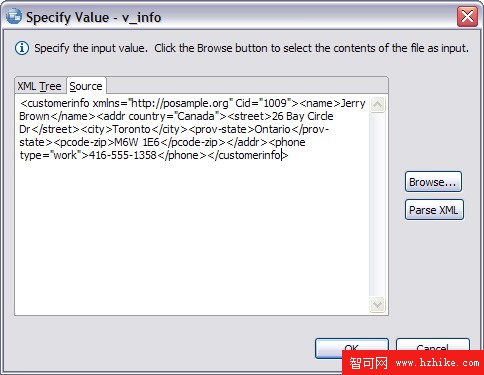
如果使用 IBM Data Studio 運行此過程,可以把 XML 直接解析為輸入值,見圖 2。
圖 2. XML 字符串用作輸入參數
結束語
在本教程中,您學習了如何在存儲過程中聲明和使用全局臨時表。還學習了如何使用保存點和 GET DIAGNOSTICS 語句改進數據庫應用程序。另外,還學習了如何用 DB2 層次化查詢和 MERGE 功能幫助實現復雜的業務解決方案。在數據庫開發中使用 XML 技術可以顯著簡化復雜的業務邏輯。掌握這些高級特性有助於您通過 735 認證考試。