本人作為一位web工程師,著眼最多之處莫過於 性能與架構,本次幸得參與sd2.0大會,得以與同行廣泛交流,於此二方面,有些心得,不敢獨享,與眾博友分享,本文是這次參會與眾同撩交流的心得,有興趣者可以查看視頻
架構設計的幾個心得:
一,不要過設計:never over design
這是一個常常被提及的話題,但是只要想想你的架構裡有多少功能是根本沒有用到,或者最後廢棄的,就能明白其重要性了,初涉架構設計,往往傾向於設計大而化一的架構,希望設計出具有無比擴展性,能適應一切需求的增加架構,web開發領域是個非常動態的過程,我們很難預測下個星期的變化,而又需要對變化做出最快最有效的響應。。
ebay的工程師說過,他們的架構設計從來都不能滿足系統的增長,所以他們的系統永遠都在推翻重做。請注意,不是ebay架構師的能力有問題,他們設計的架構總是建立舊版本的瓶頸上,希望通過新的架構帶來突破,然而新架構帶來的突破總是在很短的時間內就被新增需求淹沒,於是他們不得不又使用新的架構
web開發,是個非常敏捷的過程,變化隨時都在產生,用戶需求千變萬化,許多方面偶然性非常高,較之軟件開發,希望用一個架構規劃以後的所有設計,是不現實的
二,web架構生命周期:web architecture‘s life cycle
既然要杜絕過設計,又要保證一定的前瞻性,那麼怎麼才能找到其中的平衡呢?希望下面的web架構生命周期能夠幫到你
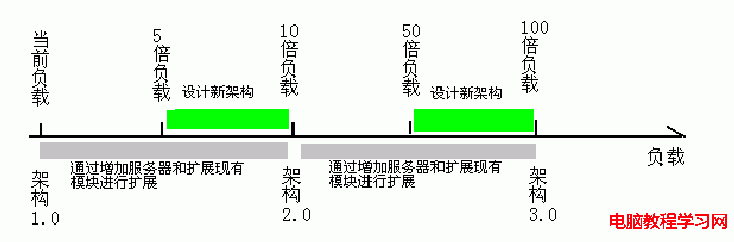
所設計的架構需要在1-10倍的增長下,通過簡單的增加硬件容量就能夠勝任,而在5-10倍的增長期間,請著手下一個版本的架構設計,使之能承受下一個10倍間的增長
google之所以能夠稱霸,不完全是因為搜索技術和排序技術有多先進,其實包括baidu和yahoo,所使用的技術現在也已經大同小異,然而,google能在一個月內通過增加上萬台服務器來達到足夠系統容量的能力確是很難被復制的
三,緩存:Cache
空間換取時間,緩存永遠計算機設計的重中之重,從cpu到io,到處都可以看到緩存的身影,web架構設計重,緩存設計必不可少,關於怎樣設計合理的緩存,jbosscache的創始人,淘寶的創始人是這樣說的:其實設計web緩存和企業級緩存是非常不同的,企業級緩存偏重於邏輯,而web緩存,簡單快速為好。。
緩存帶來的問題是什麼?是程序的復雜度上升,因為數據散布在多個進程,所以同步就是一個麻煩的問題,加上集群,復雜度會進一步提高,在實際運用中,采用怎樣的同步策略常常需要和業務綁定
老錢為搜狐設計的帖子設計了鏈表緩存,這樣既可以滿足靈活插入的需要,又能夠快速閱讀,而其他一些大型社區也經常采用類此的結構來優化帖子列表,memcache也是一個常常用到的工具
錢宏武談架構設計視頻 http://211.100.26.82/CSDN_Live/140/qhw.flv
Cache的常用的策略是:讓數據在內存中,而不是在比較耗時的磁盤上。從這個角度講,mysql提供的heap引擎(存儲方式)也是一個值得思考的方法,這種存儲方法可以把數據存儲在內存中,並且保留sql強大的查詢能力,是不是一舉兩得呢?
我們這裡只說到了讀緩存,其實還有一種寫緩存,在以內容為主的社區裡比較少用到,因為這樣的社區最主要需要解決的問題是讀問題,但是在處理能力低於請求能力時,或者單個希望請求先被緩存形成塊,然後批量處理時,寫緩存就出現了,在交互性很強的社區設計裡我們很容易找到這樣的緩存
四,核心模塊一定要自己開發:DIY your core module
這點我們是深有體會,錢宏武和雲風也都有談到,我們經常傾向於使用一些開源模塊,如果不涉及核心模塊,確實是可以的,如果涉及,那麼就要小心了,因為當訪問量達到一定的程度,這些模塊往往都有這樣那樣的問題,當然我們可以把問題歸結為對開源的模塊不熟悉,但是不管怎樣,核心出現問題的時候,不能完全掌握其代碼是非常可怕的
五,合理選擇數據存儲方式:reasonable data storage
我們一定要使用數據庫嗎,不一定,雷鳴告訴我們搜索不一定需要數據庫,雲風告訴我們,游戲不一定需要數據庫,那麼什麼時候我們才需要數據庫呢,為什麼不干脆用文件來代替他呢?
首先我們需要先承認,數據庫也是對文件進行操作。我們需要數據庫,主要是使用下面這幾個功能,一個是數據存儲,一個是數據檢索,在關系數據庫中,我們其實非常在乎數據庫的復雜搜索的能力,看看一個統計用的tsql就知道了(不用仔細讀,掃一眼就可以了)
select c.Class_name,d.Class_name_2,a.Creativity_Title,b.User_name,(select count(Id) from review where Reviewid=a.Id) as countNum from Creativity as a,User_info as b,class as c,class2 as d where a.user_id=b.id and a.Creativity_Class=c.Id and a.Creativity_Class_2=d.Id
select a.Id,max(c.Class_name),(max(d.Class_name_2),max(a.Creativity_Title),max(b.User_name),count(e.Id) as countNum from Creativity as a,User_info as b,class as c,class2 as d,review as e where a.user_id=b.id and a.Creativity_Class=c.Id and a.Creativity_Class_2=d.Id and a.Id=e.Reviewid group by a.Id ..............................................
我們可以看出需要數據庫關聯,排序的能力,這個能力在某些情況下非常重要,但是如果你的網站的常規操作,全是這樣復雜的邏輯,那效率一定是非常低的,所以我們常常在數據庫裡加入許多冗余字段,來減小簡單查詢時關聯等操作帶來的壓力,我們看看下面這張圖,可以看到數據庫的設計重心,和網站(指內容型社區)需要面對的問題實際是有一些偏差的
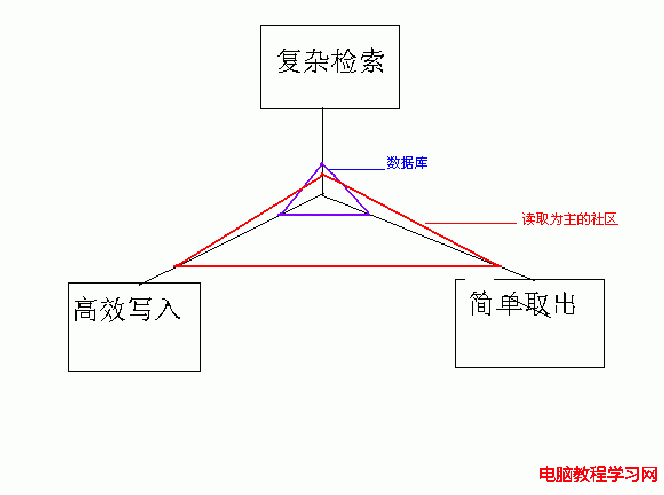
同樣其他一些軟件產品也遇到同樣的問題所以具我了解,有許多特殊的運用都有自己設計的特殊數據存儲結構與方法,比如有的大型服務程序采取樹形數據存儲結構,lucene使用文件來存儲索引和文件
從另外一個角度上看,使用數據庫,意味著數據和表現是完全分離的(這當然是經典的設計思路),也就是說當需要展示數據時,不得不需要一個轉換的過程,也可以說是綁定的過程,當網站具備一定規模的時候,數據庫往往成為效率的瓶頸,所以許多網站也采用直接書寫靜態文件的方法來避免讀取操作時的綁定
這並不是說我們從今天起就可以把我們親愛的數據庫打入冷宮,而是我們在設計數據的持久化時,需要根據實際情況來選擇存儲方式,而數據庫不過是其中一個選項