我在《Linux 多線程服務端編程:使用 muduo C++ 網絡庫》第 1.9 節“再論 shared_ptr 的線程 安全”中寫道:
(shared_ptr)的引用計數本身是安全且無鎖的,但對象的讀寫則不是,因為 shared_ptr 有兩個數據成員,讀寫操作不能原子化。根據文檔 (http://www.boost.org/doc/libs/release/libs/smart_ptr/shared_ptr.htm#ThreadSafety), shared_ptr 的線程安全級別和內建類型、標准庫容器、std::string 一樣,即:
一個 shared_ptr 對象實體可被多個線程同時讀取(文檔例1);
兩個 shared_ptr 對象實體可以 被兩個線程同時寫入(例2),“析構”算寫操作;
如果要從多個線程讀寫同一個 shared_ptr 對象,那麼需要加鎖(例3~5)。
請注意,以上是 shared_ptr 對象本身的線程安 全級別,不是它管理的對象的線程安全級別。
後文(p.18)則介紹如何高效地加鎖解鎖。本文 則具體分析一下為什麼“因為 shared_ptr 有兩個數據成員,讀寫操作不能原子化”使得多線程讀寫同 一個 shared_ptr 對象需要加鎖。這個在我看來顯而易見的結論似乎也有人抱有疑問,那將導致災難性 的後果,值得我寫這篇文章。本文以 boost::shared_ptr 為例,與 std::shared_ptr 可能略有區別。
shared_ptr 的數據結構
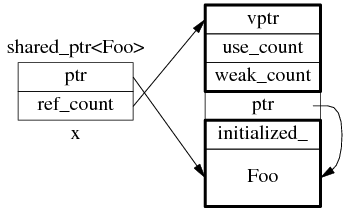
shared_ptr 是引用計數型(reference counting)智能指針 ,幾乎所有的實現都采用在堆(heap)上放個計數值(count)的辦法(除此之外理論上還有用循環鏈 表的辦法,不過沒有實例)。具體來說,shared_ptr<Foo> 包含兩個成員,一個是指向 Foo 的 指針 ptr,另一個是 ref_count 指針(其類型不一定是原始指針,有可能是 class 類型,但不影響這 裡的討論),指向堆上的 ref_count 對象。ref_count 對象有多個成員,具體的數據結構如圖 1 所示 ,其中 deleter 和 allocator 是可選的。
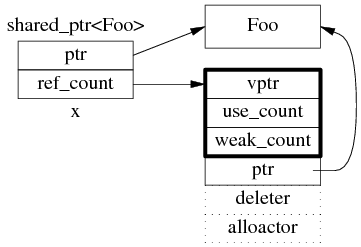
圖 1:shared_ptr 的數 據結構。
為了簡化並突出重點,後文只畫出 use_count 的值:
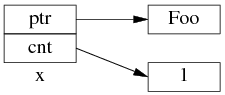
以上是 shared_ptr<Foo> x(new Foo); 對應的內存數據結構。
如果再執行 shared_ptr<Foo> y = x; 那麼對應的數據結構如下。
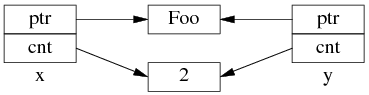
但是 y=x 涉及兩個成員 的復制,這兩步拷貝不會同時(原子)發生。
中間步驟 1,復制 ptr 指針:
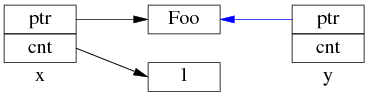
中間步驟 2,復制 ref_count 指針,導致引用計數加 1:
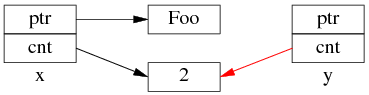
步驟1和步 驟2的先後順序跟實現相關(因此步驟 2 裡沒有畫出 y.ptr 的指向),我見過的都是先1後2。
既然 y=x 有兩個步驟,如果沒有 mutex 保護,那麼在多線程裡就有 race condition。
多線 程無保護讀寫 shared_ptr 可能出現的 race condition
考慮一個簡單的場景,有 3 個 shared_ptr<Foo> 對象 x、g、n:
shared_ptr<Foo> g(new Foo); // 線程之間共享的 shared_ptr
shared_ptr<Foo> x; // 線程 A 的局部變量
shared_ptr<Foo> n(new Foo); // 線程 B 的局部變量
一開始,各安其事。

線程 A 執行 x = g; (即 read g),以下完成了步驟 1,還沒來及執行步驟 2。這時切換到了 B 線程。

查看本欄目
同時編程 B 執行 g = n; (即 write g),兩個步驟一起完成了。
先是步驟 1:

再是步驟 2:

這是 Foo1 對象已經銷毀,x.ptr 成了空懸指針!
最後回到線程 A,完成步驟 2:

多線程無保護地讀寫 g,造成了“x 是空懸指針”的後果。這正是多線程讀寫同一個 shared_ptr 必須加鎖的原因。
當然,race condition 遠不止這一種,其他線程交織(interweaving)有可 能會造成其他錯誤。
思考,假如 shared_ptr 的 operator= 實現是先復制 ref_count(步驟 2 )再復制 ptr(步驟 1),會有哪些 race condition?
雜項
shared_ptr 作為 unordered_map 的 key
如果把 boost::shared_ptr 放到 unordered_set 中,或者用於 unordered_map 的 key,那麼要小心 hash table 退化為鏈表。 http://stackoverflow.com/questions/6404765/c-shared-ptr-as-unordered-sets- key/12122314#12122314
直到 Boost 1.47.0 發布之前, unordered_set<std::shared_ptr<T> > 雖然可以編譯通過,但是其 hash_value 是 shared_ptr 隱式轉換為 bool 的結果。也就是說,如果不自定義hash函數,那麼 unordered_ {set/map} 會退化為鏈表。https://svn.boost.org/trac/boost/ticket/5216
Boost 1.51 在 boost/functional/hash/extensions.hpp 中增加了有關重載,現在只要包含這個頭文件就能安全高效 地使用 unordered_set<std::shared_ptr> 了。
這也是 muduo 的 examples/idleconnection 示例要自己定義 hash_value(const boost::shared_ptr<T>& x) 函數的原因(書第 7.10.2 節,p.255)。因為 Debian 6 Squeeze、Ubuntu 10.04 LTS 裡的 boost 版 本都有這個 bug。
為什麼圖 1 中的 ref_count 也有指向 Foo 的指針?
shared_ptr<Foo> sp(new Foo) 在構造 sp 的時候捕獲了 Foo 的析構行為。實際上 shared_ptr.ptr 和 ref_count.ptr 可以是不同的類型(只要它們之間存在隱式轉換),這是 shared_ptr 的一大功能。分 3 點來說:
1. 無需虛析構;假設 Bar 是 Foo 的基類,但是 Bar 和 Foo 都沒有虛析構。
shared_ptr<Foo> sp1(new Foo); // ref_count.ptr 的類型是 Foo*
shared_ptr<Bar> sp2 = sp1; // 可以賦值,自動向上轉 型(up-cast)
sp1.reset(); // 這時 Foo 對象的引用計數降為 1
此後 sp2 仍然能安 全地管理 Foo 對象的生命期,並安全完整地釋放 Foo,因為其 ref_count 記住了 Foo 的實際類型。
2. shared_ptr<void> 可以指向並安全地管理(析構或防止析構)任何對象; muduo::net::Channel class 的 tie() 函數就使用了這一特性,防止對象過早析構,見書 7.15.3 節 。
shared_ptr<Foo> sp1(new Foo); // ref_count.ptr 的類型是 Foo*
shared_ptr<void> sp2 = sp1; // 可以賦值,Foo* 向 void* 自動轉型
sp1.reset(); // 這時 Foo 對象的引用計數降為 1
此後 sp2 仍然能安全地管理 Foo 對象的生命期,並安全完整地釋放 Foo,不會出現 delete void* 的情況,因為 delete 的是 ref_count.ptr,不是 sp2.ptr。
3. 多繼承。假設 Bar 是 Foo 的多個基類之一,那麼:
shared_ptr<Foo> sp1(new Foo);
shared_ptr<Bar> sp2 = sp1; // 這時 sp1.ptr 和 sp2.ptr 可能指向不同的地址,因為 Bar subobject 在 Foo object 中的 offset 可能不 為0。
sp1.reset(); // 此時 Foo 對象的引用計數降為 1
但是 sp2 仍然能安全地管理 Foo 對象的生命期,並安全完整地釋放 Foo,因為 delete 的不是 Bar*,而是原來的 Foo*。換句話說 ,sp2.ptr 和 ref_count.ptr 可能具有不同的值(當然它們的類型也不同)。
為什麼要盡量 使用 make_shared()?
為了節省一次內存分配,原來 shared_ptr<Foo> x(new Foo); 需要為 Foo 和 ref_count 各分配一次內存,現在用 make_shared() 的話,可以一次分配一塊足夠大 的內存,供 Foo 和 ref_count 對象容身。數據結構是:
不過 Foo 的構造函數參 數要傳給 make_shared(),後者再傳給 Foo::Foo(),這只有在 C++11 裡通過 perfect forwarding 才 能完美解決。