有些數據在存儲時並不需要占用一個完整的字節,只需要占用一個或幾個二進制位即可。例如開關只有通電和斷電兩種狀態,用 0 和 1 表示足以,也就是用一個二進位。正是基於這種考慮,C語言又提供了一種叫做位域的數據結構。
在結構體定義時,我們可以指定某個成員變量所占用的二進制位數(Bit),這就是位域。請看下面的例子:
struct bs{
unsigned m;
unsigned n: 4;
unsigned char ch: 6;
}
:後面的數字用來限定成員變量占用的位數。成員 m 沒有限制,根據數據類型即可推算出它占用 4 個字節(Byte)的內存。成員 n、ch 被
:後面的數字限制,不能再根據數據類型計算長度,它們分別占用 4、6 位(Bit)的內存。
n、ch 的取值范圍非常有限,數據稍微大些就會發生溢出,請看下面的例子:
#include <stdio.h>
int main(){
struct bs{
unsigned m;
unsigned n: 4;
unsigned char ch: 6;
} a = { 0xad, 0xE, '$'};
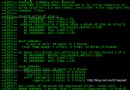
//第一次輸出
printf("%#x, %#x, %c\n", a.m, a.n, a.ch);
//更改值後再次輸出
a.m = 0xb8901c;
a.n = 0x2d;
a.ch = 'z';
printf("%#x, %#x, %c\n", a.m, a.n, a.ch);
return 0;
}
運行結果:
0xad, 0xe, $
0xb8901c, 0xd, :
對於 n 和 ch,第一次輸出的數據是完整的,第二次輸出的數據是殘缺的。
第一次輸出時,n、ch 的值分別是 0xE、0x24('$' 對應的 ASCII 碼為 0x24),換算成二進制是 1110、10 0100,都沒有超出限定的位數,能夠正常輸出。
第二次輸出時,n、ch 的值變為 0x2d、0x7a('z' 對應的 ASCII 碼為 0x7a),換算成二進制分別是 10 1101、111 1010,都超出了限定的位數。超出部分被直接截去,剩下 1101、11 1010,換算成十六進制為 0xd、0x3a(0x3a 對應的字符是 :)。
C語言標准規定,位域的寬度不能超過它所依附的數據類型的長度。通俗地講,成員變量都是有類型的,這個類型限制了成員變量的最大長度,
:後面的數字不能超過這個長度。
例如上面的 bs,n 的類型是 unsigned int,長度為 4 個字節,共計 32 位,那麼 n 後面的數字就不能超過 32;ch 的類型是 unsigned char,長度為 1 個字節,共計 8 位,那麼 ch 後面的數字就不能超過 8。
我們可以這樣認為,位域技術就是在成員變量所占用的內存中選出一部分位寬來存儲數據。
C語言標准還規定,只有有限的幾種數據類型可以用於位域。在 ANSI C 中,這幾種數據類型是 int、signed int 和 unsigned int(int 默認就是 signed int);到了 C99,_Bool 也被支持了。
關於C語言標准以及 ANSI C 和 C99 的區別,我們已在VIP教程《C語言的兩套標准》中進行了講解。
但編譯器在具體實現時都進行了擴展,額外支持了 char、signed char、unsigned char 以及 enum 類型,所以上面的代碼雖然不符合C語言標准,但它依然能夠被編譯器支持。
位域的存儲
C語言標准並沒有規定位域的具體存儲方式,不同的編譯器有不同的實現,但它們都盡量壓縮存儲空間。
位域的具體存儲規則如下:
1) 當相鄰成員的類型相同時,如果它們的位寬之和小於類型的 sizeof 大小,那麼後面的成員緊鄰前一個成員存儲,直到不能容納為止;如果它們的位寬之和大於類型的 sizeof 大小,那麼後面的成員將從新的存儲單元開始,其偏移量為類型大小的整數倍。
以下面的位域 bs 為例:
#include <stdio.h>
int main(){
struct bs{
unsigned m: 6;
unsigned n: 12;
unsigned p: 4;
};
printf("%d\n", sizeof(struct bs));
return 0;
}
運行結果:
4
m、n、p 的類型都是 unsigned int,sizeof 的結果為 4 個字節(Byte),也即 32 個位(Bit)。m、n、p 的位寬之和為 6+12+4 = 22,小於 32,所以它們會挨著存儲,中間沒有縫隙。
sizeof(struct bs) 的大小之所以為 4,而不是 3,是因為要將內存對齊到 4 個字節,以便提高存取效率,這將在《C語言和內存》專題的《C語言內存對齊,提高尋址效率》一節中詳細講解。
如果將成員 m 的位寬改為 22,那麼輸出結果將會是 8,因為 22+12 = 34,大於 32,n 會從新的位置開始存儲,相對 m 的偏移量是 sizeof(unsigned int),也即 4 個字節。
如果再將成員 p 的位寬也改為 22,那麼輸出結果將會是 12,三個成員都不會挨著存儲。
2) 當相鄰成員的類型不同時,不同的編譯器有不同的實現方案,GCC 會壓縮存儲,而 VC/VS 不會。
請看下面的位域 bs:
#include <stdio.h>
int main(){
struct bs{
unsigned m: 12;
unsigned char ch: 4;
unsigned p: 4;
};
printf("%d\n", sizeof(struct bs));
return 0;
}
在 GCC 下的運行結果為 4,三個成員挨著存儲;在 VC/VS 下的運行結果為 12,三個成員按照各自的類型存儲(與不指定位寬時的存儲方式相同)。
m 、ch、p 的長度分別是 4、1、4 個字節,共計占用 9 個字節內存,為什麼在 VC/VS 下的輸出結果卻是 12 呢?這個疑問將在《C語言和內存》專題的《C語言內存對齊,提高尋址效率》一節中為您解開。
3) 如果成員之間穿插著非位域成員,那麼不會進行壓縮。例如對於下面的 bs:
struct bs{
unsigned m: 12;
unsigned ch;
unsigned p: 4;
};
在各個編譯器下 sizeof 的結果都是 12。
通過上面的分析,我們發現位域成員往往不占用完整的字節,有時候也不處於字節的開頭位置,因此使用
&獲取位域成員的地址是沒有意義的,C語言也禁止這樣做。地址是字節(Byte)的編號,而不是位(Bit)的編號。
無名位域
位域成員可以沒有名稱,只給出數據類型和位寬,如下所示:
struct bs{
int m: 12;
int : 20; //該位域成員不能使用
int n: 4;
};
無名位域一般用來作填充或者調整成員位置。因為沒有名稱,無名位域不能使用。
上面的例子中,如果沒有位寬為 20 的無名成員,m、n 將會挨著存儲,sizeof(struct bs) 的結果為 4;有了這 20 位作為填充,m、n 將分開存儲,sizeof(struct bs) 的結果為 8。