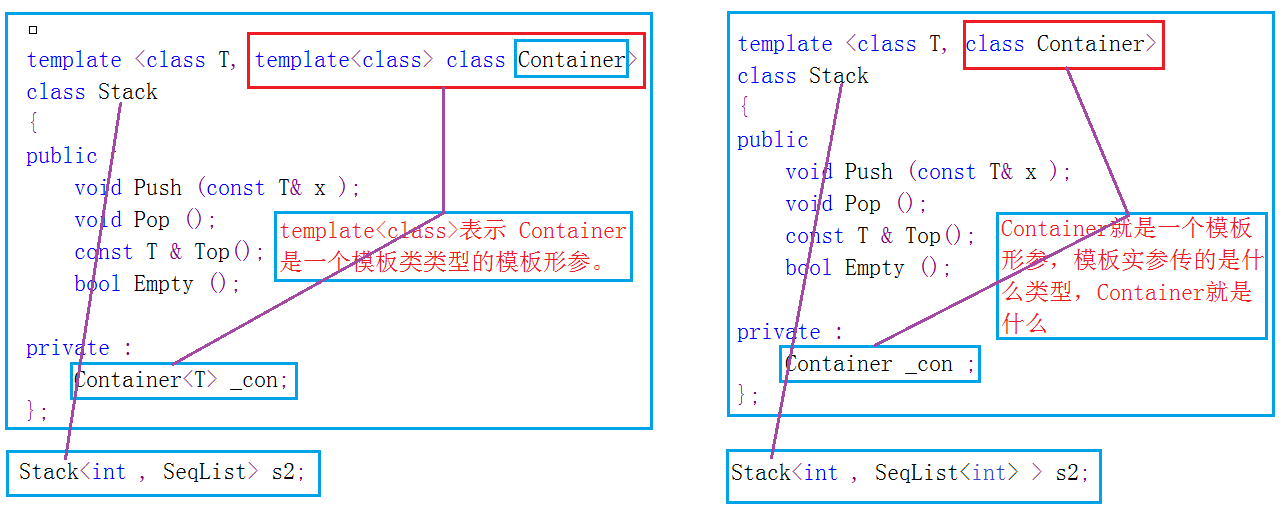
在經過艱難的討論template metaprogramming很長時間後,返回到我們學習的開始。
在這一部分,我們來了解模板編程的更為模糊的語法問題:在編譯器沒有充分的信息的情況下,怎樣引導編譯器進行分析。在這裡,我們將討論標准容器中用來消除歧義的“rebind”機制。同時,我們也將對一些潛在的模板編程技術進行熱烈的討論。
甚至經驗豐富的C++程序員,也常常被模板的復雜的語法所困擾。在所以模板語法中,我們首先要了解:消除編譯器分析的歧義,是最基本的語法困惑。
Types of Names, Names of Types
讓我們看看一個沒有實現標准容器的模板例子,這個例子很簡單。
template <typename T>
class PtrList {
public:
//...
typedef T *ElemT;
void insert( ElemT );
private:
//...
};
常常模板類嵌入Type names信息,這樣,我們就可以通過正確的nested name 獲得實例化的模板信息。
typedef PtrList<State> StateList;
//...
StateList::ElemT currentState = 0;
嵌入類型的ElenT允許我們可以,很容易的訪問PtrList模板的所承認的元素類型。
即使我們用State類型初始化PtrList,元素類型還將是State*。在其他一些情況下,PtrList 可以用指針元素實現。一個比較成熟的PtrList的實現,應該是可以隨著初始化的元素類型而變化的。使用nested type,可以幫助我們封裝PtrList,以免用戶了解內部的實現。
下面還有一個例子:
template <typename Etype>
class SCollection {
public:
//...
typedef Etype ElemT;
void insert( const Etype & );
private:
//...
};
SCollection的實現跟PtrList一樣,遵守標准命名的條款。遵守這些條款是有用的,這樣我們就可以寫出很多優雅的算法來使用這些容器(譯注:像標准模板庫一樣)。例如:可以寫一個如下的算法:用適當的元素類型來填充這個容器數組。
template <class Cont>
void fill( Cont &c, Cont::ElemT a[], int len ) { // error!
for( int i = 0; i < len; ++i )
c.insert( a[i] );
}
蹩腳的編譯器
很遺憾的是,在這裡我們有一個語法錯誤。編譯器不能識別Cont::ElemT這個type name。問題是在fill()的上下文中,沒有足夠的信息讓編譯器知道ElemT是一個type name。在標准中規定,在這種情況下,認為nested name 不是type name。 現在剛剛開始,如果你沒有理解,不要緊。我們來看看在不同的上下文中,編譯器所獲得的信息。首先,讓我們來看看在沒有模板的class的情況:
class MyContainer {
public:
typedef State ElemT;
//...
};
//...
MyContainer::ElemT *anElemPtr = 0;
由於編譯器可以檢測到MyContainer class的上下文確定有個ElemT的成員類型,從而可以確認MyContainer::ElemT確實是一個type name。在實例化的模板類中,其實,也跟這種情況一樣簡單。
typedef PtrList<State> StateList;
//...
StateList::ElemT aState = 0;
PtrList<State>::ElemT anotherState = 0;
對於編譯器來說,一個實例化的模板類跟一個普通的類一樣。在存儲PtrList<State>的nested name 和在MyContainer中是一樣的,沒有什麼差別。在其他情況下,編譯器也是這樣檢查上下文來看ElemT是不是type name。然而,當我們進入template的上下文後,事情就變得復雜了。因為在這,沒有充分的准確信息。考慮下面的程序片斷:
template <typename T>
void aFuncTemplate( T &arg ) {
...T::ElemT...
當編譯器遇到T::ElemT,它不知道這是什麼。從模板的申明中,編譯器知道,T是一個類型名。它通過::運算符也能猜測出T是一個類型名。但是,這就是所有編譯器知道的。因為,這裡沒有關於T的更多的信息。例如:我們能夠用PtrList來調用一個模板函數,在這裡,T::ElemT將是一個Type name。
PtrList<State> states;
//...
aFuncTemplate( states ); // T::ElemT is PtrList<State>::ElemT
But suppose we were to instantiate aFuncTemplate with a different type?
struct X {
double ElemT;
//...
};
X anX;
//...
aFuncTemplate( anX ); // T::ElemT is X::ElemT
在這個例子中,T::ElemT是數據類型,不是type name。編譯器將怎麼辦呢?在標准中規定,在這種情況下,編譯器將認為nested name 不是type name。在將在上述fill()模板函數中導致一個語法錯誤。
Clue In the Compiler
為了處理這種情況,我們必須清晰的提示編譯器:
這個nested name 是type name。如下:
template <typename T>
void aFuncTemplate( T &arg ) {
...typename T::ElemT...
在這裡,我們使用關鍵字typename 來告訴編譯器後面跟著的name,是type name。這樣使得編譯器可以正確的分析template。注意:我們告訴編譯器:ElemT而不是T,是Type name。當然,編譯器也能夠知道T也是type name。同樣,如果我們這樣寫:
typename A::B::C::D::E
這樣,我們就相當於告訴編譯器,E是type name。當然,如果模板函數傳入的類型不滿足template分解要求的話,會導致一個編譯時刻的編譯錯誤。
struct Z {
// no member named ElemT...
};
Z aZ;
//...
aFuncTemplate( aZ ); // error! no member Z::ElemT
aFuncTemplate( anX ); // error! X::ElemT is not a type name
aFuncTemplate( states ); // OK. PtrList<State>::ElemT is a type name
現在,我們可以重寫fill()模板函數,
void fill( Cont &c, typename Cont::ElemT a[], int len ) { // OK
for( int i = 0; i < len; ++i )
c.insert( a[i] );
}
Gotcha: Failure to Employ typename with Permissive Compilers
注意:
使用typename 要求 嵌入 type name,如果編譯器不能得到足夠的信息的話,在模板的外部使用typename是非法的。
PtrList<State>::ElemT elem; // OK
typename PtrList<State>::ElemT elem; // error!
在模板的上下文中,這是很常見的錯誤。考慮一個在模板,在它內部實現,在編譯時刻,從兩個類型中選出一個,例如:
Select<cond,int,int *>::R r1; // OK
typename Select<cond,int,int *>::R r2; // error!
//...
}
由於編譯器可以獲得所有模板參數的信息,因此,甚至不需要在Select前寫typename。如果,用模板重寫f(),我們就可以使用typename。
template <typename T>
void f() {
Select<cond,int,int *>::R r1; // #1: OK, typename not required
typename Select<cond,int,int *>::R r2; // #2: superfluous
Select<cond,T,T *>::R r3; // #3: error! need typename
typename Select<cond,T,T *>::R r4; // #4: OK
//...
}
在情況2中,typename,可以不寫,這樣是可以的。
最有問題的是情況3,很多編譯器都能察覺這個錯誤,將把這個嵌入的R解釋為type name(的確它是一個type name,但是沒有希望它解釋為type name)以後,如果,這段代碼出現在標准編譯器上,那麼會被查出錯誤的。因為這個原因,當你用C++模板編程,如果你必須使用非標准編譯器的,你最好使用高級標准編譯器,來檢查你的代碼。
Intermezzo: Expanding Monostate Protopattern
在模板問題上,我們先停頓一下,讓我們看看搜索技術。 當我們想避免Monostate常常是Singleton的很好替代技術。當為了避免全局變量帶來的麻煩時,Monostate是Singleton的很好替代品。
class Monostate {
public:
int getNum() const { return num_; }
void setNum( int num ) { num_ = num; }
const std::string &getName() const { return name_; }
private:
static int num_;
static std::string name_;
};
就像Singleton一樣,Monostate 提供對象的簡單copy,不像典型的Singleton,這種分享機制不是由構造函數實現的。而是通過存儲靜態成員。注意:Monostate不同於傳統的使用靜態成員機制,傳統的辦法是通過靜態成員函數來存儲靜態成員變量。 Monostate提供非靜態成員函數來存儲靜態成員變量。(譯注:好方法,我們來看作者怎麼實現的)
Monostate m1;
Monostate m2;
//...
m1.setNum( 12 );
cout << m2.getNum() << endl; // shift 12
每一個不同類型的Monostate分享相同的狀態。Monostate沒有使用任何特殊的語法,不像Singleton的實現。
Singleton::instance().setNum( 12 );
cout << Singleton::instance().getNum() << endl;
Expanding Monostate
如果我們想在Monostate中添加新的靜態成員,那麼該怎麼實現?理想的情況是不添加操作不需要改變源代碼,甚至不要重編譯不相關的代碼。讓我們來看看怎樣使用template來實現這個任務的。
class Monostate {
public:
template <typename T>
T &get() {
static T member;
return member;
}
};
注意:這個模板函數可以在編譯時,按需要初始化,很遺憾的,它不能是虛擬函數。這個版本的Monostate為分享靜態成員,實現了"lazy creation" 。
Monostate m;
m.get<int>() = 12; // create an int member
Monostate m2;
cout << m2.get<int>(); // access previously-created member
m2.get<std::string>() = "Hej!" // create a string member
注意: 不像傳統的Singleton的"lazy creation"那樣,這個"lazy creation"作用於編譯時刻,而不是運行時刻。
Indexed Expanding Monostate
這個辦法其實還很不理想,至少如果用戶想有多個分享的特殊類型的成員,那麼又該怎麼辦?一種改善的辦法是給模板成員函數添加一個參數“index”。
class IndexedMonostate {
public:
template <typename T, int i>
T &get();
};
template <typename T, int i>
T &IndexedMonostate::get() {
static T member;
return member;
}
現在,我們可以擁有多個特殊類型的成員了,但是這個接口還可以更加完善。
IndexedMonostate im1, im2;
im2.get<int,1066>() = 12;
im2.get<double,42>() = im2.get<int,1066>()+1;
Named Expanding Monostate
我們所需要的是記錄用戶的使用Monostate成員的類型。這個類型也是為模板函數的包裝的類型和static成員的實際類型。
template <typename T, int n>
struct Name {
typedef T Type;
};
這個Name類看上去很簡單,但是它已經足夠滿足要求。
typedef Name<int,86> grossAmount;
typedef Name<double,007> percentage;
現在我們可以可讀類型,而且還可以把成員類型和index綁定在一起。注意:這index對應的實際數值不是實質性的,只要[type,index] 是唯一的。一個命名的Monostate假定成員的類型能夠從它的初始化類型解壓。
class NamedMonostate {
public:
template <class N>
typename N::Type &get() {
static typename N::Type member;
return member;
}
};
這個提高用戶接口的技術是沒有犧牲原來技術的簡單性和方便性(注意:typename是告訴嵌入的N::Type是一個type name)。
可以這樣使用:
NamedMonostate nm1, nm2;
nm1.get<grossAmount>() = 12;
nm2.get<percentage>() = nm1.get<grossAmount>() + 12.2;
cout << nm1.get<grossAmount>() * nm2.get<percentage>() << endl;
最後,我們可以修改接口來使用Monostate。
class GSNamedMonostate {
public:
template <typename N>
void set( const typename N::Type &val ) {
// This const_cast is actually safe,
// since we are always actually getting
// a non-const object. (Unless N::Type is
// const, then you get a compile error here.)
const_cast<typename N::Type &>(get()) = val;
}
template <typename N>
const typename N::Type &get() const {
static typename N::Type member;
return member;
}
};
這是原型模式(Protopattern)嗎?
其實,像我們剛剛開始提到的一樣,這是搜索技術。同樣,我們沒有權利調用這樣的模式。一個設計模式是包裝了成功的實際成果的。這個"protopattern"通常應用在上下文中可以察覺的技術,因此,不能被應用於更加廣泛的“pattern”軟件中。由於我們不能指出它的成功之地方,所以,我們只能盡量擴展monostate這個模式。
Template Names in Templates
讓我們回到分析模板的編譯器問題上來吧。編譯器分析的難題,不僅只有嵌入type names,而且,我們還常常見到嵌入 template names 類似的問題。調用一個類,或類模板必須有一個這樣的成員。這個成員是一個類,或模板函數。
例如:一個使用模板成員函數的擴展Monostate可以按需要這樣初始化:
typedef Name<int,86> grossAmount;
typedef Name<double,007> percentage;
GSNamedMonostate nm1, nm2;
nm1.set<grossAmount>( 12 );
nm2.set<percentage>( nm1.get<grossAmount>() + 12.2 );
cout << nm1.get<grossAmount>() * nm2.get<percentage>() << endl;
在上面的代碼中,編譯器在檢查模板get不會碰到任何困難。 其中,nm1和nm2是GSNamedMonostate的類型名,編譯器可以在類裡面查詢get和set的類型。
然而,考慮寫這樣一個優雅的函數:它能夠用來移置擴展的Monostate object。
template <typename M>
void populate() {
M m;
m.get<grossAmount>(); // syntax error!
M *mp = &m;
mp->get<percentage>(); // syntax error!
}
又一次,問題出在編譯器不知道M足夠的信息,除了,知道它是type name外。特別是,如果沒有足夠的get<>信息的話,編譯器會認為它不是type,不是模板名。因此,m.get<grossAmount>()的中括號被解釋為大於號,和小於號,而不是模板參數列表。
這種情況下,解決辦法是要告訴編譯器<>是模板參數列表,而不是其他的操作名。
template <typename M>
void populate() {
M m;
m.template get<grossAmount>(); // OK
M *mp = &m;
mp->template get<percentage>(); // OK
}
是不是不可思議啊,就像分析使用typename一樣,這種template特殊的用法,僅在必要的情況下,才能使用。
Hints For Rebinding Allocators
我們也碰到嵌入模板類的同樣的分析問題,在STL allocator的實現,就是這樣的經典例子。
template <class T>
class AnAlloc {
public:
//...
template <class Other>
class rebind {
public:
typedef AnAlloc<Other> other;
};
//...
};
這個模板類AnAlloc中就有嵌入的name,而這個name本身就是一個模板類。這是使用STL的框架來創建allocators,就像allocators為一個容器用不同的數據類型初始化一樣。例如:
typedef AnAlloc<int> AI; // original allocator allocates ints
typedef AI::rebind<double>::other AD; // new one allocates doubles
typedef AnAlloc<double> AD; // legal! this is the same type
也許,這樣看起來是有些多余。但是使用rebind機制可以允許我們用現存的allocator為不同的數據類型工作,而且不需要知道當前的allocator類型和要allocate數據類型。
typedef SomeAlloc::rebind<ListNode>::other NewAlloc;
如果SomeAlloc要為STL的allocators提供方便的話,它要有嵌入的rebind 模板類。本質上說:“我們不要知道allocator的類型,也不要知道分配類型,但是,我想要一個像allocates ListNodes一樣的allocator”。
在模板中常常忽視這種工作,直到template 初始化後,變量的類型和值才能確定。考慮STL各種編譯List容器的實現,我們的模板列表有兩個模板參數,一個元素類型(T)和allocator type(A)。(像標准容器,我們list提供缺省的allocator )。
template < typename T, typename A = std::allocator<T> >
class OurList {
struct Node {
//...
};
typedef A::rebind<Node>::other NodeAlloc; // error!
};
作為典型基於lists基礎的容器,我們的list實際上不分配和操作元素Ts。而是,分配和操作T類型的容器。這種情況,就是我們前面所講述的。我們有allocator,它知道怎樣分配T類型的對象,但是,我們想分配OurList<T,A>::Node。然而,當我們嘗試這麼rebind的時候,我們會出現語法錯誤。 這個問題再一次是因為編譯器沒有A類型足夠的信息。因此,編譯器認為嵌入的rebind name不是模板name,同時,<>被解釋為大於,小於操作。但是,這只是我們問題的開始。就算編譯器能夠知道rebind 是template name,它也會認為不是type name。因此,必須這麼寫typedef。
typedef typename A::template rebind<Node>::other NodeAlloc;
關鍵字template告訴編譯器這個rebind是模板名,關鍵字typename告訴編譯器整個指向一個type name,很簡單吧。
參考資料和注意事項:
[1]這樣的接口並不總是一個好的主意。參考 Gotcha #80: Get/Set Interfaces in C++ Gotchas (Addison-Wesley, 2003).
[2]事實上,你也許可以不這樣做,盡管從哲學的角度來說,populate是一個很有意思的模板函數,它是為很多模板在編譯時刻初始化服務的。這樣,不需要在編譯時刻調用函數了(譯注:虛擬函數就是運行時刻初始化)然而,如果函數沒有調用,它將不被初始化,這種初始化也不將完成。其他可行的方法就是得到函數的地址,而不是調用函數,或者作一個明顯的初始化,這樣,如果,函數在運行時刻不需要,它也會存在。
[3]如果你不熟悉STL的allocator,你不要擔心,在以後的討論中,不需要對它熟悉。allocator就是一個類而已,只不過,它是用來為STL容器管理內存的。Allocators是模板類的典型的實現。
About the Author
Stephen C. Dewhurst (<www.semantics.org>) is the president of Semantics Consulting, Inc., located among the cranberry bogs of southeastern Massachusetts. He specializes in C++ consulting, and training in advanced C++ programming, STL, and design patterns. Steve is also one of the featured instructors of The C++ Seminar (<www.gotw.ca/cpp_seminar>