std::set/std::map (以下用 std::map 代表) 是常用的關聯式容器,也是 ADT(抽象數據類型) 。也就是說,其接口(不是 OO 意義下的 interface)不僅規定了操作的功能,還規定了操作的復雜度 (代價/cost)。例如 set::insert(iterator first, iterator last) 在通常情況下是 O(N log N), N 是區間的長度;但是如果 [first, last) 已經排好序(在 key_compare 意義下),那麼復雜度將會 是 O(N)。
盡管 C++ 標准沒有強求 std::map 底層的數據結構,但是根據其規定的時間復雜度 ,現在所有的 STL 實現都采用平衡二叉樹來實現 std::map,而且用的都是紅黑樹。《算法導論(第 2 版)》第 12、13 章介紹了二叉搜索樹和紅黑樹的原理、性質、偽代碼,侯捷先生的《STL 源碼剖析》 第 5 章詳細剖析了 SGI STL 的對應實現。本文對 STL 中紅黑樹(rb_tree)的實現問了幾個稍微深入 一點的問題,並給出了我的理解。本文剖析的是 G++ 4.7 自帶的這一份 STL 實現及其特定行為,與《 STL 源碼剖析》的版本略有區別。為了便於閱讀,文中的變量名和 class 名都略有改寫(例如 _Rb_tree_node 改為 rb_tree_node)。本文不談紅黑樹的平衡算法,在我看來這屬於“旁枝末節”( 見陳碩《談一談網絡編程學習經驗》對此的定義),因此也就不關心節點的具體顏色了。
數據 結構回顧
先回顧一下數據結構教材上講的二叉搜索樹的結構,節點(Node)一般有三個數據成 員(left、right、data),樹(Tree)有一到兩個成員(root 和 node_count)。
用
Python 表示:
class Node:
def __init__(self, data):
self.left = None
self.right = None
self.data = data
class Tree:
def __init__(self):
self.root = None
self.node_count = 0
而實際上 STL rb_tree 的結構比這個要略微復雜一些,我整理的代碼見 https://gist.github.com/4574621#file-tree-structure-cc 。
節點
Node 有 5 個成 員,除了 left、right、data,還有 color 和 parent。
C++實現,位於bits/stl_tree.h
/**
* Non-template code
**/
enum rb_tree_color { kRed, kBlack };
struct rb_tree_node_base
{
rb_tree_color color_;
rb_tree_node_base* parent_;
rb_tree_node_base* left_;
rb_tree_node_base* right_;
};
/**
* template code
**/
template<typename Value>
struct rb_tree_node : public rb_tree_node_base
{
Value value_field_;
};
見下圖。
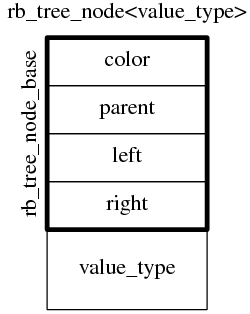
color 的存在很好理解 ,紅黑樹每個節點非紅即黑,需要保存其顏色(顏色只需要 1-bit 數據,一種節省內存的優化措施是 把顏色嵌入到某個指針的最高位或最低位,Linux 內核裡的 rbtree 是嵌入到 parent 的最低位); parent 的存在使得非遞歸遍歷成為可能,後面還將再談到這一點。
樹
Tree 有更多的成 員,它包含一個完整的 rb_tree_node_base(color/parent/left/right),還有 node_count 和 key_compare 這兩個額外的成員。
這裡省略了一些默認模板參數,如 key_compare 和
allocator。
template<typename Key, typename Value> // key_compare and allocator
class rb_tree
{
public:
typedef std::less<Key> key_compare;
typedef rb_tree_iterator<Value> iterator;
protected:
struct rb_tree_impl // : public node_allocator
{
key_compare key_compare_;
rb_tree_node_base header_;
size_t node_count_;
};
rb_tree_impl impl_;
};
template<typename Key, typename T> // key_compare and allocator
class map
{
public:
typedef std::pair<const Key, T> value_type;
private:
typedef rb_tree<Key, value_type> rep_type;
rep_type tree_;
};
見下圖。這是一顆空樹,其中陰影部分是 padding bytes,因為 key_compare 通常是 empty class。(allocator 在哪裡?)
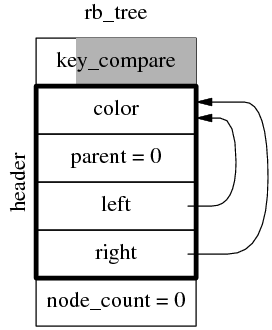
rb_tree 中的 header 不是 rb_tree_node 類型,而是 rb_tree_node_base,因此 rb_tree 的 size 是 6 * sizeof(void*) ,與模板類型參數無關。在 32-bit 上是 24 字節,在 64-bit 上是 48 字節,很容易用代碼驗證這一 點。另外容易驗證 std::set 和 std::map 的 sizeof() 是一樣的。
注意 rb_tree 中的 header 不是 root 節點,其 left 和 right 成員也不是指向左右子節點,而是指向最左邊節點 (left_most)和最右邊節點(right_most),後面將會介紹原因,是為了滿足時間復雜度。 header.parent 指向 root 節點,root.parent 指向 header,header 固定是紅色,root 固定是黑色 。在插入一個節點後,數據結構如下圖。
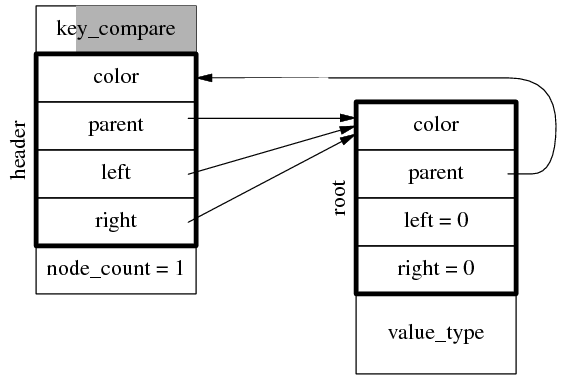
繼續插入兩個節點,假設分別位於 root 的左右兩側,那麼得到的數據結構如下圖所示(parent 指 針沒有全畫出來,因為其指向很明顯),注意 header.left 指向最左側節點,header.right 指向最右 側節點。
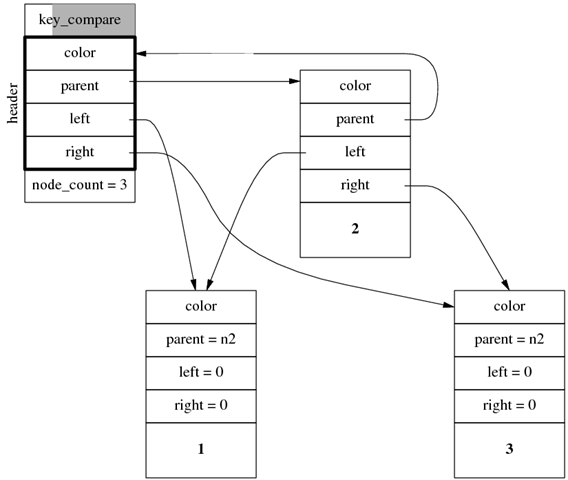
迭代器
rb_tree 的 iterator 的數據結構很簡單,只包含一個 rb_tree_node_base 指針, 但是其++/--操作卻不見得簡單(具體實現函數不在頭文件中,而在 libstdc++ 庫文件中)。
// defined in library, not in header
rb_tree_node_base* rb_tree_increment(rb_tree_node_base* node);
// others: decrement, reblance, etc.
template<typename Value>
struct rb_tree_node : public rb_tree_node_base
{
Value value_field_;
};
template<typename Value>
struct rb_tree_iterator
{
Value& operator*() const
{
return static_cast<rb_tree_node<Value>*>(node_)->value_field_;
}
rb_tree_iterator& operator++()
{
node_ = rb_tree_increment(node_);
return *this;
}
rb_tree_node_base* node_;
};
end() 始終指向 header 節點,begin() 指向第一個節點(如果有的話)。因此對於空樹, begin() 和 end() 都指向 header 節點。對於 1 個元素的樹,迭代器的指向如下。
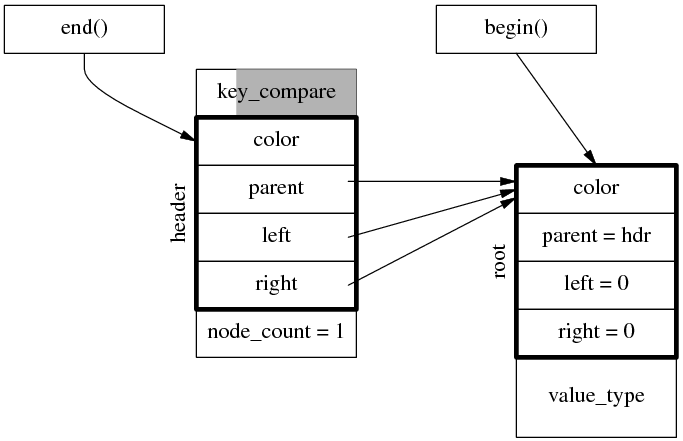
對於前面 3 個元素的樹,迭代器的指向如下。
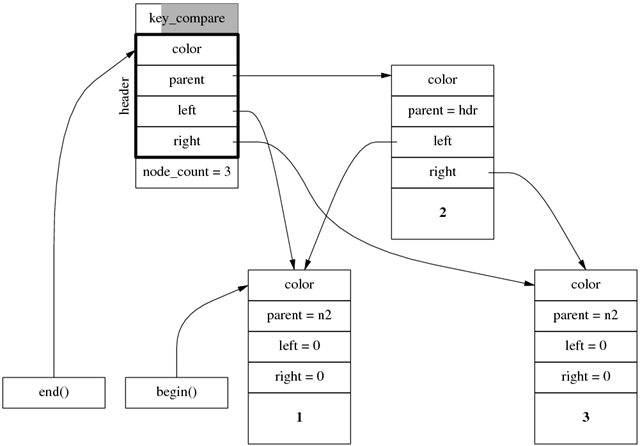
思考,對 std::set<int>::end() 做 dereference 會得到什麼?(按標准,這屬於 undefined behaviour,不過但試無妨。)
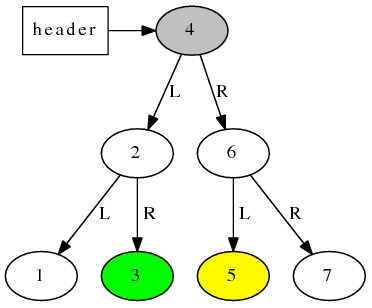
rb_tree 的 iterator 的遞增遞減操作並不簡單。考 慮下面這棵樹,假設迭代器 iter 指向綠色節點3,那麼 ++iter 之後它應該指向灰色節點 4,再 ++iter 之後,它應該指向黃色節點 5,這兩步遞增都各走過了 2 個指針。
對於一顆 更大的樹(下圖),假設迭代器 iter 指向綠色節點7,那麼 ++iter 之後它應該指向灰色節點 8,再 ++iter 之後,它應該指向黃色節點 9,這兩步遞增都各走過了 3 個指針。
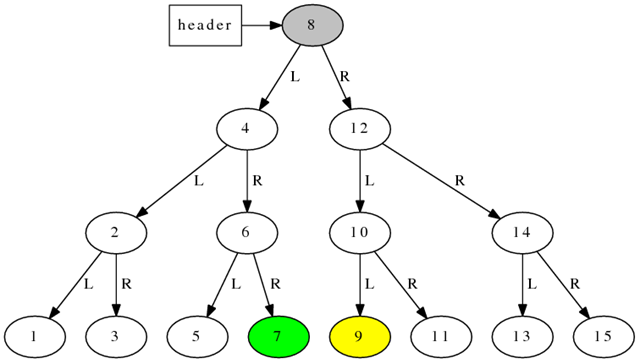
由此可見,rb_tree 的迭代器的每次遞增或遞減不能保證是常數時間,最壞情況下可能是對數時間 (即與樹的深度成正比)。那麼用 begin()/end() 迭代遍歷一棵樹還是不是 O(N)?換言之,迭代器的 遞增或遞減是否是分攤後的(amortized)常數時間?
另外注意到,當 iter 指向最右邊節點的 時候(7 或 15),++iter 應該指向 header 節點,即 end(),這一步是 O(log N)。同理,對 end() 做--,復雜度也是 O(log N),後面會用到這一事實。
rb_tree 迭代器的遞增遞減操作的實現也 不是那麼一目了然。要想從頭到尾遍歷一顆二叉樹(前序、中序、後序),教材上給出的辦法是用遞歸 (或者用 stack 模擬遞歸,性質一樣),比如:(https://gist.github.com/4574621#file-tree- traversal-py )
Python:
def printTree(node):
if node:
printTree(node.left)
print node.data
printTree(node.right)
如果考慮通用性,可以把函數作為參數進去,然後通過回調的方式來訪問每個節點,代碼如 下。Java XML 的 SAX 解析方式也是這樣。
Python:
def visit(node, func):
if node:
printTree(node.left)
func(node.data)
printTree(node.right)
要想使用更方便,在調用方用 for 循環就能從頭到尾遍歷 tree,那似乎就不那麼容易了。 在 Python 這種支持 coroutine 的語言中,可以用 yield 關鍵字配合遞歸來實現,代碼如下,與前面 的實現沒有多大區別。
在 Python 3.3 中還可以用 yield from,這裡用 Python 2.x 的寫法
。
def travel(root):
if root.left:
for x in travel(root.left):
yield x
yield root.data
if root.right:
for y in travel(root.right):
yield y
調用方:
for y in travel(root):
print y
但是在 C++ 中,要想做到最後這種 StAX 的遍歷方式,那麼迭代器的實現就麻煩多了,見《 STL 源碼剖析》第 5.2.4 節的詳細分析。這也是 node 中 parent 指針存在的原因,因為遞增操作時 ,如果當前節點沒有右子節點,就需要先回到父節點,再接著找。
空間復雜度
每個 rb_tree_node 直接包含了 value_type,其大小是 4 * sizeof(void*) + sizeof(value_type)。在實 際分配內存的時候還要 round up 到 allocator/malloc 的對齊字節數,通常 32-bit 是 8 字節,64 -bit 是 16 字節。因此 set<int>每個節點是 24 字節或 48 字節,100 萬個元素的 set<int> 在 x86-64 上將占用 48M 內存。說明用 set<int> 來排序整數是很不明智的行 為,無論從時間上還是空間上。
考慮 malloc 對齊的影響,set<int64_t> 和 set<int32_t> 占用相同的空間,set<int> 和 map<int, int> 占用相同的空間, 無論 32-bit 還是 64-bit 均如此。
幾個為什麼
對於 rb_tree 的數據結構,我們有幾 個問題:
1. 為什麼 rb_tree 沒有包含 allocator 成員?
2. 為什麼 iterator 可以 pass-by-value?
3. 為什麼 header 要有 left 成員,並指向 left most 節點?
4. 為 什麼 header 要有 right 成員,並指向 right most 節點?
5. 為什麼 header 要有 color 成 員,並且固定是紅色?
6. 為什麼要分為 rb_tree_node 和 rb_tree_node_base 兩層結構,引 入 node 基類的目的是什麼?
7. 為什麼 iterator 的遞增遞減是分攤(amortized)常數時間 ?
8. 為什麼 muduo 網絡庫的 Poller 要用 std::map<int, Channel*> 來管理文件描述 符?
我認為,在面試的時候能把上面前 7 個問題答得頭頭是道,足以說明對 STL 的 map/set 掌握得很好。下面一一解答。
為什麼 rb_tree 沒有包含 allocator 成員?
因為默認的 allocator 是 empty class (沒有數據成員,也沒有虛表指針vptr),為了節約 rb_tree 對象的大小 ,STL 在實現中用了 empty base class optimization。具體做法是 std::map 以 rb_tree 為成員, rb_tree 以 rb_tree_impl 為成員,而 rb_tree_impl 繼承自 allocator,這樣如果 allocator 是 empty class,那麼 rb_tree_impl 的大小就跟沒有基類時一樣。其他 STL 容器也使用了相同的優化措 施,因此 std::vector 對象是 3 個 words,std::list 對象是 2 個 words。boost 的 compressed_pair 也使用了相同的優化。
我認為,對於默認的 key_compare,應該也可以實施 同樣的優化,這樣每個 rb_tree 只需要 5 個 words,而不是 6 個。
為什麼 iterator 可以 pass-by-value?
讀過《Effective C++》的想必記得其中有個條款是 Prefer pass-by- reference-to-const to pass-by-value,即對象盡量以 const reference 方式傳參。這個條款同時指 出,對於內置類型、STL 迭代器和 STL 仿函數,pass-by-value 也是可以的,一般沒有性能損失。
在 x86-64 上,對於 rb_tree iterator 這種只有一個 pointer member 且沒有自定義 copy- ctor 的 class,pass-by-value 是可以通過寄存器進行的(例如函數的頭 4 個參數,by-value 返回 對象算一個參數),就像傳遞普通 int 和指針那樣。因此實際上可能比 pass-by-const-reference 略 快,因為callee 減少了一次 deference。
同樣的道理,muduo 中的 Date class 和 Timestamp class 也是明確設計來 pass-by-value 的,它們都只有一個 int/long 成員,按值拷貝不比 pass reference 慢。如果不分青紅皂白一律對 object 使用 pass-by-const-reference,固然算不上什麼錯 誤,不免稍微顯得知其然不知其所以然罷了。
為什麼 header 要有 left 成員,並指向 left most 節點?
原因很簡單,讓 begin() 函數是 O(1)。假如 header 中只有 parent 沒有 left ,begin() 將會是 O(log N),因為要從 root 出發,走 log N 步,才能到達 left most。現在 begin() 只需要用 header.left 構造 iterator 並返回即可。
為什麼 header 要有 right 成 員,並指向 right most 節點?
這個問題不是那麼顯而易見。end() 是 O(1),因為直接用 header 的地址構造 iterator 即可,不必使用 right most 節點。在源碼中有這麼一段注釋:
bits/stl_tree.h // Red-black tree class, designed for use in implementing STL // associative containers (set, multiset, map, and multimap). The // insertion and deletion algorithms are based on those in Cormen, // Leiserson, and Rivest, Introduction to Algorithms (MIT Press, // 1990), except that // // (1) the header cell is maintained with links not only to the root // but also to the leftmost node of the tree, to enable constant // time begin(), and to the rightmost node of the tree, to enable // linear time performance when used with the generic set algorithms // (set_union, etc.) // // (2) when a node being deleted has two children its successor node // is relinked into its place, rather than copied, so that the only // iterators invalidated are those referring to the deleted node.
這句話的意思是說,如果按大小順序插入元素,那麼將會是線性時間,而非 O(N log N)。即 下面這段代碼的運行時間與 N 成正比:
// 在 end() 按大小順序插入元素
std::set<int> s;
const int N = 1000 * 1000
for (int i = 0; i < N; ++i)
s.insert(s.end(), i);
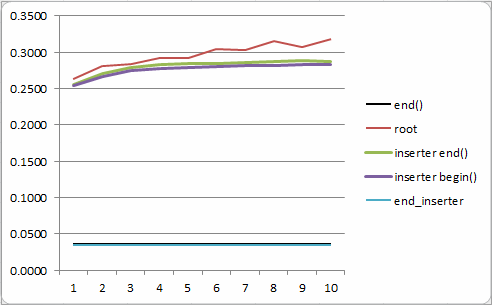
在 rb_tree 的實現中,insert(value) 一個元素通常的復雜度是 O(log N)。不過,insert (hint, value) 除了可以直接傳 value_type,還可以再傳一個 iterator 作為 hint,如果實際的插入 點恰好位於 hint 左右,那麼分攤後的復雜度是 O(1)。對於這裡的情況,既然每次都在 end() 插入, 而且插入的元素又都比 *(end()-1) 大,那麼 insert() 是 O(1)。在具體實現中,如果 hint 等於 end(),而且 value 比 right most 元素大,那麼直接在 right most 的右子節點插入新元素即可。這 裡 header.right 的意義在於讓我們能在常數時間取到 right most 節點的元素,從而保證 insert() 的復雜度(而不需要從 root 出發走 log N 步到達 right most)。具體的運行時間測試見 https://gist.github.com/4574621#file-tree-bench-cc ,測試結果如下,縱坐標是每個元素的耗時 (微秒),其中最上面的紅線是普通 insert(value),下面的藍線和黑線是 insert(end(), value), 確實可以大致看出 O(log N) 和 O(1) 關系。具體的證明見《算法導論(第 2 版》第 17 章中的思考 題 17-4。
查看本欄目
但是,根據測試結果, 前面引用的那段注釋其實是錯的,std::inserter() 與 set_union() 配合並不能實現 O(N) 復雜度。 原因是 std::inserter_iterator 會在每次插入之後做一次 ++iter,而這時 iter 正好指向 right most 節點,其++操作是 O(log N) 復雜度(前面提到過 end() 的遞減是 O(log N),這裡反過來也是 一樣)。於是把整個算法拖慢到了 O(N log N)。要想 set_union() 是線性復雜度,我們需要自己寫 inserter,見上面代碼中的 end_inserter 和 at_inserter,此處不再贅言。
為什麼 header 要有 color 成員,並且固定是紅色?
這是一個實現技巧,對 iterator 做遞減時,如果此刻 iterator 指向 end(),那麼應該走到 right most 節點。既然 iterator 只有一個數據成員,要想判 斷當前是否指向 end(),就只好判斷 (node_->color_ == kRed && node_->parent_- >parent_ == node_) 了。
為什麼要分為 rb_tree_node 和 rb_tree_node_base 兩層結構, 引入 node 基類的目的是什麼?
這是為了把迭代器的遞增遞減、樹的重新平衡等復雜函數從頭 文件移到庫文件中,減少模板引起的代碼膨脹(set<int> 和 set<string> 可以共享這些 的 rb_tree 基礎函數),也稍微加快編譯速度。引入 rb_tree_node_base 基類之後,這些操作就可以 以基類指針(與模板參數類型無關)為參數,因此函數定義不必放在在頭文件中。這也是我們在頭文件 裡看不到 iterator 的 ++/-- 的具體實現的原因,它們位於 libstdc++ 的庫文件源碼中。注意這裡的 基類不是為了 OOP,而純粹是一種實現技巧。
為什麼 iterator 的遞增遞減是分攤(amortized )常數時間?
嚴格的證明需要用到分攤分析(amortized analysis),一來我不會,二來寫出 來也沒多少人看,這裡我用一點歸納的辦法來說明這一點。考慮一種特殊情況,對前面圖中的滿二叉樹 (perfect binary tree)從頭到尾遍歷,計算迭代器一共走過多少步(即 follow 多少次指針),然 後除以節點數 N,就能得到平均每次遞增需要走多少步。既然紅黑樹是平衡的,那麼這個數字跟實際的 步數也相差不遠。
對於深度為 1 的滿二叉樹,有 1 個元素,從 begin() 到 end() 需要走 1 步,即從 root 到 header。
對於深度為 2 的滿二叉樹,有 3 個元素,從 begin() 到 end() 需要走 4 步,即 1->2->3->header,其中從 3 到 header 是兩步
對於深度為 3 的 滿二叉樹,有 7 個元素,從 begin() 到 end() 需要走 11 步,即先遍歷左子樹(4 步)、走 2 步到 達右子樹的最左節點,遍歷右子樹(4 步),最後走 1 步到達 end(),4 + 2 + 4 + 1 = 11。
對於深度為 4 的滿二叉樹,有 15 個元素,從 begin() 到 end() 需要走 26 步。即先遍歷左子樹 (11 步)、走 3 步到達右子樹的最左節點,遍歷右子樹(11 步),最後走 1 步到達 end(),11 + 3 + 11 + 1 = 26。
後面的幾個數字依次是 57、120、247
對於深度為 n 的滿二叉樹,有 2^n - 1 個元素,從 begin() 到 end() 需要走 f(n) 步。那麼 f(n) = 2*f(n-1) + n。
然後 ,用遞推關系求出 f(n) = sum(i * 2 ^ (n-i)) = 2^(n+1) - n - 2(這個等式可以用歸納法證明)。 即對於深度為 n 的滿二叉樹,從頭到尾遍歷的步數小於 2^(n+1) - 2,而元素個數是 2^n - 1,二者 一除,得到平均每個元素需要 2 步。因此可以說 rb_tree 的迭代器的遞增遞減是分攤後的常數時間。
似乎還有更簡單的證明方法,在從頭到尾遍歷的過程中,每條邊(edge)最多來回各走一遍, 一棵樹有 N 個節點,那麼有 N-1 條邊,最多走 2*(N-1)+1 步,也就是說平均每個節點需要 2 步,跟 上面的結果相同。
說一點題外話。
為什麼 muduo 網絡庫的 Poller 要用 std::map<int, Channel*> 來管理文件描述符?
muduo 在正常使用的時候會用 EPollPoller,是對 epoll(4) 的簡單封裝,其中用 std::map<int, Channel*> channels_ 來保 存 fd 到 Channel 對象的映射。我這裡沒有用數組,而是用 std::map,原因有幾點:
epoll_ctl() 是 O(lg N),因為內核中用紅黑樹來管理 fd。因此用戶態用數組管理 fd 並不能降低 時間復雜度,反而有可能增加內存使用(用 hash 倒是不錯)。不過考慮系統調用開銷,map vs. vector 的實際速度差別不明顯。(題外話:總是遇到有人說 epoll 是 O(1) 雲雲,其實 epoll_wait () 是 O(N),N 是活動fd的數目。poll 和 select 也都是 O(N),不過 N 的意義不同。仔細算下來, 恐怕只有 epoll_create() 是 O(1) 的。也有人想把 epoll 改為數組,但是被否決了,因為這是開歷 史倒車https://lkml.org/lkml/2008/1/8/205 。)
channels_ 只在 Channel 創建和銷毀的時候才會被訪問,其他時候(修改關注的讀寫事件)都是位 於 assert() 中,用於 Debug 模式斷言。而 Channel 的創建和銷毀本身就伴隨著 socket 的創建和銷 毀,涉及系統調用,channels_ 操作所占的比重極小。因此優化 channels_ 屬於優化 nop,是無意義 的。