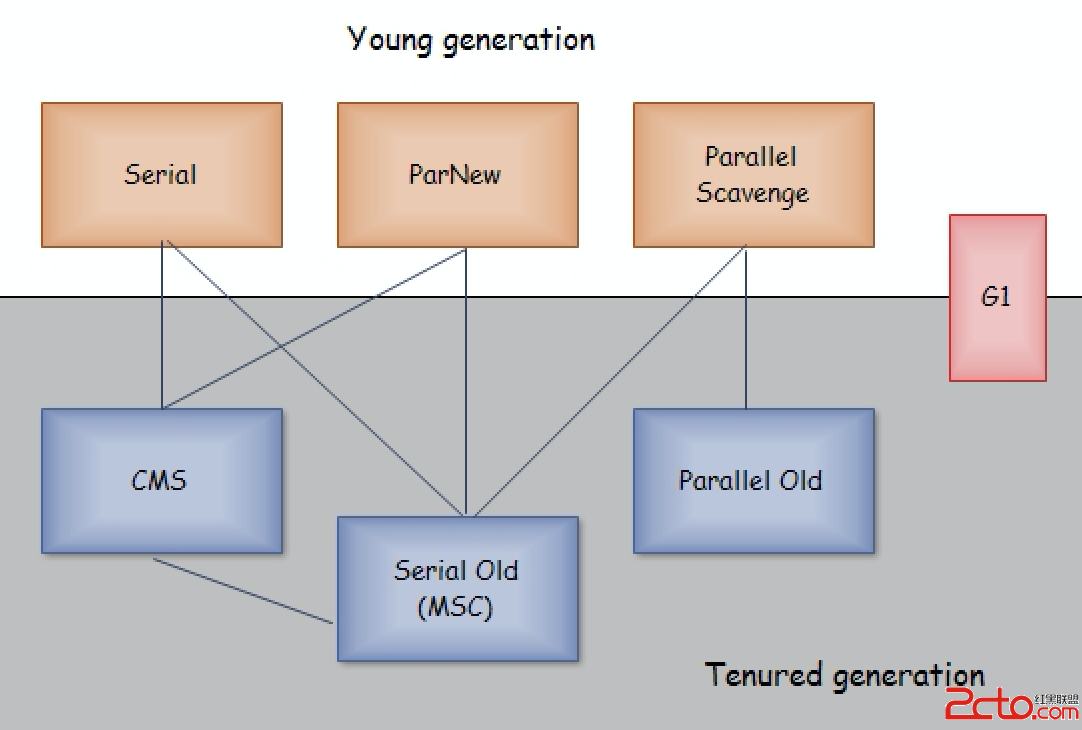
如果你想異步地運行函數doAsyncWork,你有兩個基本的選擇。你可以創建一個std::thread,用它來運行doAsyncWork,因此這是基於線程(thread-based)的方法:
int doAsyncWork();
std::thread t(doAsyncWork);
或者你把doAsynWork傳遞給std::async,一個叫做基於任務(task-based)的策略:
auto fut = std::async(doAsyncWork); // "fut"的意思是"future"
在這種調用中,傳遞給std::async的函數對象被認為是一個任務(task)。
基於任務的方法通常比基於線程實現的相對物要好,我們看到基於任務的方法代碼量更少,這已經是展示了一些原因了。在這裡,doAsyncWork會返回一個值,我們有理由假定調用doAsyncWork的代碼對這個返回值有興趣。在基於線程的調用中,沒有直接的辦法獲取到它;而在基於任務的調用中,這很容易,因為std::asyn返回的future提供了一個函數get來獲取返回值。如果doAsyncWork函數發出了一個異常,get函數是很重要的,它能取到這個異常。在基於線程的方法中,如果doAsyncWork拋出了異常,程序就死亡了(借助**std::terminate)。
基於線程編程和基於任務編程的一個更基礎的區別是,基於任務編程表現出更高級別的抽象。它讓你免受線程管理的細節,這讓我想起了我需要總結“線程”在C++並發軟件裡的三個意思:
硬件線程是一種負責計算的線程。現代機器體系結構為每個CPU核心提供一個或多個硬件線程。 軟件線程(又稱為操作系統線程或系統線程)是由操作系統管理和為硬件線程進行調度的線程。軟件線程創建的數量通常會比硬件線程多,因為當一個軟件線程阻塞了(例如,I/O操作,等待鎖或者條件變量),運行另一個非阻塞的線程能提供吞吐率。 std::thread是C++進程裡的對象,它在自身內部操作軟件線程。一些std::thread對象表示為“null”句柄,相當於不持有軟件線程,因為它們處於默認構造狀態(因此沒有需要執行的函數),它要麼被移動過了(那麼,移動操作的目的std::thread對象會操作軟件線程),要麼被join了(std::thread對象要執行的函數運行結束),要麼被detach了(std::thread對象和它內部軟件線程的連接被切斷了,即thread對象和軟件線程分離了)。 軟件線程是一種受限的資源,如果你想創建的線程數量多於系統提供的數量,會拋出std::system_error異常。就算你規定函數不能拋出異常,這個異常也會拋出。例如,就算你把doAsyncWork聲明為noexcept,
int doAsyncWork noexcept; // 關於noexcept,請看條款14
這語句還是可能會拋出異常:
std::thread t(doAsyncWork); // 如果沒有可獲取的系統,就拋出異常
寫得好的軟件必須想個辦法解決這個可能性,但如何解決呢?一個辦法是在當前線程運行doAsyncWork,但這會導致負載不均衡的問題,而且,如果當前線程是個GUI線程,會導致響應時間變長。另一個方法是等待某些已存在的軟件線程完成工作,然後再嘗試創建一個新的std::thread對象,但是有可能發生這種事情:已存在的線程在等待doAsyncWork的處理(例如,doAsyncWorkd的返回值,或者通知條件變量)。
即使你的沒有用完線程,你還是會有oversubscription(過載)的問題——當就緒狀態(即非阻塞)的軟件線程多於硬件線程的時候。如果發生了那種事,調度線程(通常是操作系統的一部分)會為軟件線程分配CPU時間片,一個線程的時間片用完,就運行另一個線程,這其中發生了上下文切換。這種上下文切換會增加系統的線程管理開銷。這種情況下,(1)CPU緩存會持有那個軟件線程(即,它們會含有對於那軟件線程有用的一些數據和一些指令),而(2)CPU核心上“新”運行的軟件線程“污染”了CPU緩存上“舊的”線程數據(它曾經在該CPU核心運行過,且可能再次調度到該CPU核心運行)。
避免oversubscription是很困難的,因為軟件系統和硬件線程的最佳比例是取決於軟件線程多久需要執行一次,而這是會動態改變的,例如,當一個線程從IO消耗型轉換為CPU消耗型時。這最佳比例也取決於上下文切換的開銷和軟件線程使用CPU緩存的效率。再進一步說,硬件線程的數量和CPU緩存的細節(例如,緩存多大和多快)是取決於機器的體系結構,所以即使你在一個平台上讓你的應用避免了oversubscription(保持硬件繁忙工作),也不能保證在另一種機器上你的方案能工作得好。
如果你把這些問題扔給某個人去做,你的生活就很惬意啦,然後使用std::async就能顯式地做這件事:
auto fut = std::async(doAsyncWork); // 線程管理的責任交給標准庫的實現者
這個調用把線程管理的責任轉交給C++標准庫的實現者。例如,得到線程超標的異常的可能性絕大幅度減少,因為這個調用可能從不產生這個異常。“它是怎樣做到的呢?”你可能好奇,“如果我申請多於系統提供的線程,使用std::thread和使用std::async有區別嗎?”答案是有區別,因為當用默認發射策略(看條款36)調用std::async時,不能保證它會創建一個新的軟件線程。而且,它允許調度器把指定函數(例如,doAsyncWork)運行在——請求doAsyncWork結果的線程中(例如,那個線程調用了get或者對fut使用wait ),如果系統oversubsrcibed或線程耗盡時,合理的調度器可以利用這個優勢。
如果你想用“在需求函數結果的線程上運行該函數”來欺騙自己,我提起過這會導致負載均衡的問題,這問題不會消失,只是由std::async和調度器來面對它們,而不是你。但是,當涉及到負載均衡問題時,調度器比你更加了解當前機器發生了什麼,因為它管理所以進程的線程,而不是只是你的代碼。
使用std::async,GUI線程的響應性也是有問題的,因為調度器沒有辦法知道哪個線程需求緊湊的響應性。在這種情況下,你可以把std::lanuch::async發射策略傳遞給std::async,它那可以保證你想要運行的函數馬上會在另一個線程中執行(看條款36)。
最新技術水平的線程調度器使用了系統范圍的線程池來避免oversubscription,而且調度器通過工作竊取算法來提高了硬件核心的負載均衡能力。C++標准庫沒有要求線程池或者工作竊取算法,而且,實話說,C++11並發技術的一些實現細節讓我們很難利用到它們。但是,一些供應商會在它們的標准庫實現中利用這種技術,所以我們有理由期待C++並發庫會繼續進步。如果你使用基於任務的方法進行編程,當它以後變智能了,你會自動獲取到好處。另一方面,如果你直接使用std::thread進行編程,你要承擔著處理線程耗盡、oversubscription、負載均衡的壓力,更不用提你在程序中對這些問題的處理方案能否應用在同一台機器的另一個進程上。
比起基於線程編程,基於任務的設計能分擔你的線程管理之痛,而且它提供了一種很自然的方式,讓你檢查異步執行函數的結果(即,返回值或異常)。但是,有幾種情況直接使用std::thread更適合,它們包括
你需要使用內部的特定平台線程的API。C++並發API通常是以特定平台的低級API實現的,通常使用pthread或Window’s Thread。它們提供的API比C++提供的要多(例如,C++沒有線程優先級的概念)。為了獲取內部線程實現的API,std::thread對象有一個native_handle成員函數,而std::future(即std::async返回的類型)沒有類似的東西。 你需要且能夠在你的應用中優化線程的用法。例如,你要在一個固定的機器平台上部署一個單進程的服務器軟件。 你需要在C++並發API之上實現線程技術。例如,實現一個C++不提供的線程池。 不過,這些都是不常見的情況。大多數時候,你應該選擇基於任務的設計,來代替線程。
總結需要記住的3點:
std::thread的API沒有提供直接獲取異步運行函數返回值的方法,而且,如果這些函數拋出異常,程序會被終止。 基於線程編程需要手動地管理:線程耗盡、oversubscription、負載均衡、適配新平台。 借助默認發射策略的std::async,進行基於任務編程可以解決上面提到的大部分問題。