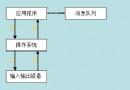
直接選擇排序 (不穩定) 排序過程: 1 、首先在所有數據中經過 n-1次比較選出最小的數,把它與第 1個數據交換, 2、然後在其余的數據內選出排序碼最小的數,與第 2個數據交換...... 依次類推,直到所有數據排完為止。 在第i 趟排序中選出最小關鍵字的數據,需要做 n-i次比較。 復雜度 : 總的比較次數為n(n-1)/2=O(n2)。 當初始文件為正序時,移動次數為0;文件初態為反序時,每趟排序均要執行交換操作,總的移動次數取最大值3(n-1)。 直接選擇排序的平均時間復雜度為O(n2),直接選擇排序是不穩定的。 與冒泡排序的區別: 1、選擇排序 :a[0]與a[1] 比較,如果 a[0]大於a[1], 記錄最小數a[1]的位置1,然後j++,變成了a[2]與當前最小的數a[1]比較,慢慢往後循環,記錄最小的數,最好將最小的數與第一個數a[0]交換位置 2、冒泡排序:首先第一個數 a[0]與第二個數a[1] 比較(從小到大),然後第二個數 a[1]與第三個數a[2] 比較;第三個數 a[2]與第四個數a[3]...... 第一內層循環結束; 程序如下:
void SelectSort(int *arr,int num)
{
if(NULL == arr)
return;
for(int i = 0;i <n-1){
int k = i;
for(int j = i+1;j < n;++j){
if(arr[j] < arr[k])
k = j; //k記下目前找到的最小數的位置
}
if(k != i){
int temp = arr[i];
arr[i] = arr[k];
arr[k] = temp;
}
}
}
堆排序(不穩定) 堆介紹: 堆實際上是一棵完全二叉樹,其任何一非葉節點滿足性質: Key[i]<=key[2i+1]&&Key[i]<=key[2i+2]或者Key[i]>=Key[2i+1]&&key>=key[2i+2],即任何一非葉節點的關鍵字不大於或者不小於其左右孩子節點的關鍵字。 堆分為大頂堆和小頂堆,滿足Key[i]>=Key[2i+1]&&key>=key[2i+2]稱為大頂堆,滿足Key[i]<=key[2i+1]&&Key[i]<=key[2i+2]稱為小頂堆。由上述性質可知大頂堆的堆頂的關鍵字肯定是所有關鍵字中最大的,小頂堆的堆頂的關鍵字是所有關鍵字中最小的。 堆排序的思想: 利用大頂堆(小頂堆)堆頂記錄的是最大關鍵字(最小關鍵字)這一特性,使得每次從無序中選擇最大記錄(最小記錄)變得簡單。 其基本思想為(大頂堆): 1)將初始待排序關鍵字序列(R1,R2....Rn)構建成大頂堆,此堆為初始的無序區; 2)將堆頂元素R[1]與最後一個元素R[n]交換,此時得到新的無序區(R1,R2,......Rn-1)和新的有序區(Rn),且滿足R[1,2...n-1]<=R[n]; 3)由於交換後新的堆頂R[1]可能違反堆的性質,因此需要對當前無序區(R1,R2,......Rn-1)調整為新堆,然後再次將R[1]與無序區最後一個元素交換,得到新的無序區(R1,R2....Rn-2)和新的有序區(Rn-1,Rn)。不斷重復此過程直到有序區的元素個數為n-1,則整個排序過程完成。 操作過程如下: 1)初始化堆:將R[1..n]構造為堆; 2)調整這個堆,讓它變成一個大頂堆; 3)開始排序,將當前無序區的堆頂元素R[1]同該區間的最後一個記錄交換,然後將新的無序區調整為新的堆。 因此對於堆排序,最重要的兩個操作就是構造初始堆和調整堆,其實構造初始堆事實上也是調整堆的過程,只不過構造初始堆是對所有的非葉節點都進行調整。 復雜度: 堆排序的最壞時間復雜度為O(nlgn)。堆排序的平均性能較接近於最壞性能。 由於建初始堆所需的比較次數較多,所以堆排序不適宜於記錄數較少的文件。 堆排序是就地排序,輔助空間為O(1),它是不穩定的排序方法。 代碼: /*堆排序(大頂堆) 2011.9.14*/ #include <iostream> #include<algorithm> using namespace std; void HeapAdjust(int *a,int i,int size) //調整堆 { int lchild=2*i; //i的左孩子節點序號 int rchild=2*i+1; //i的右孩子節點序號 int max=i; //臨時變量 if(i<=size/2) //如果i不是葉節點就不用進行調整 { if(lchild<=size&&a[lchild]>a[max]) { max=lchild; } if(rchild<=size&&a[rchild]>a[max]) { max=rchild; } if(max!=i) { swap(a[i],a[max]); HeapAdjust(a,max,size); //避免調整之後以max為父節點的子樹不是堆 } } } void BuildHeap(int *a,int size) //建立堆 { int i; for(i=size/2;i>=1;i--) //非葉節點最大序號值為size/2 { HeapAdjust(a,i,size); } } void HeapSort(int *a,int size) //堆排序 { int i; BuildHeap(a,size); for(i=size;i>=1;i--) { //cout<<a[1]<<" "; swap(a[1],a[i]); //交換堆頂和最後一個元素,即每次將剩余元素中的最大者放到最後面 //BuildHeap(a,i-1); //將余下元素重新建立為大頂堆 HeapAdjust(a,1,i-1); //重新調整堆頂節點成為大頂堆 } } int main(int argc, char *argv[]) { //int a[]={0,16,20,3,11,17,8}; int a[100]; int size; while(scanf("%d",&size)==1&&size>0) { int i; for(i=1;i<=size;i++) cin>>a[i]; HeapSort(a,size); for(i=1;i<=size;i++) cout<<a[i]<<" "; cout<<endl; } return 0; }