以下代碼經測試,排序5000000(五千萬)int型數
平時使用中,我們通常需要通過對自定義對象進行歸檔處理,
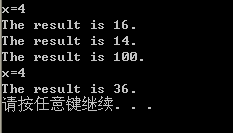
關於C語言函數調用壓棧和返回值問題的疑惑,函數返回值按照C編
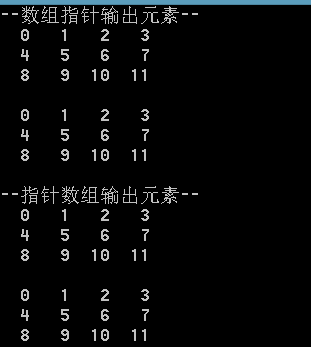
指針數組/數組指針,指針數組#include<iost
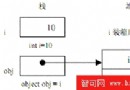
裝箱轉換是指將一個值類型隱式地轉換成一個object類型,
被用在匿名方法中的局部變量有著超出用到它們的外部常規方法的