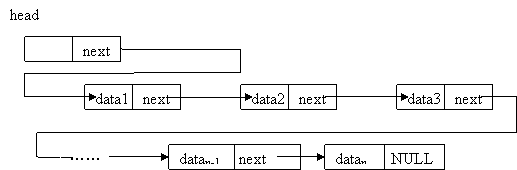
樹
因為現實世界中存在這“樹”這種結構——族譜、等級制度、目錄分類等等,而為了研究這類問題,必須能夠將樹儲存,而如何儲存將取決於所需要的操作。這裡有個問題,是否答應存在空樹。
![]()
![]()
![]()
![]()
<!-- frame contents -->
<!-- /frame contents -->
![]()
![]()
![]()
![]()
有些書認為樹都是非空的,因為樹表示的是一種現實結構,而0不是自然數;我用過的教科書都是說可以有空樹,當然是為了和二叉樹統一。這個沒有什麼原則上的差別,反正就是一種習慣。
二叉樹
二叉樹可以說是人們假想的一個模型,因此,答應有空的二叉樹是無爭議的。二叉樹是有序的,左邊有一個孩子和右邊有一個的二叉樹是不同的兩棵樹。做這個規定,是因為人們賦予了左孩子和右孩子不同的意義,在二叉樹的各種應用中,你將會清楚的看到。下面只講解鏈式結構。看各種講數據結構的書,你會發現一個有趣的現象:在二叉樹這裡,基本操作有計算樹高、各種遍歷,就是沒有插入、刪除——那樹是怎麼建立起來的?其實這很好理解,對於非線性的樹結構,插入刪除操作不在一定的法則規定下,是毫無意義的。因此,只有在具體的應用中,才會有插入刪除操作。
節點結構
數據域、左指針、右指針肯定是必須的。除非很少用到節點的雙親,或者是資源緊張,建議附加一個雙親指針,這將會給很多算法帶來方便,尤其是在這個“空間換時間”的時代。
template <class T>
strUCt BTNode
{
BTNode(T data = T(), BTNode<T>* left = NULL, BTNode<T>* right = NULL, BTNode<T>* parent = NULL)
: data(data), left(left), right(right), parent(parent) {}
BTNode<T> *left, *right, *parent;
T data;
};
基本的二叉樹類
template <class T>
class BTree
{
public:
BTree(BTNode<T> *root = NULL) : root(root) {}
~BTree() { MakeEmpty(); }
void MakeEmpty() { destroy(root); root = NULL; }
protected:
BTNode<T> *root;
private:
void destroy(BTNode<T>* p)
{
if (p)
{
destroy(p->left);
destroy(p->right);
delete p;
}
}
}
二叉樹的遍歷
基本上有4種遍歷方法,先、中、後根,逐層。當初我對這個很迷惑,搞這麼多干什麼?到了後面才明白,這是不同的應用需要的。例如,判定兩個二叉樹是否相等,只要子樹根節點不同,那麼就不等,顯然這時要用先序遍歷;而刪除二叉樹,必須先刪除左右子樹,然後才能刪除根節點,這時就要用後序遍歷。
實際上,搞這麼多遍歷方法,根本原因是在內存中儲存的樹是非線性結構。對於用數組儲存的二叉樹,這些名目繁多的方法都是沒有必要的。利用C++的封裝和重載特性,這些遍歷方法能很清楚的表達。
1. 前序遍歷
public:
void PreOrder(void (*visit)(T &data) = print) { PreOrder(root, visit); }
private:
void PreOrder(BTNode<T>* p, void (*visit)(T &data))
{
if (p){ visit(p->data); PreOrder(p->left, visit); PreOrder(p->right, visit); }
}
2. 中序遍歷
public:
void InOrder(void (*visit)(T &data) = print) { InOrder(root, visit); }
private:
void InOrder(BTNode<T>* p, void (*visit)(T &data))
{
if (p){ InOrder(p->left, visit); visit(p->data); InOrder(p->right, visit); }
}
3. 後序遍歷
public:
void PostOrder(void (*visit)(T &data) = print) { PostOrder(root, visit); }
private:
void PostOrder(BTNode<T>* p, void (*visit)(T &data))
{
if (p){ PostOrder(p->left, visit); PostOrder(p->right, visit); visit(p->data); }
}
4. 層次遍歷
void LevelOrder(void (*visit)(T &data) = print)
{
queue< BTNode<T>* > a; BTNode<T>* p = root;//記得#include<queue>
while (p)
{
visit(p->data);
if (p->left) a.push(p->left); if (p->right) a.push(p->right);
if (a.empty()) break; p = a.front(); a.pop();
}
}
附注:缺省的visit函數print如下
private:
static void print(T &data) { cout << data << ' ';}
5. 不用棧的非遞歸中序遍歷
當有parent指針時,可以不用棧實現非遞歸的中序遍歷,書上提到了有這種方法,但沒給出例程。
public:
BTNode<T>* next()
{
if(!current) return NULL;
if (current->right) { current = current->right; while (current->left) current = current->left; }
else
{
BTNode<T>* y = current->parent;
while (y && current == y->right) {current = y; y = y->parent; }
current = y;
}
return current;
}
private:
BTNode<T>* current;
上面的函數能使current指針向前移動一個位置,假如要遍歷整棵二叉樹,需要使current指向中序序列的第一個節點,例如下面的成員函數:
public:
void first() { current = root; while (current->left) current = current->left; }
更多內容請看C/C++技術專題 數據結構 數據結構教程專題,或 線索化二叉樹
這是數據結構課程裡第一個碰到的難點,不知道你是不是這樣看,反正我當初是費了不少腦細胞——當然,惱人的矩陣壓縮和相關的加法乘法運算不在考慮之列。
![]()
![]()
![]()
![]()
<!-- frame contents -->
<!-- /frame contents -->
![]()
![]()
![]()
![]()
我費了不少腦細胞是因為思考:他們干什麼呢?很欣喜的看到在這本黃皮書上,這章被打了*號,雖然我不確定作者是不是跟我一個想法——線索化二叉樹在現在的PC上是毫無用處的!——不知我做了這個結論是不是會被人罵死。
為了證實這個結論,我們來看看線索化二叉樹提出的緣由:第一,我們想用比較少的時間,尋找二叉樹某一個遍歷線性序列的前驅或者後繼。當然,這樣的操作很頻繁的時候,做這方面的改善才是有意義的。第二,二叉樹的葉子節點還有兩個指針域沒有用,可以節省內存。說真的,提出線索化二叉樹這樣的構思真的很精巧,完全做到了“廢物利用”——這個人真應該投身環保事業。但在計算機這個死板的東西身上,人們的精巧構思往往都是不能實現的——為了速度,計算機的各個部件都是整潔劃一的,而構思的精巧往往都是建立在組成的復雜上的。
我們來看看線索化二叉樹究竟能不能達到上面的兩個目標。
求遍歷後的線性序列的前驅和後繼。前序線索化能依次找到後繼,但是前驅需要求雙親;中序線索化前驅和後繼都不需要求雙親,但是都不很直接;後序線索化能依次找到前驅,但是後繼需要求雙親。可以看出,線索化成中序是最佳的選擇,基本上算是達到了要求。
節省內存。添加了兩個標志位,問題是這兩個位怎麼儲存?即使是在支持位存儲的CPU上,也是不能拿位存儲器來存的,第一是因為結構體成員的地址是在一起的,第二是位存儲器的數目是有限的。因此,最少需要1個字節來儲存這兩個標志位。而為了速度和移植,一般來說,內存是要對齊的,實際上根本就沒節省內存!然而,當這個空間用來儲存雙親指針時,帶來的方便絕對不是線索化所能比擬的,前面已經給出了無棧的非遞歸遍歷。並且,在線索化二叉樹上插入刪除操作附加的代價太大。
綜上,線索化最好是中序線索化(前序後序線索化後還得用棧,何必要線索化呢),附加的標志域空間至少1個字節,在32位的CPU會要求對齊到4字節,還不如存儲一個雙親指針,同樣能達到中序線索化的目的,並且能帶來其他的好處。所以,線索化二叉樹在現在的PC上是毫無用處的!
由於對其他體系不太了解,以下觀點姑妄聽之。在內存空間非常充裕的現在,一個節點省2~3個字節實在是沒什麼意思(實際上由於對齊還省不出來);而在內存非常寶貴的地方(比如單片機),會盡量避免使用樹結構——利用其他的方法。所以,現在看來,線索化二叉樹真的是毫無用處了。
二叉搜索樹
這恐怕是二叉樹最重要的一個應用了。它的構想實際是個很自然的事情——查找值比當前節點小轉左,大轉右,等則查到,到頭了就是沒找著。越自然的東西越好理解,也就越不需要我廢話。在給出BST的實現之前,我們要在二叉樹的類中添加一個打印樹狀結構的成員函數,這樣,就能清楚的看出插入和刪除過程。
public:
void print()
{
queue< BTNode<T>* > a; queue<bool> flag; ofstream outfile("out.txt");
BTNode<T>* p = root; BTNode<T> zero; bool v = true;
int i = 1, level = 0, h = height();
while (i < 2<<h)
{
if (i == 1<<level)
{
cout << endl << setw(2 <<(h - level)); level++;
if (v) cout << p->data;
else cout << ' ';
}
else
{
cout << setw(4 <<(h - level + 1));
if (v) cout << p->data;
else cout << " ";
}
if (p->left) { a.push(p->left); flag.push(true); }
else { a.push(&zero); flag.push(false); }
if (p->right) { a.push(p->right); flag.push(true); }
else { a.push(&zero); flag.push(false); }
p = a.front(); a.pop(); v = flag.front(); flag.pop(); i++;
}
cout << endl;
}
打印樹狀結構的核心是按層次遍歷二叉樹,但是,二叉樹有許多節點缺左或右子樹,連帶的越到下面空隙越大。為了按照樹的結構打印,必須把二叉樹補成完全二叉樹,這樣下面的節點就知道放在什麼位置了——a.push(&zero);但是這樣的節點不能讓它打印出來,所以對應每個節點,有一個是否打印的標志,按理說pair結構很合適,為了簡單我用了並列的兩個隊列,一個放節點指針——a,一個放打印標志——flag。這樣一來,循環結束的標志就不能是隊列空——永遠都不可能空,碰到NULL就補一個節點——而是變成了到了滿二叉樹的最後一個節點2^(height+1)-1。——黃皮書對於樹高的定義是,空樹為的高度為-1。
對於輸出格式,注重的是到了第1、2、4、8號節點要換行,並且在同一行中,第一個節點的域寬是後序節點的一半。上面的函數在樹的層次少於等於5(height<=4)的時候能正常顯示,再多的話就必須輸出到文件中去ofstream outfile("out.txt");——假如層次再多的話,打印出來也沒什麼意義了。
更多內容請看C/C++技術專題 數據結構 數據結構教程專題,或
二叉搜索樹的實現
實際上就是在二叉樹的基礎上增加了插入、刪除、查找。
#include "BaseTree.h"
template <class T>
class BSTree : public BTree<T>
{
public:
BTNode<T>* &find(const T &data)
{
BTNode<T>** p = &root; current = NULL;
while(*p)
{
if ((*p)->data == data) break;
if ((*p)->data < data) { current = *p; p = &((*p)->right); }
else { current = *p; p = &((*p)->left); }
}
return *p;
}
bool insert(const T &data)
{
BTNode<T>* &p = find(data); if (p) return false;
p = new BTNode<T>(data, NULL, NULL, current); return true;
}
bool remove(const T &data)
{
return remove(find(data));
}
private:
bool remove(BTNode<T>* &p)
{
if (!p) return false; BTNode<T>* t = p;
if (!p->left !p->right)
{
if (!p->left) p = p->right; else p = p->left;
if (p) p->parent = current;
delete t; return true;
}
t=p->right;while(t->left) t=t->left;p->data=t->data;current=t->parent;
return remove(current->left==t?current->left:current->right);
}
};
以上代碼有點費解,有必要說明一下——非線性鏈式結構操作的實現都是很讓人費神。insert和remove都是以find為基礎的,因此必須讓find能最大限度的被這兩個操作利用。
1、對於insert,需要修改查找失敗時的指針內容,顯然這是個內部指針(在雙親節點的內部,而不是象root和current那樣在節點外面指向節點),這就要求find返回一個內部指針的引用。但是C++的引用綁定到一個對象之後,就不能再改變了,因此在find內部的實現是一個二重指針。insert操作還需要修改插入的新節點的parent指針域,因此在find中要產生一個能被insert訪問的指向find返回值所在節點的指針,這裡用的是current。實際上find返回的指針引用不是current->left就是current->right。這樣一來,insert的實現就非常簡單了。
2、對於remove,需要修改查找成功時的指針內容,同樣是個內部指針。在find的基礎上,很輕易就能得到這個內部指針的引用(BTNode<T>* &p = find(data)。
在p->left和p->right中至少有一個為NULL的情況下,假如p->left ==NULL,那麼就重連右子樹p = p->right,反之,重連左子樹p = p->left。注重,左右子樹全空的情況也包含在這兩個操作中了——在p->left ==NULL的時候重連右子樹,而這時p->right也是NULL——因此不必列出來。假如重連後p不為空,需要修改p->parent = current。
若p->left和p->right都不為空,可以轉化為有一個為空。例如一個中序有序序列[1,2,3,4,5],假設3既有左子樹又有右子樹,那麼它的前驅2一定缺右子樹,後繼4一定缺少左子樹。【注1】這樣一來刪除節點3就等效成從[1,2,3(4),4,5]刪除節點4。這樣就可以利用上面的在p->left和p->right中至少有一個為NULL的情況下的方法了。還是由於C++的引用不能改變綁定對象,這裡是用利用遞歸來解決的,還好最多只遞歸一次。假如用二重指針又是滿天星星了,這就是明明是尾遞歸卻沒有消去的原因。
【注1】這是因為,假如3既有左子樹又有右子樹,那麼2一定在3的左子樹上,4一定在3的右子樹上;假如2有右子樹,那麼在2和3之間還應該有一個節點;假如4有左子樹,那麼3和4之間也應該還有一個節點。
【閒話】上面關於remove操作p->left和p->right都不為空的處理方法的講解,源於嚴蔚敏老師的課件,看完後我豁然開朗,真不知道為什麼她自己那本《數據結構(C語言版)》這裡寫的那麼難懂,我是死活沒看明白。
更多內容請看C/C++技術專題 數據結構 數據結構教程專題,或
遞歸遍歷與非遞歸遍歷
在沒有樹的慨念,對遞歸的理解總是很困難,因為不能提出有說服力的例子,只是闡述了“遞歸是一種思想”。但只要能能讓你建立“遞歸是一種思想”這個觀念,我的努力就沒有白費。現在,講完了二叉搜索樹,終於有了能說明問題的例子了。按照前面提供的代碼,應該能調試通過下面的程序。
#include <iostream>
using namespace std;
#include <stdlib.h>
#include <time.h>
#include "BSTree.h"
#include "Timer.h"
#define random(num) (rand() % (num))
#define randomize() srand((unsigned)time(NULL))
#define NODENUM 200000//node number
int data[NODENUM];
void zero(int &t) { t = 0; }
int main()
{
BSTree<int> a; Timer t; randomize(); int i;
for (i = 0; i < NODENUM; i++) data[i] = i;
for (i = 0; i < NODENUM; i++) swap(data[i], data[random(NODENUM)]);//random swap
t.start(); for (i = 0; i < NODENUM; i++) a.insert(data[i]);
cout << "Insert time: " << t.GetTime() << " Node number: " << NODENUM << endl;
t.start(); for (a.first(); a.get() != NULL; a.next()) a.get()->data = 0;
cout << "Non-Stack time: " << t.GetTime() << endl;
t.start(); a.LevelOrder(zero); cout << "LevlOrder time: " << t.GetTime() << endl;
t.start(); a.PreOrder(zero); cout << " PreOrder time: " << t.GetTime() << endl;
t.start(); a.InOrder(zero); cout << " InOrder time: " << t.GetTime() << endl;
t.start(); a.PostOrder(zero); cout << "PostOrder time: " << t.GetTime() << endl;
return 0;
}
以下是timer.h的內容
#ifndef Timer_H
#define Timer_H
#include <windows.h>
class Timer
{
public:
Timer() { QueryPerformanceFrequency(&Frequency); }
inline void start() { QueryPerformanceCounter(&timerB); }
inline double GetTime()
{
QueryPerformanceCounter(&timerE);
return (double)(timerE.QuadPart - timerB.QuadPart) / (double)Frequency.QuadPart * 1000.0;
}
private:
LARGE_INTEGER timerB, timerE, Frequency;
};
#endif
上面的程序中,層次遍歷用到的是隊列,這應該可以代表用棧消解遞歸的情況,在我的機器C500上運行的結果是:
Insert time: 868.818 Node number: 200000
Non-Stack time: 130.811
LevlOrder time: 148.438
PreOrder time: 125.47
InOrder time: 129.125
PostOrder time: 130.914
以上是VC6的release版的結果,時間單位是ms,不說明會有人認為是死機了,^_^。可以看出,遞歸遍歷實際上並不慢,相反,更快一些,而debug版的結果是這樣的:
Insert time: 1355.69 Node number: 200000
Non-Stack time: 207.086
LevlOrder time: 766.023
PreOrder time: 183.287
InOrder time: 179.835
PostOrder time: 190.674
更多內容請看C/C++技術專題 數據結構 數據結構教程專題,或 遞歸遍歷的速度是最快的
這恐怕是上面結果得出的最直接的結論。
![]()
![]()
![]()
![]()
<!-- frame contents -->
<!-- /frame contents -->
![]()
![]()
![]()
![]()
不知從哪聽來的觀點“遞歸的速度慢,為了提高速度,應該用棧消解遞歸”,證據就是斐波那契數列的計算,遺憾的是斐波那契數列的非遞歸算法是循環迭代,不是棧消解;假如他真的拿棧來模擬,他就會發現,其實用棧的更慢。
我們來看看為什麼。遞歸的實現是將參數壓棧,然後call自身,最後按層返回,一系列的動作是在堆棧上操作的,用的是push、pop、call、ret之類的指令。而用ADT棧來模擬遞歸調用,實現的還是上述指令的功能,不同的是那些指令對照的ADT實現可就不只是一條指令了。誰都明白模擬的執行效率肯定比真實的差,怎麼會在這個問題上就犯糊塗了呢?
當然,你非要在visit函數中加入類似這樣的istream file1(“input.txt”),然後在用棧模擬的把這個放在循環的外面,最後你說,棧模擬的比遞歸的快,我也無話可說——曾經就見過一個人,http://www.csdn.net/Develop/Read_Article.ASP?Id=18342將數據庫連接放在visit函數裡面,然後說遞歸的速度慢。
假如一個遞歸過程用非遞歸的方法實現後,速度提高了,那只是因為遞歸做了一些無用功。比如用循環消解的尾遞歸,是多了無用的壓棧和出棧才使速度受損的;斐波那契數列計算的遞歸改循環迭代所帶來的速度大幅提升,是因為改掉了重復計算的毛病。假使一個遞歸過程必須要用棧才能消解,那麼,完全模擬後的結果根本就不會對速度有任何提升,只會減慢;假如你改完後速度提升了,那只證實你的遞歸函數寫的有問題,例如多了許多重復操作——打開關閉文件、連接斷開數據庫,而這些完全可以放到遞歸外面。遞歸方法本身是簡潔高效的,只是使用的人不注重使用方法。
這麼看來,研究遞歸的棧消解似乎是無用的,其實不然,用棧模擬遞歸還是有點意義的,只是並不大,下面將給出示例來說明。
棧模擬遞歸的好處是節省了堆棧
將上面的程序//node number那行的數值改為15000——不改沒反應了別找我,將//random swap那行注釋掉,運行debug版,耐心的等30秒,就會拋異常了,最後的輸出結果是這樣的:
Insert time: 27555.5 Node number: 15000
Non-Stack time: 16.858
LevlOrder time: 251.036
這只能說明堆棧溢出了。你可以看到層次遍歷還能工作(由此類推,棧模擬的也能工作),但是遞歸的不能工作了。這是因為和總的內存空間比起來,堆棧空間是很少的,假如遞歸的層次過深,堆棧就溢出了。所以,假如你預先感到遞歸的層次可能過深,你就要考慮用棧來消解了。
然而,假如你必須用遞歸,而遞歸的層次深到連堆棧都溢出了,那肯定是你的算法有問題,或者是那個程序根本不適合在PC上運行——運行起來就象死機了,這樣的程序誰敢用?所以說用棧模擬遞歸是有意義的,但是不大,因為很少用到。
對於樹結構來說,假如沒有雙親指針,那麼遍歷時的遞歸是必須的,與其搞什麼棧消解不如添加一個雙親指針,這實際上也是用堆空間換取堆棧空間的一個方法,只是比ADT棧來得直接、高效罷了。
綜上,遞歸的棧消解,實際上只能節省堆棧空間,不僅不會提高速度,相反卻會降低——天下哪有白吃的午餐,既省了堆棧空間還能提高速度。那些“棧消解遞歸能提高速度”的謠傳只是對“消除尾遞歸能提高速度”的不負責任的引申,然而一群人以訛傳訛,真就像是那麼回事了,這就叫三人成虎。等我這時候再回過頭看教科書,竟然沒看見一本書上寫著“棧消解遞歸能提高速度”。真的,以前一直被誤導了,還不知道是被誰誤導的——書上根本就沒有寫。
另外的結論
對比上面兩組結果,可以看到插入15000個節點比200000個節點消耗的時間還多,其原因就是插入數據的順序不同,從而導致了find的效率不同。隨機的順序大致能保證樹的左右子樹分布均勻,而有序的序列將使樹退化成單支的鏈表,從而使得O(logN)的時間復雜度變成了O(N)。同時,這也是為什麼200000個節點的樹遞歸遍歷還能工作,而遞歸遍歷15000個節點的樹堆棧就溢出了——遞歸的每一層對應的節點太少了。
為了提高find的效率,同時也是使樹的遞歸遍歷方法的使用更為寬泛,有必要研究如何能使樹的高度降低,這就是下面將要講到的平衡樹的來由。
更多內容請看C/C++技術專題 數據結構 數據結構教程專題,或