介紹
本文描述在網上能夠找到的最簡單,最快速的哈夫曼編碼。本方 法不使用任何擴展動態庫,比如STL或者組件。只使用簡單的C函數,比如: memset,memmove,qsort,malloc,realloc和memcpy。
因此,大家都會發現 ,理解甚至修改這個編碼都是很容易的。
背景
哈夫曼壓縮是個無損的壓縮算法,一般用來壓縮文本和程序文件。哈夫 曼壓縮屬於可變代碼長度算法一族。意思是個體符號(例如,文本文件中的字符 )用一個特定長度的位序列替代。因此,在文件中出現頻率高的符號,使用短的 位序列,而那些很少出現的符號,則用較長的位序列。
編碼使用
我用簡單的C函數寫這個編碼是為了讓它在任何地方使用都會比較方便。你可以 將他們放到類中,或者直接使用這個函數。並且我使用了簡單的格式,僅僅輸入 輸出緩沖區,而不象其它文章中那樣,輸入輸出文件。
bool CompressHuffman(BYTE *pSrc, int nSrcLen, BYTE *&pDes, int &nDesLen);要點說明
bool DecompressHuffman(BYTE *pSrc, int nSrcLen, BYTE *&pDes, int &nDesLen);
速度
為了讓 它(huffman.cpp)快速運行,我花了很長時間。同時,我沒有使用任何動態庫, 比如STL或者MFC。它壓縮1M數據少於100ms(P3處理器,主頻1G)。
壓縮
壓縮代碼非常簡單,首先用ASCII值初始化511個哈夫曼節點:
CHuffmanNode nodes[511];然 後,計算在輸入緩沖區數據中,每個ASCII碼出現的頻率:
for(int nCount = 0; nCount < 256; nCount++)
nodes[nCount].byAscii = nCount;for(nCount = 0; nCount < nSrcLen; nCount++)然後,根據頻率進行排序:
nodes[pSrc [nCount]].nFrequency++;qsort (nodes, 256, sizeof(CHuffmanNode), frequencyCompare);現在,構造 哈夫曼樹,獲取每個ASCII碼對應的位序列:int nNodeCount = GetHuffmanTree(nodes);構造哈夫曼樹非常簡單,將所有的節點放到一 個隊列中,用一個節點替換兩個頻率最低的節點,新節點的頻率就是這兩個節點 的頻率之和。這樣,新節點就是兩個被替換節點的父節點了。如此循環,直到隊 列中只剩一個節點(樹根)。// parent node
pNode = &nodes[nParentNode++];
// pop first child
pNode- >pLeft = PopNode(pNodes, nBackNode--, false);
// pop second child
pNode->pRight = PopNode(pNodes, nBackNode--, true);
// adjust parent of the two poped nodes
pNode->pLeft- >pParent = pNode->pRight->pParent = pNode;
// adjust parent frequency
pNode->nFrequency = pNode->pLeft- >nFrequency + pNode->pRight->nFrequency;
這裡我用了一個 好的訣竅來避免使用任何隊列組件。我先前就直到ASCII碼只有256個,但我分配 了511個(CHuffmanNode nodes[511]),前255個記錄ASCII碼,而用後255個記錄 哈夫曼樹中的父節點。並且在構造樹的時候只使用一個指針數組(ChuffmanNode *pNodes[256])來指向這些節點。同樣使用兩個變量來操作隊列索引(int nParentNode = nNodeCount;nBackNode = nNodeCount –1)。
接著 ,壓縮的最後一步是將每個ASCII編碼寫入輸出緩沖區中:int nDesIndex = 0;
// loop to write codes
for(nCount = 0; nCount < nSrcLen; nCount++)
{
*(DWORD*)(pDesPtr+ (nDesIndex>>3)) |=
nodes[pSrc [nCount]].dwCode << (nDesIndex&7);
nDesIndex += nodes[pSrc[nCount]].nCodeLength;
}
(nDesIndex>>3): >>3 以8位為界限右移後到達右邊字節的前面
(nDesIndex&7): &7 得到最高位.
注意:在壓縮緩沖區中,我們必須保存哈夫曼樹的節點 以及位序列,這樣我們才能在解壓縮時重新構造哈夫曼樹(只需保存ASCII值和 對應的位序列)。
解壓縮
解壓縮比構造哈夫曼樹要簡單的多,將 輸入緩沖區中的每個編碼用對應的ASCII碼逐個替換就可以了。只要記住,這裡 的輸入緩沖區是一個包含每個ASCII值的編碼的位流。因此,為了用ASCII值替換 編碼,我們必須用位流搜索哈夫曼樹,直到發現一個葉節點,然後將它的ASCII 值添加到輸出緩沖區中:
int nDesIndex = 0;
DWORD nCode;
while(nDesIndex < nDesLen)
{
nCode = (*(DWORD*)(pSrc+(nSrcIndex>>3)))>>(nSrcIndex&7);
pNode = pRoot;
while(pNode->pLeft)
{
pNode = (nCode&1) ? pNode->pRight : pNode ->pLeft;
nCode >>= 1;
nSrcIndex++;
}
pDes[nDesIndex++] = pNode- >byAscii;
}
(nDesIndex>>3): >>3 以8位為界 限右移後到達右邊字節的前面
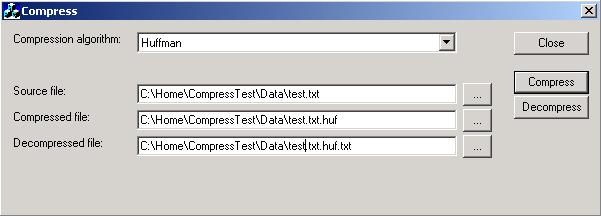
(nDesIndex&7): &7 得到最高位.源文 件: Huffman.cpp Huffman.h 請見本文提供的源代碼壓縮包。
本文配套源碼