是不包含在函數聲明,函數定義或者類定義內的程序文本部分。
程序員也可以利用名字空間定義namespace definition 來定義用戶聲明的user-declared 的名字空間。它們被嵌套在全局域內。
局部域內的名字解析是這樣進行的:
首先查找使用該名字的域, 如果找到一個聲明則該名字被解析. 如果沒有找到則查找包含該域的域, 這個過程會一直繼續下去. 直到找到一個聲明或已經查找完整個全局域. 如果後一種情況發生即沒有找到該名字的聲明, 則這個名字的用法將被標記為錯誤.
要求全局對象和函數或者只有一個定義或者在一個程序中有多個完全相同的定義, 這樣的要求被稱為一次定義法則: ODR one definition rule
在全局域中定義的對象如果沒有指定顯式的初始值則該存儲區被初始化為0
關鍵字extern 為聲明但不定義一個對象提供了一種方法, 實際上它類似於函數聲明, 承諾了該對象會在其他地方被定義或者在此文本文件中的其他地方, 或者在程序的其他文本文件中例如: extern int i;
如果應用程序有很大的頭文件, 則使用預編譯頭文件而不是普通頭文件可以大大降低應用程序的編譯時間
頭文件不應該含有非inline 函數或對象的定義
例如下面的代碼表示的正是這樣的定義, 因此不應該出現在頭文件中
extern int ival = 10;
double fica_rate;
符號常量和inline函數可以被定義多次:
為了使編譯器能夠用一個常量值替換它的名字, 該常量的定義它的初始值必須在它被使用的文件中可見, 因為這個原因符號常量可以在同一程序的不同文件中被定義多次.
常量指針,指針常量,指向常量的常指針
定義為指針指向的變量的值不可通過該指針修改, const在 * 前面
const int*p ( int const * p )
int main(int argc, char *argv[]) {
int a=12;
int const * p=&a; // or : const int *p=&a;
cout<<*p<
指針常量指針指向的數值可以改變,然而指針所保存的地址卻不可以改變。
int* const p
int main(int argc, char *argv[]) {
int a=12,b=13;
int * const p=&a; //指針常量
cout<<*p<
指向常量的常指針指針指向的地址和數值都是不可更改的。
const int const*p
int main(int argc, char *argv[]) {
int a=12,b=13;
const int* const p = &a;
cout<<*p<
建議把那些天生無法內聯的函數不聲明為inline 並且不放在頭文件中
內聯擴展是用來消除函數調用時的時間開銷。它通常用於頻繁執行的函數。 一個小內存空間的函數非常受益。如果沒有內聯函數,編譯器可以決定哪些函數內聯。
自動對象的存儲分配發生在定義它的函數被調用時.
因為與自動對象相關聯的存儲區在函數結束時被釋放, 所以應該小心使用自動對象的地址, 自動對象的地址不應該被用作函數的返回值. 因為函數一旦結束了該地址就指向一個無效的存儲區. 例如:
#include "Matrix.h"
Matrix* trouble( Matrix *pm )
{
{
Matrix res;
// 用pm 做一些事情
// 把結果賦值給res
return &res; // 糟糕!
}
int main()
{
Matrix m1;
// ...
Matrix *mainResult = trouble( &m1 );
// ...
}
< 在本例中該地址可能仍然有效, 因為我們還沒有調用其他函數覆蓋掉trouble()函數的活動記錄的部分或全部, 所以這樣的錯誤很難檢測.>
在函數中頻繁被使用的自動變量可以用register 聲明, 如果可能的話編譯器會把該對象裝載到機器的寄存器中, 如果不能夠的話則對象仍位於內存中. 出現在循環語句中的數組索引和指針是寄存器對象的很好例子.
for ( register int ix = 0; ix < sz; ++ix ) // …
for (register int *p = array ; p < arraySize; ++p ) // …
new 表達式沒有返回實際分配的對象, 而是返回指向該對象的指針。對該對象的全部操作都要通過這個指針間接完成. 例如: int *pi = new int;
空閒存儲區的第二個特點是分配的內存是未初始化的. 空閒存儲區的內存包含隨機的位模式. 它是程序運行前該內存上次被使用留下的結果. 測試: if ( *pi == 0 ) 總是錯誤的。除非:int *pi = new int( 0 );
如果new 表達式調用的new()操作符不能得到要求的內存通常會拋出一個bad_alloc 異常
內存被釋放–> delete pi;
delete 表達式調用庫操作符delete(), 把內存還給空閒存儲區, 因為空閒存儲區是有限的資源. 所以當我們不再需要已分配的內存時就應該馬上將其返還給空閒存儲區. 這是很重要的.
當程序運行期間遇到delete 表達式時, pi指向的內存就被釋放了, 但是指針pi 的內存及其內容並沒有受delete 表達式的影響. 在delete表達式之後pi 被稱作空懸指針,即指向無效內存的指針, 一個比較好的辦法是在指針指向的對象被釋放後將該指針設置為0.
野指針它沒有被正確的初始化,於是指向一個隨機的內存地址
int main()
{
int *a=(int *)malloc(sizeof(int));
*a=1;
printf("a:%d a'addr:%p\n",*a,a);
delete(a);
printf("a:%d a'addr:%p\n",*a,a); //A dangling pointer 空懸指針,原來所指的內存釋放了
int *b; //A wild pointer 野指針 ,一開始 就沒有賦初值
printf("b:%d b'addr:%p\n",*b,b);
return 0;
}
/*
a:1 a'addr:003E2460
a:0 a'addr:003E2460
b:-1869573949 b'addr:7C93154C
*/
auto_ptr 對象被初始化為指向由new 表達式創建的動態分配對象。 當auto_ptr 對象的生命期結束時動態分配的對象被自動釋放。 定義pstr_auto 時它知道自己對初始化字符串擁有所有權, 並且有責任刪除該字符串。這是所有權授予auto_ptr 對象的責任。相關的頭文件:#include
string *pstr_type = new string( “Brontosaurus” ); 等價於:auto_ptr< string > pstr_auto( new string( “Brontosaurus” ) );
兩個指針都持有程序空閒存儲區內的字符串地址,我們必須小心地將delete 表達式只應用在一個指針上。即有兩個指針指向同一個由new創造的地址,用delete釋放一次就可以了。
當一個auto_ptr 對象被用另一個auto_ptr 對象初始化或賦值時,左邊被賦值或初始化的對象就擁有了空閒存儲區內底層對象的所有權,而右邊的auto_ptr 對象則撤消所有責任。
auto_ptr< int > p_auto_int; 因為p_auto_int 沒有被初始化指向一個對象。所以它的內部指針值被設置為0,這意味著對它解除引用會使程序出現未定義的行為。
操作get()返回auto_ptr 對象內部的底層指針。所以為了判斷auto_ptr 對象是否指向一個對象我們可以如下編程
if ( p_auto_int.get() != 0 &&*p_auto_int != 1024 ) *p_auto_int = 1024;
如果它沒有指向一個對象,那麼怎樣使其指向一個呢——即怎樣設置一個auto_ptr 對象的底層指針。我們可以用reset()操作例如
else // ok, 讓我們設置 p_auto_int 的底層指針
p_auto_int.reset( new int( 1024 ) );
auto_ptr< string >pstr_auto( new string( “Brontosaurus” ) );
// 在重置之前刪除對象 Brontosaurus:
pstr_auto.reset( new string( “Long -neck” ) );
//在這種情況下用字符串操作assign()對原有的字符串對象重新賦值比刪除原有的字符率對象並重新分配第二個字符串對象更為有效:
pstr_auto->assign( “Long-neck” );
不能用一個指向內存不是通過應用new 表達式分配的指針來初始化或賦值auto_ptr。
release()不僅像get()操作一樣返回底層對象的地址而且還釋放這對象的所有權:auto_ptr< string > pstr_auto2( pstr_auto.release() );
// 分配單個int 型的對象,用 1024 初始化
int *pi = new int( 1024 );
// 分配一個含有1024 個元素的數組,未被初始化
int *pia = new int[ 1024 ];
動態數組的建立:對於用new 表達式分配的數組只有第一維可以用運行時刻計算的表達式來指定,其他維必須是在編譯時刻已知的常量值。
#include
#include
int main(int argc, char *argv[]) {
puts("please enter height, width, and length:");
int height=10,width=10,length=10;
scanf("%d%d%d",&height,&width,&length);
int ***a=new int**[height];
for(int i=0;i
用來釋放數組的delete 表達式形式如下 delete [] str1;
在空閒存儲區創建的const 對象有一些特殊的屬性:首先const 對象必須被初始化。如果省略了括號中的初始值就會產生編譯錯誤。
const int p; // [Error] uninitialized const ‘p’ [-fpermissive]
如果要在局部域中訪問全局聲明的變量(局部中有一樣名字的變量)我們必須使用域操作符:: 例如:
const int m=12;
int cmp(int m){
m=::m+m;
return m;
}
int main(int argc, char *argv[]) {
printf("%d\n",cmp(10));
}
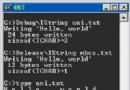
用戶聲明的名字空間可以包含嵌套的名字空間.
名字空間的定義可以是不連續的可以跨越多個文件。因此一個名字空間可以在多個文件中被聲明
// —– SortLib.C —–
namespace {
void swap( double d1, double *d2 ) { / … */ }
}
函數swap()只在文件SortLib.C 中可見,如果另一個文件也含有一個帶有函數swap()定義的未命名名字空間,則該定義引入的是一個不同的函數函數。swap()存在兩種定義但這並不是個錯誤。
因為它們是不同的未命名的名字空間的定義,局部於一個特定的文件不能跨越多個文本文件。
自定義命名空間跨越多個文件:
a.h:
namespace a{
void print(){
printf("here is hero_a\n");
}
}
b.h:
namespace b{
void print(){
printf("here is hero_b\n");
}
}
mian.cpp:
#include
#include
#include "a.h"
#include "b.h"
int main(int argc, char *argv[]) {
a::print();
b::print();
}
/*
here is hero_a
here is hero_b
*/
static:被static修飾的是靜態變量。
靜態局部變量保存在全局數據區,而不是保存在棧中
int get(){
static int g;
g++;
return g;
}
int main()
{
cout<
靜態全局變量未經初始化的靜態全局變量會被程序自動初始化為0;
靜態全局變量在聲明它的整個文件都是可見的,而在文件之外是不可見的(無法多文件傳輸);
名字空間別名可以用來把一個較短的同義詞與一個名字空間名關聯起來,例如:namespace International_Business_Machines
{ /* … */ }
namespace IBM = International_Business_Machines;
using 聲明同其他聲明的行為一樣它有一個域,它引入的名字從該聲明開始直到其所在的域結束都是可見的。
using聲明:using cplusplus_primer::matrix;
using指示符:using namespace cplusplus_primer;
九 重載函數重載如果兩個函數的參數表中參數的個數或類型不同, 則認為這兩個函數是重載的.
如果兩個函數的返回類型和參數表精確匹配則第二個聲明被視為第一個的重復聲明.
如果兩個函數的參數表相同但是返回類型不同, 則第二個聲明被視為第一個的錯誤重復聲明會被標記為編譯錯誤。
當一個參數類型是const 或volatile 時,在識別函數聲明是否相同時,並不考慮const 和volatile 修飾符。
1. 聲明同一函數
void f( int ); void f( const int ); //參數設為const可以防止參數的值改變。
2. 聲明了不同的函數
void f( int* ); void f( const int* ); //const對於指針與引用有影響。
用戶不能在using 聲明中為一個函數指定參數表: using libs_R_us::print( double ); // 錯誤
using 指示符使名字空間成員就像在名字空間之外被聲明的一樣.
指向重載函數的指針:
extern void ff( unsigned int );
void ( *pf1 )( unsigned int ) = &ff;
extern "C" //聲明的函數告訴編譯器該函數以C語言的方式編譯鏈接。
重載函數集的合適體的選擇:
候選函數–可行函數–最佳匹配函。
可行函數的參數個數與調用的實參表中的參數數目相同,或者可行函數的參數個數多一些,但是每個多出來的參數都要有相關的缺省實參。
可能的轉換被分成三組:提升promotion, 標准轉換standard conversion, 和用戶定義的轉換user defined conversions。
用戶定義的轉換由轉換函數conversion function 來執行。它是類的一個成員函數允許一個類定義自己的標准轉換。
函數轉換被劃分等級如下:精確匹配比提升好,提升比標准轉換好,標准轉換比用戶定義的轉換好。
五種標准轉換1 整值類型轉換:從任何整值類型或枚舉類型向其他整值類型的轉換(不包括前面提升部分中列出的轉換)
2 浮點轉換:從任何浮點類型到其他浮點類型的轉換(不包括前面提升部分中列出的轉換)
3 浮點—整值轉換:從任何浮點類型到任何整值類型或從任何整值類型到任何浮點類型的轉換
4 指針轉換:整數值0 到指針類型的轉換和任何類型的指針到類型void*的轉換
5 bool 轉換:從任何整值類型浮點類型枚舉類型或指針類型到bool 型的轉換
所有的標准轉換都被視為是等價的。例如從char 到unsigned char 的轉換並不比從char到double 的轉換優先級高,類型之間的接近程度不被考慮,即如果有兩個可行函數要求對實參進行標准轉換以便匹配各自參數的類型則該調用就是二義的。將被標記為編譯錯誤。
函數指針不能用標准轉換轉換成類型void*。
0 可以被轉換成任何指針類型。
實參是該引用的有效初始值(類型一樣)則該實參是精確匹配,如果該實參不是引用的有效初始值則不匹配。
十 函數模版 (續讀)這一部分的內容沒有讀最重要的部分
函數模板提供一個用來自動生成各種類型函數實例的算法。
用預處理器的宏擴展設施,例如#define min(a,b) ((a) < (b) ? (a) : (b)),可以避免為所有的不同類型數據都設計一樣算法的函數。
函數模板提供了一種機制,通過它我們可以保留函數定義和函數調用的語義。
在一個程序位置上封裝了一段代碼,確保在函數調用之前實參只被計算一次而無需像宏方案那樣繞過C++的強類型檢查。
min函數的模版:
template //Type可以換成任何其他的自定義名字
Type min( Type a, Type b ) {
return a < b ? a : b;
}
template //模板非類型參數由一個普通的參數聲明構成
Type min( Type (&arr) [size] );
十一 異常處理throw 表達式可以拋出任何類型的對象, 必須定義可以被拋出的異常, 在C++中異常往往用類class 來實現。
try 塊(try block) 必須包圍能夠拋出異常的語句,try 塊以關鍵字try 開始,後面是花括號括起來的語句序列。在try 塊之後是一組處理代碼,被稱為catch 子句。
當某條語句拋出異常時跟在該語句後面的語句將被跳過程序, 執行權被轉交給處理異常的catch子句。
在main()的函數體中聲明的變量不能在catch 子句中被引用。
一個catch 子句由三部分構成:關鍵字catch,在括號中的異常聲明exception declaration,以及復合語句中的一組語句。
在查找用來處理被拋出異常的catch 子句時因為異常而退出復合語句和函數定義,這個過程被稱作棧展開stack unwinding。
異常對於一個程序非常重要,它表示程序不能夠繼續正常執行,如果沒有找到處理代碼程序就調用C++標准庫中定義的函數terminate()。terminate()的缺省行為是調用abort(),指示從程序非正常退出。
在異常處理過程中也可能存在單個catch 子句不能完全處理異常的情況,在某些修正動作之後catch 子句可能決定該異常必須由函數調用鏈中更上級的函數來處理,那麼catch子句可以通過重新拋出rethrow 該異常。
catch ( exception eObj ) {
if ( canHandle( eObj ) )
// 處理異常
return;
else
// 重新拋出它, 並由另一個catch 子句來處理
throw;
}
void calculate( int op ) {
try {
// 被 mathFunc() 拋出的異常的值為 zeroOp
mathFunc( op );
}
//為了修改原來的異常對象catch 子句中的異常聲明必須被聲明為引用例如
cacth ( EHstate &eObj ) {
// 修改異常對象
eObj = severeErr;
// 被重新拋出的異常的值是 severeErr
throw;
}
十二 泛型算法泛型算法操作在多種容器類型上的算法。
比如find()函數,iterator迭代器,sort()函數。
————————————————————————————————————————
int數組的find()算法:
#include
#include
using namespace std;
int main()
{
int search_value;
int ia[ 6 ] = { 27, 210, 12, 47, 109, 83 };
cout << "enter search value: ";
cin >> search_value;
int *presult = find( &ia[0], &ia[6], search_value );
cout << "The value " << search_value<< ( presult == &ia[6]? " is not present" : " is present" )<< endl;
return 0;
}
————————————————————————————————————————-
vector的find()算法:
#include
#include
#include
using namespace std;
int main()
{
int search_value;
int ia[ 6 ] = { 27, 210, 12, 47, 109, 83 };
vector vec( ia, ia+6 );
cout << "enter search value: ";
cin >> search_value;
vector::iterator presult;
presult = find( vec.begin(), vec.end(), search_value );
cout << "The value " << search_value<< ( presult == vec.end()? " is not present" : " is present" )
<< endl;
return 0;
}
——————————————————————————————————————————-
list的find()算法
#include
#include
#include
using namespace std;
int main()
{
int search_value;
int ia[ 6 ] = { 27, 210, 12, 47, 109, 83 };
list ilist( ia, ia+6 );
cout << "enter search value: ";
cin >> search_value;
list::iterator presult;
presult = find( ilist.begin(), ilist.end(), search_value );
cout << "The value " << search_value
<< ( presult == ilist.end()
? " is not present" : " is present" )
<< endl;
return 0;
}
對容器的遍歷:iterator. 指針的泛化。
預定義函數對象被分成算術關系和邏輯操作, 每個對象都是一個類模板, 其中操作數的類型被參數化. 為了使用它們我們必須包含#include
以降序排列容器:
vector< string > svec;
// …
sort( svec.begin(), svec.end(), greater()); // 預定義的類模板greater 它調用底層元素類型的大於操作符
const 容器只能被綁定在const iterator 上這樣的要求與const 指針只能指向const 數組的行為一樣在兩種情況下C++語言都努力保證const 容器的內容不會被改變
為支持泛型算法全集根據它們提供的操作集標准庫定義了
五種iteratorInputIterator, OutputIterator, ForwardIterator, BldirectionalIterator 和RandomAccessIterator
InputIterator 可以被用來讀取容器中的元素, 但是不保證支持向容器的寫入操作
OutputIterator 可以被用來向容器寫入元素, 但是不保證支持讀取容器的內容
ForwardIterator 可以被用來以某一個遍歷方向向容器讀或寫
BidirectionalIterator 從兩個方向讀或寫一個容器
RandomAccessIterator 除了支持BidirectionalIterator 所有的功能之外還提供了在常數時間內訪問容器的任意位置的支持
元素范圍概念有時稱為左閉合區間通常寫為[ first, last ) // 讀作: 包含 first 以及到 但不包含 last 的所有元素
四個算術算法#include
adjacent_difference()、 accumulate()、 inner_product()和partial_sum()
查找算法equal_range()、lower_bound()和upper_bound() (二分查找實現)
int main()
{
int a[6]={4,10,13,14,19,26};
int *val=lower_bound(a,a+6,12); //first value >= goal
cout<<*val< goal
cout<<*val<
函數equal_range()返回first和last之間等於val的元素區間.返回值是一對迭代器。
排列組合算法next_permutation(), prev_permutation()
int A[3]={1,2,3};
void show(){
for(int i=0;i<3;i++){
printf("%d ",A[i]);
}
cout<