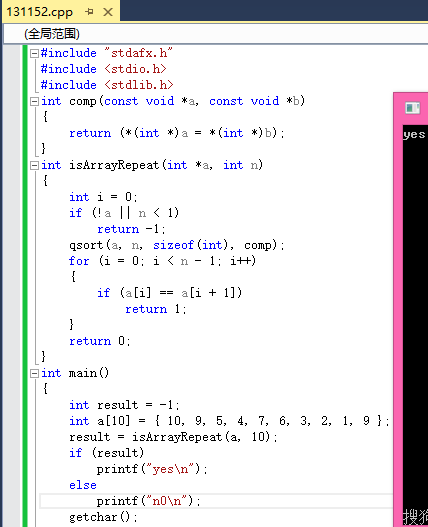
之前對最小生成樹Prim算法進行了一定的總結,並給出了代碼實現,詳見:http://www.cnblogs.com/dzkang2011/p/prim_1.html
一、介紹
由於忙於各類事務,在算法方面的學習有所停滯,現在將求最小生成樹的另外一種算法補上,也就是Kruskal算法。有關最小生成樹算法正確性的證明見上面鏈接。
Kruskal算法是一種實現起來較為簡單,比較容易理解的算法,在圖較為稀疏時能夠獲得很好的性能,但當圖較為稠密時(|E|>>|V|)性能便不如Prim算法。後面我們會根據實際代碼對Kruskal算法的時間復雜度進行分析。
Krusksl算法采用並查集(算法導論上的表示為不相交集合)實現。初始時,我們的所有頂點都構成單獨的一棵樹,也就是說由|V|棵樹組成的森林。算法首先要做的是,將所有的邊,按權值大小進行非降序排列。然後,按照權值從小到大來選擇邊,若該邊的兩個端點不在一棵樹中,則將他們合並,並將該邊置於最小生成樹中。一直訪問完所有的邊為止。可以看出Kruskal算法屬於一種貪心算法,而且能保證找到全局最優解。算法理解相應簡單,我們不給出相應的證明,有興趣的可以去鑽研一下算法導論。
二、偽代碼
算法的偽代碼如下,其中A保存最小生成樹,MAKE-SET(v)表示構造一棵只有頂點v的樹,FIND-SET(u)表示找u所在樹的根節點,Union(u, v)表示合並u和v的所在樹:
MST-KRUSKAL(G, W)
A←∅
for each vertex v∈V[G]
do MAKE-SET(v)
sort the eages of E into nondecreasing order by weight w
for each eage(u, v)∈E, teken in nondecreasing order by weight
do if(FIND-SET(u) ≠ FIND-SET(v))
then A←A∪{ (u, v) }
Union(u, v)
return A
三、實現
下面給出C++的實現,之後再來分析時間復雜度:
1 #include <iostream>
2 #include <cstdio>
3 #include <algorithm>
4 #include <cstring>
5 using namespace std;
6
7 #define maxn 110 //最多點個數
8 int n, m; //點個數,邊數
9 int parent[maxn]; //父親節點,當值為-1時表示根節點
10 int ans; //存放最小生成樹權值
11 struct eage //邊的結構體,u、v為兩端點,w為邊權值
12 {
13 int u, v, w;
14 }EG[5010];
15
16 bool cmp(eage a, eage b) //排序調用
17 {
18 return a.w < b.w;
19 }
20
21 int Find(int x) //尋找根節點,判斷是否在同一棵樹中的依據
22 {
23 if(parent[x] == -1) return x;
24 return Find(parent[x]);
25 }
26
27 void Kruskal() //Kruskal算法,parent能夠還原一棵生成樹,或者森林
28 {
29 memset(parent, -1, sizeof(parent));
30 sort(EG+1, EG+m+1, cmp); //按權值將邊從小到大排序
31 ans = 0;
32 for(int i = 1; i <= m; i++) //按權值從小到大選擇邊
33 {
34 int t1 = Find(EG[i].u), t2 = Find(EG[i].v);
35 if(t1 != t2) //若不在同一棵樹種則選擇該邊,合並兩棵樹
36 {
37 ans += EG[i].w;
38 parent[t1] = t2;
39 }
40 }
41 }
42 int main()
43 {
44 while(~scanf("%d%d", &n,&m))
45 {
46 for(int i = 1; i <= m; i++)
47 scanf("%d%d%d", &EG[i].u, &EG[i].v, &EG[i].w);
48 Kruskal();
49 printf("%d\n", ans);
50 }
51 return 0;
52 }
四、時間復雜度
分析以上代碼中Kruskal算法的時間復雜度,n用V表示,m用E表示:
29行:將V個點父節點都置為-1,時間為O(V)
30行:stl中的sort函數,頭文件為#include <algorithm>,時間復雜度為O(E log E)
32-40行:由於FIND-SET是樹搜索操作,平均時間復雜度為O(lg V),因為這幾行時間復雜度平均為O(E log V)
綜上:總復雜度表示為:O(V) + O(E log E) + O(E log V);
當圖為稠密圖時,時間復雜度可表示為 O(E log E);
一般圖基本為稀疏圖|E| < |V|^2,時間復雜度可表示為 O(E log V)。
因而,從時間復雜度來看,當圖為稀疏圖時,Kruskal算法性能和Prim相當,當為稠密圖時,Prim性能更好。
五、小技巧
注意每合並兩棵樹,樹的棵樹就減少1,當根節點的個數只有一個即只有一棵樹時,說明生成了最小生成樹,此時程序便可終止,沒有必要去查看後面權值更大的邊,因而判斷根節點的數目,在圖較為稠密時,能夠提高一定的性能,代碼修改如下,圖為完全圖:
1 #include <iostream>
2 #include <cstdio>
3 #include <algorithm>
4 #include <cstring>
5 using namespace std;
6
7 #define maxn 110 //最多點個數
8 int n, m; //點個數,邊數
9 int parent[maxn]; //父親節點,當值為-1時表示根節點
10 int ans; //存放最小生成樹權值
11 struct eage //邊的結構體,u、v為兩端點,w為邊權值
12 {
13 int u, v, w;
14 }EG[5010];
15
16 bool cmp(eage a, eage b) //排序調用
17 {
18 return a.w < b.w;
19 }
20
21 int Find(int x) //尋找根節點,判斷是否在同一棵樹中的依據
22 {
23 if(parent[x] == -1) return x;
24 return Find(parent[x]);
25 }
26
27 void Kruskal() //Kruskal算法,parent能夠還原一棵生成樹,或者森林
28 {
29 memset(parent, -1, sizeof(parent));
30 int cnt = n; //初始時根節點數目為n個
31 sort(EG+1, EG+m+1, cmp); //按權值將邊從小到大排序
32 ans = 0;
33 for(int i = 1; i <= m; i++) //按權值從小到大選擇邊
34 {
35 if(cnt == 1) break; //當根節點只有1個時,跳出循環
36 int t1 = Find(EG[i].u), t2 = Find(EG[i].v);
37 if(t1 != t2) //若不在同一棵樹種則選擇該邊,
38 {
39 ans += EG[i].w;
40 parent[t1] = t2;
41 cnt--; //每次合並,減少一個根節點
42 }
43 }
44 }
45 int main()
46 {
47 while(scanf("%d", &n), n)
48 {
49 m = n*(n-1)/2; //完全圖
50 for(int i = 1; i <= m; i++)
51 scanf("%d%d%d", &EG[i].u, &EG[i].v, &EG[i].w);
52 Kruskal();
53 printf("%d\n", ans);
54 }
55 return 0;
56 }