上一篇文章介紹了Kinect for Windows SDK進階開發需要了解的一些內容,包括影像處理Coding4Fun Kinect工具類庫以及如何建立自己的擴展方法類庫來方便開發,接下來介紹了利用Kinect進行近距離探測的一些方法,限於篇幅原因,僅僅介紹了近距離探測的三種方式。
本文接上文將繼續介紹近距離探測中如何探測運動,如何獲取並保存產生的影像數據;然後將會介紹如何進行臉部識別,以及介紹全息圖(Holograme)的一些知識,最後介紹了一些值得關注的類庫和項目。
2.4 運動識別
目前,利用運動識別(motion detection)來進行近景識別是最有意思的一種方式。實現運動識別的基本原理是設置一個起始的基准RGB圖像,然後將從攝像頭獲取的每一幀影像和這個基准圖像進行比較。如果發現了差異,我們可以認為有東西進入到了攝像頭的視野范圍。
不難看出這種策略是有缺陷的。在現實生活中,物體是運動的。在一個房間裡,某個人可能會輕微移動家具。在戶外,一輛汽車可能會啟動,風可能會將一些小樹吹的搖搖晃晃。在這些場景中,盡然沒有連續的移動動作,但是物體的狀態還是發生了變化,依據之前的策略,系統會判斷錯誤。因此,在這些情況下,我們需要間歇性的更改基准圖像才能解決這一問題。
與我們之前遇到的問題相比,完成這些任務看起來需要更強大的圖像分析處理工具。幸好,之前介紹的開源OpenCV庫提供了某種復雜的實時圖像處理操作的能力。OpenCV是Intel公司在1999年發起的一個項目,它將一些高級的視覺研究成果加入到OpenCV庫中並開源貢獻給了全世界。2008年,一個名為Willow Garage的科技孵化公司負責對該項目的更新和維護。幾乎同時EmguCV項目開始發起,他提供了對OpenCV的.Net包裝,使得我們在.Net環境下能夠使用OpenCV庫中的函數。下面我們將使用EmguCV來完成運動檢測以及後面的幾個演示項目。
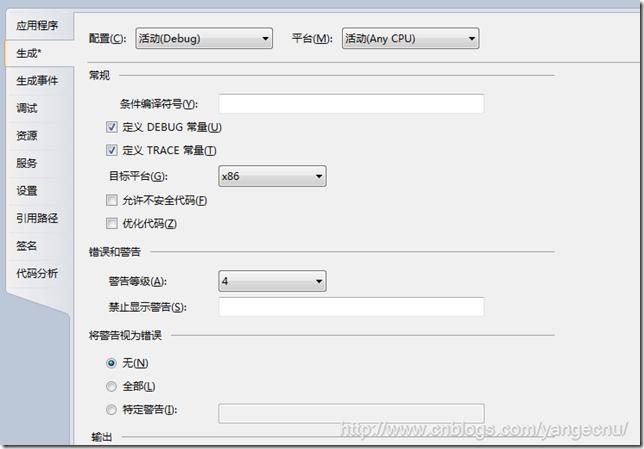
EmguCV項目的官方網站為http://www.emgu.com/wiki/index.php/Main_Page 實際的源代碼和安裝包放在SourceForge( http://sourceforge.net/projects/emgucv/files/ )上。本文使用的Emgu版本為2.3.0。Emgu的安裝過程很簡單直觀,只需要點擊下載好的可執行文件即可。不過有一點需要注意的是EmguCV似乎在x86架構的計算機上運行的最好。如果在64位的機器上開發,最好為Emgu庫的目標平台指定為x86,如下圖所示(你也可以在官網上下載源碼然後自己在x64平台上編譯)。
要使用Emgu庫,需要添加對下面三個dll的引用:Emgu.CV、Emgu.CV.UI以及Emgu.Util。這些dll可以在Emgu的安裝目錄下面找到,在我的機器上該路徑是:C:\Emgu\emgucv-windows-x86 2.3.0.1416\bin\。
因為Emgu是對C++類庫的一個.Net包裝,所以需要在dll所在的目錄放一些額外的非托管的dll,使得Emgu能夠找到這些dll進行處理。Emgu在應用程序的執行目錄查找這些dll。如果在debug模式下面,則在bin/Debug目錄下面查找。在release模式下,則在bin/Release目錄下面。共有11個非托管的C++ dll需要放置在相應目錄下面,他們是opencv_calib3d231.dll, opencv_conrib231.dll, opencv_core231.dll,opencv_features2d231.dll, opencv_ffmpeg.dll, opencv_highgui231.dll, opencv_imgproc231.dll,opencv_legacy231.dll, opencv_ml231.dll, opencv_objectdetect231.dll, and opencv_video231.dll。這些dll可以在Emgu的安裝目錄下面找到。為了方便,可以拷貝所有以opencv_開頭的dll。
就像之前文章中所討論的,通過其他的工具來進行Kinect開發可能會使得代碼變得有些混亂。但是有時候,通過添加OpenCV和Emgu的圖像處理功能,能夠開發出一些比較有意思的應用程序。例如,我們能夠實現一個真正的運動識別解決方案。
在我們的擴展方法庫中,我們需要一些額外的擴展幫助方法。上一篇文章討論過,每一種類庫都有其自己能夠理解的核心圖像類型。在Emgu中,這個核心的圖像類型是泛型的Image<TColor,TDepth>類型,它實現了Emgu.CV.IImage接口。下面的代碼展現了一些我們熟悉的影像數據格式和Emgu特定的影像格式之間轉換的擴展方法。新建一個名為EmguExtensions.cs的靜態類,並將其命名空間改為ImageManipulationMethods,和我們之前ImageExtensions類的命名空間相同。我們可以將所有的的擴展方法放到同一個命名空間中。這個類負責三種不同影像數據類型之間的轉換:從Microsoft.Kinect.ColorFrameImage到Emgu.CV.Image<TColor,TDepth>,從System.Drawing.Bitmap到Emgu.CV.Image<TColor,TDepth>以及Emgu.CV.Image<TColor,TDepth>到System.Windows.Media.Imaging.BitmapSource之間的轉換。
namespace ImageManipulationExtensionMethods
{
public static class EmguImageExtensions
{
public static Image<TColor, TDepth> ToOpenCVImage<TColor, TDepth>(this ColorImageFrame image)
where TColor : struct, IColor
where TDepth : new()
{
var bitmap = image.ToBitmap();
return new Image<TColor, TDepth>(bitmap);
}
public static Image<TColor, TDepth> ToOpenCVImage<TColor, TDepth>(this Bitmap bitmap)
where TColor : struct, IColor
where TDepth : new()
{
return new Image<TColor, TDepth>(bitmap);
}
public static System.Windows.Media.Imaging.BitmapSource ToBitmapSource(this IImage image)
{
var source = image.Bitmap.ToBitmapSource();
return source;
}
}
}
使用Emgu類庫來實現運動識別,我們將用到在之前文章中講到的“拉數據”(polling)模型而不是基於事件的機制來獲取數據。這是因為圖像處理非常消耗系統計算和內存資源,我們希望能夠調節處理的頻率,而這只能通過“拉數據”這種模式來實現。需要指出的是本例子只是演示如何進行運動識別,所以注重的是代碼的可讀性,而不是性能,大家看了理解了之後可以對其進行改進。
因為彩色影像數據流用來更新Image控件數據源,我們使用深度影像數據流來進行運動識別。需要指出的是,我們所有用於運動追蹤的數據都是通過深度影像數據流提供的。如前面文章討論,CompositionTarget.Rendering事件通常是用來進行從彩色影像數據流中“拉”數據。但是對於深度影像數據流,我們將會創建一個BackgroundWorker對象來對深度影像數據流進行處理。如下代碼所示,BackgroundWorker對象將會調用Pulse方法來“拉”取深度影像數據,並執行一些消耗計算資源的處理。當BackgroundWorker完成了一個循環,接著從深度影像數據流中“拉”取下一幅影像繼續處理。代碼中聲明了兩個名為MotionHistory和IBGFGDetector的Emgu成員變量。這兩個變量一起使用,通過相互比較來不斷更新基准影像來探測運動。
KinectSensor _kinectSensor;
private MotionHistory _motionHistory;
private IBGFGDetector<Bgr> _forgroundDetector;
bool _isTracking = false;
public MainWindow()
{
InitializeComponent();
this.Unloaded += delegate
{
_kinectSensor.ColorStream.Disable();
};
this.Loaded += delegate
{
_motionHistory = new MotionHistory(
1.0, //in seconds, the duration of motion history you wants to keep
0.05, //in seconds, parameter for cvCalcMotionGradient
0.5); //in seconds, parameter for cvCalcMotionGradient
_kinectSensor = KinectSensor.KinectSensors[0];
_kinectSensor.ColorStream.Enable();
_kinectSensor.Start();
BackgroundWorker bw = new BackgroundWorker();
bw.DoWork += (a, b) => Pulse();
bw.RunWorkerCompleted += (c, d) => bw.RunWorkerAsync();
bw.RunWorkerAsync();
};
}
下面的代碼是執行圖象處理來進行運動識別的關鍵部分。代碼在Emgu的示例代碼的基礎上進行了一些修改。Pluse方法中的第一個任務是將彩色影像數據流產生的ColorImageFrame對象轉換到Emgu中能處理的圖象數據類型。_forgroundDetector對象被用來更新_motionHistory對象,他是持續更新的基准影像的容器。_forgroundDetector還被用來與基准影像進行比較,以判斷是否發生變化。當從當前彩色影像數據流中獲取到的影像和基准影像有不同時,創建一個影像來反映這兩張圖片之間的差異。然後將這張影像轉換為一系列更小的圖片,然後對運動識別進行分解。我們遍歷這一些列運動的圖像來看他們是否超過我們設定的運動識別的阈值。如果這些運動很明顯,我們就在界面上顯示視頻影像,否則什麼都不顯示。
private void Pulse()
{
using (ColorImageFrame imageFrame = _kinectSensor.ColorStream.OpenNextFrame(200))
{
if (imageFrame == null)
return;
using (Image<Bgr, byte> image = imageFrame.ToOpenCVImage<Bgr, byte>())
using (MemStorage storage = new MemStorage()) //create storage for motion components
{
if (_forgroundDetector == null)
{
_forgroundDetector = new BGStatModel<Bgr>(image
, Emgu.CV.CvEnum.BG_STAT_TYPE.GAUSSIAN_BG_MODEL);
}
_forgroundDetector.Update(image);
//update the motion history
_motionHistory.Update(_forgroundDetector.ForgroundMask);
//get a copy of the motion mask and enhance its color
double[] minValues, maxValues;
System.Drawing.Point[] minLoc, maxLoc;
_motionHistory.Mask.MinMax(out minValues, out maxValues
, out minLoc, out maxLoc);
Image<Gray, Byte> motionMask = _motionHistory.Mask
.Mul(255.0 / maxValues[0]);
//create the motion image
Image<Bgr, Byte> motionImage = new Image<Bgr, byte>(motionMask.Size);
motionImage[0] = motionMask;
//Threshold to define a motion area
//reduce the value to detect smaller motion
double minArea = 100;
storage.Clear(); //clear the storage
Seq<MCvConnectedComp> motionComponents = _motionHistory.GetMotionComponents(storage);
bool isMotionDetected = false;
//iterate through each of the motion component
for (int c = 0; c < motionComponents.Count(); c++)
{
MCvConnectedComp comp = motionComponents[c];
//reject the components that have small area;
if (comp.area < minArea) continue;
OnDetection();
isMotionDetected = true;
break;
}
if (isMotionDetected == false)
{
OnDetectionStopped();
this.Dispatcher.Invoke(new Action(() => rgbImage.Source = null));
return;
}
this.Dispatcher.Invoke(
new Action(() => rgbImage.Source = imageFrame.ToBitmapSource())
);
}
}
}
private void OnDetection()
{
if (!_isTracking)
_isTracking = true;
}
private void OnDetectionStopped()
{
_isTracking = false;
}
2.5 保存視頻影像
相比直接將影像顯示出來,如果能將錄制到的影像保存到硬盤上就好了。但是,影像錄制,是需要一定的技巧,在網上可以看到很多例子演示如何將Kinect獲取到的影像以圖片的形式保存到本地,前面的博文也介紹了這一點,但是你很少看到如何演示將一個完整的視頻影像保存到本地硬盤上。幸運的是Emgu類庫提供了一個VideoWriter類型來幫助我們實現這一功能。
下面的方法展示了Record和StopRecording方法如何將Kinect彩色影像攝像頭產生的數據流保存到avi文件中。我們在D盤創建了一個vids文件夾,要寫入avi文件之前需要保證該文件夾存在。當錄制開始時,我們使用當前時間作為文件名創建一個文件,同時我們創建一個list對象來保存從彩色影像數據流中獲取到的一幀幀影像。當停止錄制時,將list對象中的一些列Emgu影像最為參數傳入到VideoWriter對象來將這些影像轉為為avi格式並保存到硬盤上。這部分代碼沒有對avi編碼,所以產生的avi文件非常大。我們可以對avi文件進行編碼壓縮然後保存到硬盤上,但是這樣會加大計算機的運算開銷。
bool _isRecording = false;
string _baseDirectory = @"d:\vids\";
string _fileName;
List<Image<Rgb, Byte>> _videoArray = new List<Image<Rgb, Byte>>();
void Record(ColorImageFrame image)
{
if (!_isRecording)
{
_fileName = string.Format("{0}{1}{2}", _baseDirectory, DateTime.Now.ToString("MMddyyyyHmmss"), ".avi");
_isRecording = true;
}
_videoArray.Add(image.ToOpenCVImage<Rgb, Byte>());
}
void StopRecording()
{
if (!_isRecording)
return;
CvInvoke.CV_FOURCC('P', 'I', 'M', '1'); //= MPEG-1 codec
CvInvoke.CV_FOURCC('M', 'J', 'P', 'G'); //= motion-jpeg codec (does not work well)
CvInvoke.CV_FOURCC('M', 'P', '4', '2');//= MPEG-4.2 codec
CvInvoke.CV_FOURCC('D', 'I', 'V', '3'); //= MPEG-4.3 codec
CvInvoke.CV_FOURCC('D', 'I', 'V', 'X'); //= MPEG-4 codec
CvInvoke.CV_FOURCC('U', '2', '6', '3'); //= H263 codec
CvInvoke.CV_FOURCC('I', '2', '6', '3'); //= H263I codec
CvInvoke.CV_FOURCC('F', 'L', 'V', '1'); //= FLV1 codec
using (VideoWriter vw = new VideoWriter(_fileName, 0, 30, 640, 480, true))
{
for (int i = 0; i < _videoArray.Count(); i++)
vw.WriteFrame<Rgb, Byte>(_videoArray[i]);
}
_fileName = string.Empty;
_videoArray.Clear();
_isRecording = false;
}
本例中,運動識別最後一點代碼是簡單的修改從彩色影像數據流“拉”取數據部分的邏輯。使得不僅將在探測到運動時將影像顯示到UI界面上,同時也調用Record方法。當沒有探測到運動時,UI界面上什麼也不顯示,並調用StopRecording方法。這部分代碼也通過演示如何分析原始數據流,並探測Kinect視野中常用的變化給出了一個原型,這些變化信息可能會提供很有用的信息。
if (isMotionDetected == false)
{
OnDetectionStopped();
this.Dispatcher.Invoke(new Action(() => rgbImage.Source = null));
StopRecording();
return;
}
this.Dispatcher.Invoke(
new Action(() => rgbImage.Source = imageFrame.ToBitmapSource())
);
Record(imageFrame);
3.面部識別
EmguCV庫也能用來進行面部識別(face identify)。實際的面部識別,就是將一張圖像上的人物的臉部識別出來,這是個很復雜的過程,具體過程我們這裡不討論。對一幅影像進行處理來找到包含臉部的那一部分是我們進行面部識別的第一個步驟。
大多數面部識別軟件或多或少都是基於類哈爾特征(Haar-like feature)來進行識別的,他是哈爾小波(Haar wavelets)的一個應用,通過一些列的數學方法來定義一個矩形形狀。2001年,Paul Viola和Michael Jones發表了Viola-Jones物體識別方法的框架,該框架基於識別Haar-like特征進行的。該方法和其他面部識別算法相比,所需要的運算量較小。所以這部分方法整合進了OpenCV庫。
OpenCV和EmguCV中的面部識別是建立在一系列定義好了的識別規則基礎之上的,規則以XML文件的形式存儲,最初格式是由Rainer Lienhart定義的。在Emgu示例代碼中該文件名為haarcascade_frontalface_default.xml。當然還有一系列的可以識別人物眼睛的規則在這些示例文件中,本例子中沒有用到。
要使用Kinect SDK來構造一個簡單的面部識別程序,首先創建一個名為KinectFaceFinder的WPF應用程序,然後引用Microsoft.Kinect, System.Drawing, Emgu.CV, Emgu.CV.UI, 和Emgu.Util. 並將所有以opencv_*開頭的dll拷貝到程序編譯的目錄下面。最後將之前寫好的兩個擴展方法類庫ImageExtension.cs和EmguImageExtensions.cs拷貝到項目中。項目的前端代碼和之前的一樣。只是在root根節點下面添加了一個名為rgbImage的Image控件。
<Window x:Class="FaceFinder.MainWindow"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
Title="MainWindow" Height="350" Width="525" >
<Grid >
<Image HorizontalAlignment="Stretch" Name="rgbImage" VerticalAlignment="Stretch" />
</Grid>
</Window>
後台代碼中,首先在MainWindow的構造函數中實例化KinectSensor對象然後配置彩色影像數據。因為我們使用EmguCV庫來進行影像處理,所以我們可以直接使用RGB影像而不是深度影像。如下代碼所示,代碼中使用了BackgroundWork對象來從彩色影像數據流中拉取數據。每一次處理完了之後,拉取下一幅,然後繼續處理。
KinectSensor _kinectSensor;
public MainWindow()
{
InitializeComponent();
this.Unloaded += delegate
{
_kinectSensor.ColorStream.Disable();
};
this.Loaded += delegate
{
_kinectSensor = KinectSensor.KinectSensors[0];
_kinectSensor.ColorStream.Enable();
_kinectSensor.Start();
BackgroundWorker bw = new BackgroundWorker();
bw.RunWorkerCompleted += (a, b) => bw.RunWorkerAsync();
bw.DoWork += delegate { Pulse(); };
bw.RunWorkerAsync();
};
}
上面代碼中,Pluse方法處理BackgroundWork的DoWork事件,這個方法是這個例子的主要方法。下面的代碼簡單的對Emgu提供的示例代碼進行了一點修改。我們基於提供的臉部識別規則文件實例化了一個新的HaarCascade類。然後我們從彩色影像數據流獲取了一幅影像,然後將他轉換為了Emgu能夠處理的格式。然後對圖像進行灰度拉伸然後提高對比度來使得臉部識別更加容易。Haar識別准則應用到圖像上去來產生一些列的結構來指示哪個地方是識別出來的臉部。處理完的影像然後轉換為BitmapSource類型,最後後復制給Image控件。因為WPF線程的工作方式,我們使用Dispatcher對象來在正確的線程中給Image控件賦值。
String faceFileName = "haarcascade_frontalface_default.xml";
public void Pulse()
{
using (HaarCascade face = new HaarCascade(faceFileName))
{
var frame = _kinectSensor.ColorStream.OpenNextFrame(100);
var image = frame.ToOpenCVImage<Rgb, Byte>();
using (Image<Gray, Byte> gray = image.Convert<Gray, Byte>()) //Convert it to Grayscale
{
//normalizes brightness and increases contrast of the image
gray._EqualizeHist();
//Detect the faces from the gray scale image and store the locations as rectangle
//The first dimensional is the channel
//The second dimension is the index of the rectangle in the specific channel
MCvAvgComp[] facesDetected = face.Detect(
gray,
1.1,
10,
Emgu.CV.CvEnum.HAAR_DETECTION_TYPE.DO_CANNY_PRUNING,
new System.Drawing.Size(20, 20));
Image<Rgb, Byte> laughingMan = new Image<Rgb, byte>("laughing_man.jpg");
foreach (MCvAvgComp f in facesDetected)
{
image.Draw(f.rect, new Rgb(System.Drawing.Color.Blue), 2);
}
Dispatcher.BeginInvoke(new Action(() => { rgbImage.Source = image.ToBitmapSource(); }));
}
}
}
運行程序可以看到,藍色方框內就是識別出來的人的臉部,這種識別精度比簡單的使用骨骼追蹤來識別出人的頭部,然後識別出臉部要精確的多。
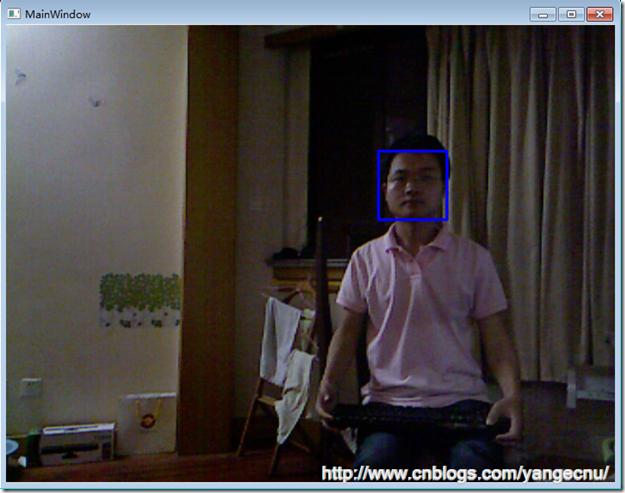
既然facesDetected包含了識別出來的臉部的位置信息,我們能夠使用臉部識別算法來建立一個現實增強應用。我們可以將一個圖片放到臉部位置,而不是用矩形框來顯示。下面的代碼顯示了我們如何使用一個圖片替代藍色的矩形框。
Image<Rgb, Byte> laughingMan = new Image<Rgb, byte>("laughing_man.jpg");
foreach (MCvAvgComp f in facesDetected)
{
//image.Draw(f.rect, new Rgb(System.Drawing.Color.Blue), 2);
var rect = new System.Drawing.Rectangle(f.rect.X - f.rect.Width / 2
, f.rect.Y - f.rect.Height / 2
, f.rect.Width * 2
, f.rect.Height * 2);
var newImage = laughingMan.Resize(rect.Width, rect.Height, Emgu.CV.CvEnum.INTER.CV_INTER_LINEAR);
for (int i = 0; i < (rect.Height); i++)
{
for (int j = 0; j < (rect.Width); j++)
{
if (newImage[i, j].Blue != 0 && newImage[i, j].Red != 0 && newImage[i, j].Green != 0)
image[i + rect.Y, j + rect.X] = newImage[i, j];
}
}
}
運行程序,代碼效果如下。這個形象來自動漫《攻克機動隊》(Ghost in the Shell: Stand Alone Complex),講述的是在一個在未來全面監控下的社會,一個黑客,每當他的臉被監控的攝像頭捕獲到的時候,就在上面疊加一個笑臉。因為臉部識別的算法很好,所以這張笑臉圖像,和動漫中的形象很像,他會隨著臉部的大小和運動而變化。
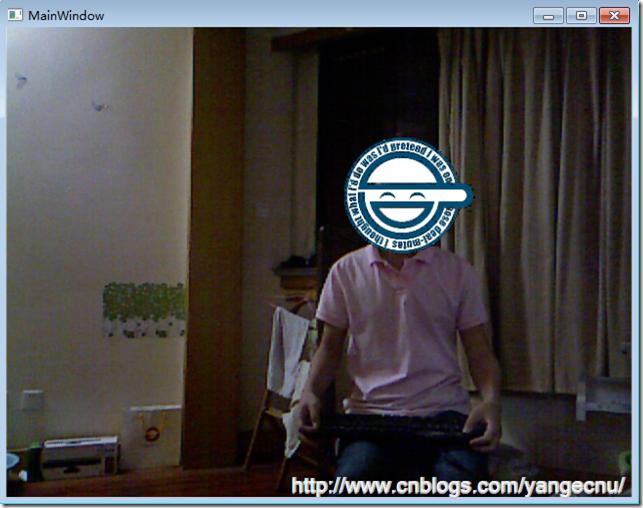
4.全息圖
Kinect的另一個有趣的應用是偽全息圖(pseudo-hologram)。3D圖像可以根據人物在Kinect前面的各種位置進行傾斜和移動。如果方法夠好,可以營造出3D控件中3D圖像的效果,這樣可以用來進行三維展示。因為WPF具有3D矢量繪圖的功能。所以這一點使用WPF和Kinect比較容易實現。下圖顯示了一個可以根據觀察者位置進行旋轉和縮放的3D立方體。但是,只有一個觀察者時才能運行。

這個效果可以追溯到Johnny Chung Lee在2008 年TED演講中對Wii Remote的破解演示。後來Johnny Lee在Kinect項目組工作了一段時間,並發起了AdaFruit競賽,來為破解Kinect編寫驅動。在Lee的實現中,Wii Remote的紅外傳感器放置在一對眼鏡上。能夠追蹤戴上該眼鏡的人的運動。界面上會顯示一個復雜的3D圖像,該圖像可以根據這副眼鏡的運動創建全息圖的效果。
使用Kinect SDK實現這一效果非常簡單。Kinect已經在骨骼數據中提供了坐標點的以米為單位的X,Y和Z的值。比較困難的部分是,如何使用XAML創建一個3D矢量模型。在本例子中,我使用Blender這個工具,他是一個開源的3D模型建造工具,可以在www.blender.org網站上下載到。但是,要將3D網格曲面導出為XAML,需要為Blender安裝一個插件。我使用的Blender版本是2.6,本身有這麼一個功能,雖然有些限制。Dan Lehenbauer在CodePlex上也有針對Blender開發的導出Xmal的插件,但是只能在老版本的Blender上使用。
WPF中3D矢量圖像的核心概念是Viewport3D對象。Viewport3D對象可以被認為是一個3D空間,在這個空間內,我們可以放置對象,光源和照相機。為了演示一個3D效果,我們創建一個新的名為KinectHologram項目,並添加對Microsoft.Kinect.dll的引用。在MainWindow的UI界面中,在root Grid對象下面創建一個新的ViewPort3D元素。下面的代碼顯示了一個立方體的代碼。代碼中唯一和Kinect進行交互的是Viewport3D照相機對象。因此很有必要對照相機對象進行命名。
<Viewport3D>
<Viewport3D.Camera>
<PerspectiveCamera x:Name="camera" Position="-40,160,100" LookDirection="40,-160,-100"
UpDirection="0,1,0" />
</Viewport3D.Camera>
<ModelVisual3D x:Name="mainBox">
<ModelVisual3D.Transform>
<Transform3DGroup>
<TranslateTransform3D>
<TranslateTransform3D.OffsetY>10</TranslateTransform3D.OffsetY>
</TranslateTransform3D>
<ScaleTransform3D>
<ScaleTransform3D.ScaleZ>3</ScaleTransform3D.ScaleZ>
</ScaleTransform3D>
</Transform3DGroup>
</ModelVisual3D.Transform>
<ModelVisual3D.Content>
<Model3DGroup>
<DirectionalLight Color="White" Direction="-1,-1,-3" />
<GeometryModel3D >
<GeometryModel3D.Geometry>
<MeshGeometry3D
Positions="1.000000,1.000000,-1.000000 1.000000,-1.000000,-1.000000 -1.000000,-1.000000,-1.000000 -1.000000,1.000000,-1.000000 1.000000,0.999999,1.000000 -1.000000,1.000000,1.000000 -1.000000,-1.000000,1.000000 0.999999,-1.000001,1.000000 1.000000,1.000000,-1.000000 1.000000,0.999999,1.000000 0.999999,-1.000001,1.000000 1.000000,-1.000000,-1.000000 1.000000,-1.000000,-1.000000 0.999999,-1.000001,1.000000 -1.000000,-1.000000,1.000000 -1.000000,-1.000000,-1.000000 -1.000000,-1.000000,-1.000000 -1.000000,-1.000000,1.000000 -1.000000,1.000000,1.000000 -1.000000,1.000000,-1.000000 1.000000,0.999999,1.000000 1.000000,1.000000,-1.000000 -1.000000,1.000000,-1.000000 -1.000000,1.000000,1.000000"
TriangleIndices="0,1,3 1,2,3 4,5,7 5,6,7 8,9,11 9,10,11 12,13,15 13,14,15 16,17,19 17,18,19 20,21,23 21,22,23"
Normals="0.000000,0.000000,-1.000000 0.000000,0.000000,-1.000000 0.000000,0.000000,-1.000000 0.000000,0.000000,-1.000000 0.000000,-0.000000,1.000000 0.000000,-0.000000,1.000000 0.000000,-0.000000,1.000000 0.000000,-0.000000,1.000000 1.000000,-0.000000,0.000000 1.000000,-0.000000,0.000000 1.000000,-0.000000,0.000000 1.000000,-0.000000,0.000000 -0.000000,-1.000000,-0.000000 -0.000000,-1.000000,-0.000000 -0.000000,-1.000000,-0.000000 -0.000000,-1.000000,-0.000000 -1.000000,0.000000,-0.000000 -1.000000,0.000000,-0.000000 -1.000000,0.000000,-0.000000 -1.000000,0.000000,-0.000000 0.000000,1.000000,0.000000 0.000000,1.000000,0.000000 0.000000,1.000000,0.000000 0.000000,1.000000,0.000000"/>
</GeometryModel3D.Geometry>
<GeometryModel3D.Material>
<DiffuseMaterial Brush="blue"/>
</GeometryModel3D.Material>
</GeometryModel3D>
<Model3DGroup.Transform>
<Transform3DGroup>
<Transform3DGroup.Children>
<TranslateTransform3D OffsetX="0" OffsetY="0" OffsetZ="0.0935395359992981"/>
<ScaleTransform3D ScaleX="12.5608325004577637" ScaleY="12.5608322620391846" ScaleZ="12.5608325004577637"/>
</Transform3DGroup.Children>
</Transform3DGroup>
</Model3DGroup.Transform>
</Model3DGroup>
</ModelVisual3D.Content>
</ModelVisual3D>
</Viewport3D>
上面的代碼中,照相機對象(camera)有一個以X,Y,Z表示的位置屬性。X從左至右增加。Y從下往上增加。Z隨著屏幕所在平面,向靠近用戶的方向增加。該對象還有一個觀看方向,該方向和位置相反。在這裡我們告訴照相機往後面的0,0,0坐標點看。最後,UpDirection表示照相機的朝向,在本例中,照相機向上朝向Y軸方向。
查看本欄目
立方體使用一系列8個位置的值來繪制,每一個點都是三維坐標點。然後通過這些點繪制三角形切片來形成立方體的表面。在這之上我們添加一個Material對象然後將其顏色改為藍色。然後給一個縮放變形使這個立方體看起來大一點。最後我們給這個立方體一些定向光源來產生一些3D的效果。
在後台代碼中,我們只需要配置KienctSensor對象來支持骨骼追蹤,如下代碼所示。彩色影像和深度值影像在該項目中不需要用到。
KinectSensor _kinectSensor;
public MainWindow()
{
InitializeComponent();
this.Unloaded += delegate
{
_kinectSensor.DepthStream.Disable();
_kinectSensor.SkeletonStream.Disable();
};
this.Loaded += delegate
{
_kinectSensor = KinectSensor.KinectSensors[0];
_kinectSensor.SkeletonFrameReady += SkeletonFrameReady;
_kinectSensor.DepthFrameReady += DepthFrameReady;
_kinectSensor.SkeletonStream.Enable();
_kinectSensor.DepthStream.Enable();
_kinectSensor.Start();
};
}
為了能夠產生全息圖的效果,我們將會圍繞立方體來移動照相機的位置,而不是對立方體本身進行旋轉。首先我們需要確定Kinect中是否有用戶正在處於追蹤狀態。如果有一個,我們就忽略其他的。我們獲取追蹤到的骨骼數據並提取X,Y,Z坐標信息。因為Kinect提供的位置信息的單位是米,而我們的3D立方體不是的,所以需要將這些位置點信息進行一定的轉換才能夠產生3D效果。基於這些位置坐標,我們大概以正在追中的骨骼為中心來移動照相機。我們也用這些坐標,並將這些坐標翻轉,使得照相機能夠連續的指向0,0,0這個原點。
void SkeletonFrameReady(object sender, SkeletonFrameReadyEventArgs e)
{
float x=0, y=0, z = 0;
//get angle of skeleton
using (var frame = e.OpenSkeletonFrame())
{
if (frame == null || frame.SkeletonArrayLength == 0)
return;
var skeletons = new Skeleton[frame.SkeletonArrayLength];
frame.CopySkeletonDataTo(skeletons);
for (int s = 0; s < skeletons.Length; s++)
{
if (skeletons[s].TrackingState == SkeletonTrackingState.Tracked)
{
border.BorderBrush = new SolidColorBrush(Colors.Red);
var skeleton = skeletons[s];
x = skeleton.Position.X * 60;
z = skeleton.Position.Z * 120;
y = skeleton.Position.Y;
break;
}
else
{
border.BorderBrush = new SolidColorBrush(Colors.Black);
}
}
}
if (Math.Abs(x) > 0)
{
camera.Position = new System.Windows.Media.Media3D.Point3D(x, y , z);
camera.LookDirection = new System.Windows.Media.Media3D.Vector3D(-x, -y , -z);
}
}
有意思的是,這樣產生全息圖影像的效果比許多復雜的3D對象產生的全息圖要好。3D立方體可以很容易的轉換為矩形,如下圖所示,只需要簡單的將立方體在Z方向上進行拉伸即可。這個矩形朝向游戲者拉伸。我們可以簡單的將立方體的UI這部分代碼復制,然後創建一個新的modelVisual3D對象來產生新的矩形。使用變換來將這些矩形放X,Y軸上的不同位置,並給予不同的顏色。因為照相機是後台代碼唯一需要關注的對象,在前台添加一個矩形對象及變換並不會影響代碼的運行。
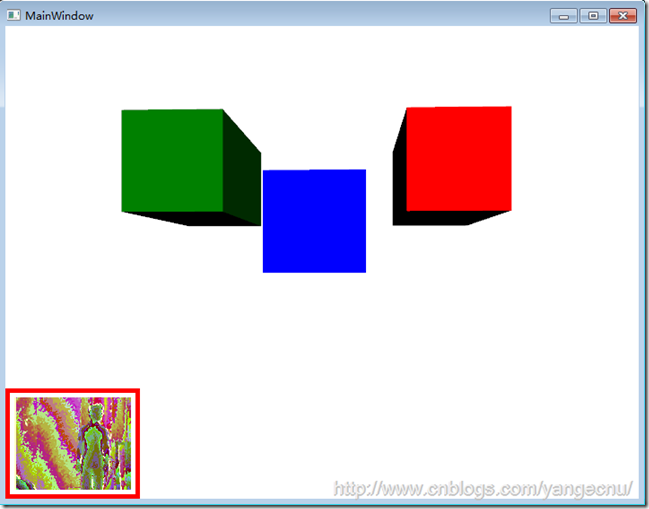
5.其他值得關注的類庫和項目
與Kinect相關的一些類庫和工具在以後的幾年,估計會更加多和Kienct SDK一起工作。當然,最重要的使人著迷的類庫及工具有FAAST,Utility3D以及Microsoft Robotics Developer Studio。
FAAST(Flexible Action and Articulated Skeleton Toolkit)是一個中間件類庫用來連接Kinect的手勢交互界面和傳統的人際交互界面。這個類庫由南加利福利亞大學的創新技術研究院編寫和維護。最初FAAST是使用OpenNI結合Kinect來編寫的一個手勢識別類庫。這個類庫真正優秀的地方在於它能夠將大多數內建手勢映射到其他API中,甚至能夠將手勢映射到鍵盤點擊中來。這使得一些Kinect技術愛好者(hacker)能夠使用這一工具來使用Kinect玩一些視頻游戲,包括一些例如《使命召喚》(Call of Duty)的第一人稱射擊游戲,以及一些像《第二人生》(Second Life)和《魔獸世界》(World of Warcraft)這樣的網絡游戲。目前FAAST只有針對OpenNI版本,但是據最新的消息,FAAST現在正在針對KienctSDK進行開發,可以在其官網http://projects.ict.usc.edu/mxr/faast了解更多的相關信息。
Utility3D是一個工具,能夠使得傳統開發3D游戲的復雜工作變得相對簡單,他有免費版和專業版之分。使用Uitltiy3D編寫的游戲能夠輕松的跨多種平台,包括web,windows,ios, iPhone,ipad,Android,Xbox,Playstation以及Wii。它也支持第三方插件,包括一些為Kinect開發的插件,使得開發者能夠使用Kinect作為傳感器來作為Windows游戲的輸入設備。可以在Unity3D的官網查看更多信息http://unity3d.com。
Microsoft Robotics Developer Studio是微軟針對機器人的開發平台,其最新發布的RDS4.0版本也集成了Kinect傳感器。除了能夠訪問Kinect提供的功能,Kinect也支持一系列特定的基於Kinect的機器人平台,他們可以利用Kinect傳感器進行障礙物避讓。更多的有關Microsoft Robotics Developer Studio的信息可以訪問http://www.microsoft.com/robotics。
6.結語
本文接上文,介紹了Kinect進階開發中需要了解一些類庫和項目。在上文的基礎上,本文接著介紹了近距離探測中如何探測運動,如何獲取並保存產生的影像數據;然後將會介紹如何進行臉部識別,以及介紹全息圖(Holograme)的一些知識,最後介紹了一些值得關注的類庫和項目。本文中的幾個例子可能對計算機性能有點要求,因為從Kinect獲取數據以及實時圖像處理是一個比較耗費資源的工作,我是09年的買的筆記本,運行上面的例子基本比較卡,大家可以試著在好一點的機器上運行,就像之前所講的,本文例子著重的是功能和方法的展示,所以注重代碼的可讀性,最求性能的同學可以試著優化一下。
作者: yangecnu(yangecnu's Blog on 博客園)
出處:http://www.cnblogs.com/yangecnu/