TrueType字體在Windows平台下的應用很多,但是涉及到具體的操作層面上中文資料還是很少,遇到了不少問題苦惱了一陣子。
1、通過 CFontDialog 進行字體選擇,但是正常情況下得到的字體列表示當前系統中所有支持的字體,當然也包括其它一些非 TrueType 字體,要在 CFontDialog 的列表中剔出非 TrueType 的字體很簡單,只需在配置 CFontDialog 時如下設置:
CFontDialog dlg;
dlg.m_cf.Flags |= CF_TTONLY; //only enum TrueType
2、要遍歷所選擇的字體中所包含的所有字符,這個我們不禁想到可以通過 .ttf文件的解析來完成,但是如何得到選擇的字體所對應的 .ttf文件哪?同實際的操作,得知在CfontDialog中顯示的字體的名稱和所對應的.ttf文件不是一一對應的關系,例如:選擇的字體為 Arial 那麼在 System/Fonts/下卻沒有 Arial.ttf 的文件,在網上找了很多例子都不能百分百無誤的實現,在 codeproject 中有一個例子 Sample 通過注冊表的方法來查找,但是同樣存在上面的問題。而且即使能夠找到相對應的.ttf文件,要解析這個文件也很有困難,因為存在 ttc的問題(即:一個是一個ttf的集合,一個文件裡面有可能定義幾種 TrueType 字體),這樣還要根據選擇的字體然後在讀取ttf文件的過程中進行比較,找到描述這種這種字體的部分,後來發現選擇的字體有可能和文檔中定義的TrueType 字體名稱不一致,因為有中文字體的存在,這一部分我並沒有進行測試。因為在之後的解決過程找到了另外一種解決的方法。
DWORD CDC::GetFontData( DWORD dwTable, DWORD dwOffset, LPVOID lpData, DWORD cbData ) const;
Remarks
Retrieves font-metric information from a scalable font file. The information to retrieve is identified
by specifying an offset into the font file and the length of the information to return. An application
can sometimes use the GetFontData member function to save a TrueType font with a document. To do this,
the application determines whether the font can be embedded and then retrieves the entire font file,
specifying 0 for the dwTable, dwOffset, and cbData parameters.
通過上面的函數可以輕易的得到選入DC中的TrueType字體的 ttf文件中的數據,但是如果想得到整個的字體文件還是會存在ttc的問題,因為這個函數得到的數據是其中選擇的那種字體的數據,但是對於各個數據段offset的定義卻是針對於整個文檔的,如果直接引用就會有問題,也沒有找到其他更好的解決方法,但是卻可以准確地得到關於其中任意一個Table的數據,剛剛好對於字符集中所包含的字符的定於存在於"cmap" Table中,問題解決了,如下:
// Macro to pack a TrueType table name into a DWORD.
#define MAKETABLENAME(ch1, ch2, ch3, ch4) (\
(((DWORD)(ch4)) << 24) | \
(((DWORD)(ch3)) << 16) | \
(((DWORD)(ch2)) << 8) | \
((DWORD)(ch1))
)
DWORD tag = MAKETABLENAME( ''c'',''m'',''a'',''p'' );
DWORD size = m_pFontDC->GetFontData(tag,0, NULL, 0);
unsigned char *pBuffer = new unsigned char[size];
m_pFontDC->GetFontData(tag,0,pBuffer,size);
//do something with pBuffer
delete[] pBuffer;
其中具體的一些操作也可以參照 msdn 中的文章。之後就是解析ttf文件了,這要參考MS發布的TrueType Font規格書了,當然即使看懂了規格書,要自己做解析程序也是短時間難以完成的,還是讓我們來找找有沒有其他的已經有了的經驗,在這裡就要提到一個開源的項目了 fontforge 這是個日本人和台灣人維護的一個項目,可以支持多種字體進行解析和編輯,可以是個 Linux 下的程序,不過我們可以使用 Cygwin 來使這個程序在 Windows下運行起來,具體請參考 freefonts.oaka.org,但是這個程序太復雜太龐大了,我們一時半會 還不能理出頭緒來,幸好在 cle.linux.org 看到 fontfoge 中有一個小工具叫做 showttf.c 可以簡單的對於ttf文件進行解析,下載過來,進行編譯,很有效。之後將其改進成可以只針對於“cmap”數據進行解析,並得到字體中支持字符的分段。
/*
read a short(2 bytes) from a stream
**/
static int Getushort(unsigned char **ttf) {
unsigned char ch1 = **(ttf);
(*ttf)++;
unsigned char ch2 = **(ttf);
(*ttf)++;
return( (ch1<<8)|ch2 );
}
/*
read a long(4 bytes) from a stream
**/
static int Getlong(unsigned char **ttf) {
unsigned char ch1 = **(ttf);
(*ttf)++;
unsigned char ch2 = **(ttf);
(*ttf)++;
unsigned char ch3 = **(ttf);
(*ttf)++;
unsigned char ch4 = **(ttf);
(*ttf)++;
return( (ch1<<24)|(ch2<<16)|(ch3<<8)|ch4 );
}
/*
Parse the table of "cmap"
**/
BOOL ReadttfEncodings(unsigned char *start_addr)
{
BOOL bResult = TRUE;
unsigned char *ttf = start_addr;
//local variable
int i;
int nencs, version;
int enc = 0;
int platform, specific;
int offset, encoff;
int format, len;
int segCount;
unsigned short *endchars,*startchars;
version = Getushort(&ttf);
nencs = Getushort(&ttf);
if ( version!=0 && nencs==0 )
nencs = version;/* Sometimes they are backwards */
for ( i=0; i < nencs; ++i )
{
platform = Getushort(&ttf);
specific = Getushort(&ttf);
offset = Getlong(&ttf);
if ( platform==3 /*&& (specific==1 || specific==5)*/)
{
enc = 1;
encoff = offset;
} else if ( platform==1 && specific==0 && enc!=1 )
{
enc = 2;
encoff = offset;
} else if ( platform==1 && specific==1 )
{
enc = 1;
encoff = offset;
} else if ( platform==0 ) {
enc = 1;
encoff = offset;
}
if ( platform==3 )
{
//MS Symbol
}
else if ( platform==1 )
{
//Mac Roman;
}
else if ( platform==0 )
{
//Unicode Default
}
else{}
}
if ( enc!=0 )
{
//reset pointer address
ttf = start_addr + encoff;
format = Getushort(&ttf);
if ( format!=12 && format!=10 && format!=8 )
{
len = Getushort(&ttf);
/*Language*/ Getushort(&ttf);
}
else
{
/* padding */ Getushort(&ttf);
len = Getlong(&ttf);
/*Format*/ Getlong(&ttf);
}
if ( format==0 )
{
//can''t be supported
bResult = FALSE;
}
else if ( format==4 )
{
//Format 4 (Windows unicode),only supported Format 4
segCount = Getushort(&ttf)/2;
/* searchRange = */ Getushort(&ttf);
/* entrySelector = */ Getushort(&ttf);
/* rangeShift = */ Getushort(&ttf);
endchars = new unsigned short[segCount];
for ( i=0; i < segCount; ++i )
endchars[i] = Getushort(&ttf);
if ( Getushort(&ttf)!=0 )
{
//Expected 0 in true type font;
}
startchars = new unsigned short[segCount];
for ( i=0; i < segCount; ++i )
startchars[i] = Getushort(&ttf);
//do something with endchars & startchars
delete[] startchars;
delete[] endchars;
}
else if ( format==6 )
{
/* Apple''s unicode format */
/* Well, the docs say it''s for 2byte encodings, but Apple actually*/
/* uses it for 1 byte encodings which don''t fit into the require-*/
/* ments for a format 0 sub-table. See Zapfino.dfont */
//can''t be supported
bResult = FALSE;
}
else if ( format==2 )
{
//can''t be supported
bResult = FALSE;
}
else if ( format==12 )
{
//can''t be supported
bResult = FALSE;
}
else if ( format==8 )
{
// fprintf(stderr,"I don''t support mixed 16/32 bit
// characters (no unicode surogates), format=%d", format);
// can''t be supported
bResult = FALSE;
}
else if ( format==10 )
{
//fprintf(stderr,"I don''t support 32 bit characters format=%d", format);
//can''t be supported
bResult = FALSE;
}
else
{
//fprintf(stderr,"Eh? Unknown encoding format=%d", format);
//can''t be supported
bResult = FALSE;
}
}
return bResult;
}
3、通過選入字體的DC得到字體的點陣數據,這個處理依靠如下的函數, DWORD GetGlyphOutline( UINT nChar,
UINT nFormat,
LPGLYPHMETRICS lpgm,
DWORD cbBuffer,
LPVOID lpBuffer,
const MAT2 FAR* lpmat2 ) const;
Remarks
Retrieves the outline curve or bitmap for an outline character in the current font.
具體請參考 msdn 可以得到 anti-alias 等多種格式的數據。但是這個有一個問題就是如果對應一個字體的size的各個參數,這裡面的麻煩很多,後來總結如下如下:
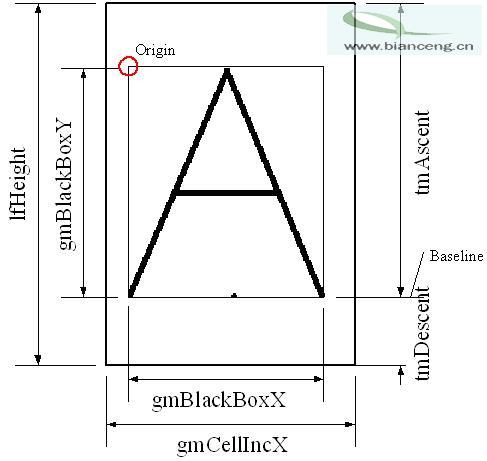
還有補充的就是 GetGlyphOutline 數據是有一定的對齊方式的,要進行一些處理,代碼如下:
BOOL CreateFontMatrix(int iAA,
UINT nChar,
unsigned char **pOutPut,
int *iBytesPreLine,
int *iLine,
int *iBaseLine,
int *iBox_x,
int *iBox_y)
{
unsigned char *pBuf;
TEXTMETRIC tm;
GLYPHMETRICS glyph;
int width,height,box_x,box_y,ori_x,ori_y,size,iAdjust;
BOOL bRel = TRUE;
MAT2 mat2 =
{
{ 0, 1, },
{ 0, 0, },
{ 0, 0, },
{ 0, 1, }
};
//Get glyph outline
memset(&glyph,0,sizeof(GLYPHMETRICS));
size = m_pFontDC->GetGlyphOutline(nChar,m_nFormat,&glyph,0,NULL,&mat2);
if (size >= 0) // if char is space, the size may be zero
{
int count = 0;
int data = 0;
pBuf = new unsigned char[size];
m_pFontDC->GetTextMetrics(&tm);
m_pFontDC->GetGlyphOutline(nChar,m_nFormat,&glyph,size,pBuf,&mat2);
ori_x = glyph.gmptGlyphOrigin.x;
//if ori_x is negative,set ori_x zero
ori_x = (ori_x < 0) ? 0 : ori_x;
ori_y = tm.tmAscent - glyph.gmptGlyphOrigin.y;
box_x = glyph.gmBlackBoxX;
box_y = glyph.gmBlackBoxY;
width = glyph.gmCellIncX;
iAdjust = (box_x+3)&0xfffc; //DWORD align
if((box_x + ori_x) > width)
box_x = width - ori_x;
height= m_pLf->lfHeight;
//convert
int index = 0;
if (iAA == AA_2)
{
width = (width%4 == 0)?width/4:(width/4+1); //here,to 2bits/pix
*pOutPut = new unsigned char[width*height + 1];
memset(*pOutPut,0,width*height + 1);
//if size == 0 all data is 0
if(size > 0)
{
for (int i = 0; i < box_y; i++)
{
for (int j = 0; j < box_x; j++)
{
//int k = pBuf[i*iAdjust + j];
data = AA2_GRAG_MATRIX[pBuf[i*iAdjust + j]];
index = (i + ori_y)*width + (j + ori_x)/4;
switch((j + ori_x)%4)
{
case 0:
(*pOutPut)[index] |= (data<<6)&0xC0;
break;
case 1:
(*pOutPut)[index] |= (data<<4)&0x30;
break;
case 2:
(*pOutPut)[index] |= (data<<2)&0x0C;
break;
case 3:
(*pOutPut)[index] |= data&0x03;
break;
default:
{}
}
}//end j
}//end i
}
}//end AA 2*2
else if (iAA == AA_4)
{
width = (width%2 == 0)?width/2:(width/2+1); //here,to 4bits/pix
*pOutPut = new unsigned char[width*height + 1];
memset(*pOutPut,0,width*height + 1);
//if size == 0 all data is 0
if(size > 0)
{
for (int i = 0; i < box_y; i++)
{
for (int j = 0; j < box_x; j++)
{
ASSERT(pBuf[i*iAdjust + j] <= 17);
data = AA4_GRAG_MATRIX[pBuf[i*iAdjust + j]];
index = (i + ori_y)*width + (j + ori_x)/2;
switch((j + ori_x)%2)
{
case 0:
(*pOutPut)[index] |= (data<<4)&0xF0;
break;
case 1:
(*pOutPut)[index] |= data&0x0F;
break;
default:
{}
}
}//end j
}//end i
}
}//end AA 4*4
else //start Normal
{
//Note: monochrome bitmap,the first data in pBuff is on the Left-bottom
// one bit per pix
width = (width%8 == 0)?width/8:(width/8+1); //here,to 4bits/pix
if (width == 0)
width = 1;
*pOutPut = new unsigned char[width*height + 1];
memset(*pOutPut,0,width*height + 1);
//if size == 0 all data is 0
if(size > 0)
{
for (int i = 0; i < box_y; i++)
{
for (int j = 0; j < width; j++)
{
(*pOutPut)[(i + ori_y)*width + j] |= data<<(8-ori_x);
data = pBuf[i*(size/box_y) + j];
(*pOutPut)[(i + ori_y)*width + j] |= data>>ori_x;
}//end j
}//end i
}
}//end else(normal bitmap)
if(pBuf != NULL)
delete[] pBuf;
//set return result
*iBytesPreLine = width;
*iLine = height;
*iBaseLine = tm.tmAscent;
*iBox_x = glyph.gmCellIncX;//box_x;
*iBox_y = box_y;
bRel = TRUE;
}
else//if size
bRel = FALSE;
return bRel;
}
結束語
得於8小時之內,寫於8小時之外。