在操作PDF文件時會遇到PDF文件加密了,不能操作的問題,從網絡中查找資料一上午,鼓搗出如下的代碼,可實現將已加密的PDF轉化成未加密的PDF文件,純代碼,無需借助PDF解密軟件,使用前需要導入如下引用,使用的itextsharp版本為5.5.9.0。
1 using iTextSharp.text.pdf; 2 using iTextSharp.text; 3 using System.IO;
1 /// <summary>
2 /// 將去掉PDF的加密
3 /// </summary>
4 /// <param name="sourceFullName">源文件路徑(如:D:\old.pdf)</param>
5 /// <param name="newFullName">目標文件路徑(如:D:\new.pdf)</param>
6 private static void deletePDFEncrypt(string sourceFullName, string newFullName)
7 {
8 if (string.IsNullOrEmpty(sourceFullName) || string.IsNullOrEmpty(newFullName))
9 {
10 throw new Exception("源文件路徑或目標文件路徑不能為空或null.");
11 }
12 //Console.WriteLine("讀取PDF文檔");
13 try
14 {
15 // 創建一個PdfReader對象
16 PdfReader reader = new PdfReader(sourceFullName);
17 PdfReader.unethicalreading = true;
18 // 獲得文檔頁數
19 int n = reader.NumberOfPages;
20 // 獲得第一頁的大小
21 Rectangle pagesize = reader.GetPageSize(1);
22 float width = pagesize.Width;
23 float height = pagesize.Height;
24 // 創建一個文檔變量
25 Document document = new Document(pagesize, 50, 50, 50, 50);
26 // 創建該文檔
27 PdfWriter writer = PdfWriter.GetInstance(document, new FileStream(newFullName, FileMode.Create));
28 // 打開文檔
29 document.Open();
30 // 添加內容
31 PdfContentByte cb = writer.DirectContent;
32 int i = 0;
33 int p = 0;
34 while (i < n)
35 {
36 document.NewPage();
37 p++;
38 i++;
39 PdfImportedPage page1 = writer.GetImportedPage(reader, i);
40 cb.AddTemplate(page1, 1f, 0, 0, 1f, 0, 0);
41 }
42 // 關閉文檔
43 document.Close();
44 }
45 catch (Exception ex)
46 {
47 throw new Exception(ex.Message);
48 }
49 }
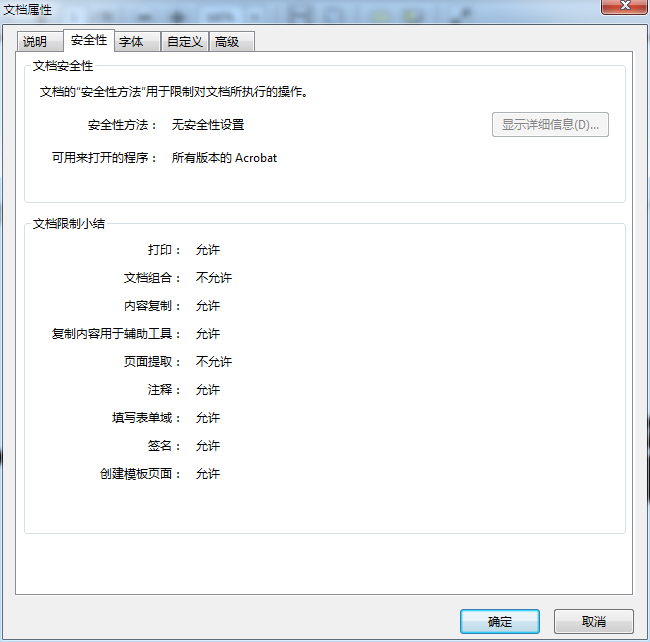
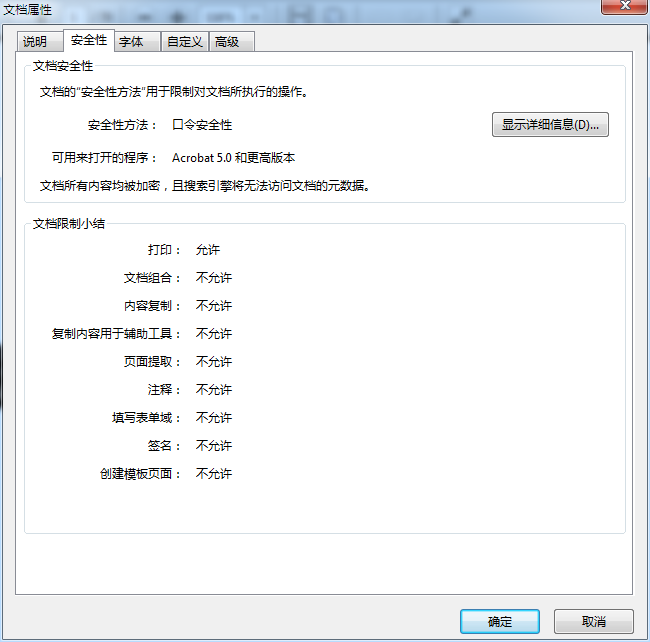
使用代碼轉換之前PDF的屬性如下圖:
轉換之後: