相信一些學習python的朋友找不到一些python的的朋友找不到相對應的python面經,所以博主就推薦大家可以去牛客上面看看哦,各種大廠面經和習題哦!
地址:面經地址
可變類型包括dict,list都不可以作為字典的key,而原子類型以及tuple則可以。
參考:
python迭代器_和_生成器
生成器是一種特殊的迭代器,生成器自動實現了“迭代器協議”(即__iter__和next方法),不需要再手動實現兩方法。
生成器在迭代的過程中可以改變當前迭代值,而修改普通迭代器的當前迭代值往往會發生異常,影響程序的執行。
吐血總結!50道Python面試題集錦(附答案)
GC機制也就是垃圾回收機制,在每個高級語言中都有自己的垃圾回收機制,在python中通過應用技術,標記清除和分代回收三種方案來實現
引用計數指: 每添加一個新的引用對象,對象引用就加1,每減少一個,對象應用就減1,一旦引用數為0時,改內存就被釋放,這一點是因為python底層采用的是引用傳遞有關,而不是像go語言中采取的值傳遞
標記清除:首先是標記對象,然後後一次性清除對象
分代回收:垃圾回收器會將不同的對象劃分成不同的區域,然後每個區域處理間隔不同,通常根據對象的創建時間來定,對新對象會更加頻繁的處理,對於經過幾個時間周期之後仍然存在的對象會將該對象移入下一代中,處理間隔時間變長
引用計數為主,分代回收為輔。
引用計數機制的優點:
1、簡單
2、實時性:一旦沒有引用,內存就直接釋放了,不用像其他機制得等到特定時機。實時性還帶來一個好處:處理回收內存的時間分攤到了平時。
引用計數機制的缺點:
1、維護引用計數消耗資源
2、循環引用
python中一切皆為對象,核心是一個結構體 PyObject其中維護了一個 int 型變量 ob_refcnt。
當對象有新的引用時候ob_refcnt就會增加1,同理刪除就會減少。其中還有小整數對象池,大整數對象池等概念。此處就不在贅述。
引用計數為0時,該對象生命就結束了。
但此時會有一個十分嚴重的問題就是循環引用無法回收
什麼是循環引用呢,就是 如果⼀個數據結構引⽤了它⾃身, 即如果這個數據結構是⼀個循環數據結構, 那麼某些引⽤計數值是肯定⽆法變成零的。比如循環鏈表,此處舉一個簡單的例子
class ClassA():
def __init__(self):
print('Object born,id:%s'%str(hex(id(self))))
def f2():
while True:
c1=ClassA()
c2=ClassA()
c1.t=c2
c2.t=c1
del c1
del c2
f2()
在執行del c1和c2時候,由於c1有指向c2的引用,c2有指向c1的引用。del之後兩者引用數只會減少到1,並不會被回收。
分代回收是一種以空間換時間的操作方式,Python將內存根據對象的存活時間劃分為不同的集合,每個集合稱為一個代,Python將內存分為了3“代”,分別為年輕代(第0代)、中年代(第1代)、老年代(第2代),他們對應的是3個鏈表,它們的垃圾收集頻率隨著對象存活時間的增大而減小。
新創建的對象都會分配在年輕代,年輕代鏈表的總數達到上限時,Python垃圾收集機制就會被觸發,把那些可以被回收的對象回收掉,而那些不會回收的對象就會被移到中年代去,依此類推,老年代中的對象是存活時間最久的對象,甚至是存活於整個系統的生命周期內。
同時,分代回收是建立在標記清除技術基礎之上。分代回收同樣作為Python的輔助垃圾收集技術處理那些容器對象
有三種情況會觸發垃圾回收:
標記清除(Mark—Sweep)』算法是一種基於追蹤回收(tracing GC)技術實現的垃圾回收算法。它分為兩個階段:第一階段是標記階段,GC會把所有的『活動對象』打上標記,第二階段是把那些沒有標記的對象『非活動對象』進行回收。那麼GC又是如何判斷哪些是活動對象哪些是非活動對象的呢?
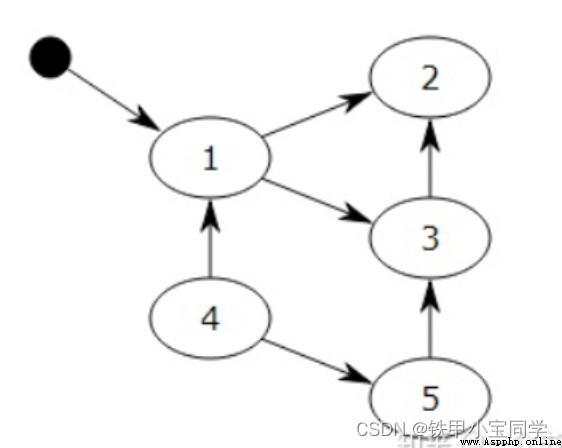
對象之間通過引用(指針)連在一起,構成一個有向圖,對象構成這個有向圖的節點,而引用關系構成這個有向圖的邊。從根對象(root object)出發,沿著有向邊遍歷對象,可達的(reachable)對象標記為活動對象,不可達的對象就是要被清除的非活動對象。根對象就是全局變量、調用棧、寄存器。 mark-sweepg 在上圖中,我們把小黑圈視為全局變量,也就是把它作為root object,從小黑圈出發,對象1可直達,那麼它將被標記,對象2、3可間接到達也會被標記,而4和5不可達,那麼1、2、3就是活動對象,4和5是非活動對象會被GC回收。
參考文章:python垃圾回收機制_Python 中的垃圾回收機制
在內置數據類型的基礎上,提供了幾個額外的數據類型:
nametuple 具名元組
queue 隊列
deque 雙端隊列
OrderdDict 有序字典
defaultdict 默認值字典
Counter 計數
裝飾器是由 名稱空間,函數對象,閉包函數組合使用的一種方法
其核心是在不改變被裝飾對象內部代碼的前提下,給被裝飾對象添加新的功能,當然可以通過面向對象的繼承特性來實現同樣的效果
裝飾器可以分為無參裝飾器和有參裝飾器,多個裝飾器的加載順序是從下而上,執行順序是從上而下
生成器說白了就是一個函數對象,只不過在函數裡面采用了yield關鍵字,在定義時是函數,被調用時就是一個生成器
生成器內置__iter__和__next__方法,所以生成器本身就是一個迭代器
生成器的優點: 能夠返回多次值,可以掛起來保存函數的運行狀態,能夠減少內存的使用,在scrapy框架中,大量應用到了生成器,也可用用到大數據的獲取或redis緩存時使用
迭代器特點是不依賴索引取值,有__iter__和__next__方法稱為迭代器對象,有__iter__方法稱為可迭代對象,可迭代對象,調用__iter__方法生成迭代器對象。for循環的本質就是想將可迭代對象生成迭代器對象,然後循環執行__next__方法取值,加上異常捕獲出來,取不到值時結束取值
三元表達式,是python提供的一種簡化代碼的解決方案, 通過一行代碼,使用if-else判斷獲取不同的值
列表生成式,就相當於把for循環寫在列表中,一行代碼完成一個功能,可以結合if-else使用
生成器對象,就是把列表生成式的[]換成()即可,不同的是,列表生成式返回的是一個列表,生成器表達式生成的是一個對象,相比之下,生成器表達式能夠更節省內存
匿名函數: 需要將一個函數對象作為參數傳遞時,並且只有在一個地方會使用這個函數時,可以直接用lambda定義,通常與python的內置函數配合使用,如max,map,min等
在調用一個函數的內部又調用自己,所以遞歸的本質就是一個循環,是用函數遞歸的大前提是一定要有一個結束條件,否則,會形成一個死循環。python解釋器限制的遞歸深度大約為1000
遞歸分為遞推和回溯兩個階段,遞推,一層一層往下推,回溯一層一層向上返回
面向對象編程的核心是對象兩字,對象就是一個用來盛放數據與功能的容器,其優點是,擴展性強,但是也有缺點,就是提高了編程的復雜度
在程序中,是先定義類,後產生對象。這裡的對象就是一個個容器,類也可以看成一個容器,用來存放同類對象共有的數據和方法
面向對象的三大特性: 封裝,繼承,多態
封裝: 就是將多個屬性和方法封裝都一個抽象的類中,所有類的對象都可以調用。
針對封裝的方法和屬性,可以通過__將其隱藏起來,設置成私有屬性,但這僅僅是一種變形操作,在外部可以通過_類名__屬性名的方法調用,隱藏是對外不對內。
繼承: 能夠實現代碼的重用、繼承父類、重用父類的屬性和方法、減少代碼的冗余。
繼承是子類和父類之間的關系,需要先抽象再繼承
抽象: 最主要的作用是劃分類別,總結類與類,對象與對象之間的相似之處,類與類之間的相似之處就可以拉出來寫一個類用來繼承
python2中,有經典類和新式類之分,沒有顯示繼承object的類及其子類都是經典類,顯示繼承object的類就是新式類
python3中,只有新式類,默認繼承object類
差別:
經典類的繼承查找是深度優先
新式類的繼承查找是廣度優先
多態: 指的是一類事物有多種形態,多態性值得是可以在不用考慮對象具體類型的情況下而直接使用 多態性的本質在於不同的類中定有相同的方法名,這樣就可以不用同一類而使用同一種方法來使用對象,python中一切皆對象,本身就支持多態性
需要注意的是:
1. 多態指的的方法的多態,屬性沒有多態
2. 多態存在兩個必要的條件: 繼承和方法重寫
可以通過父類中使用abstractmethod方法或raise拋異常的方法來限制子類中必須有某種方法
應用:
drf的源碼中BaseSerializer類應用了這個方法
鴨子類型: 是動態類型的一種風格,不管對象屬於那個,也不管聲明的具體接口是什麼,只要對象實現了相應的方法,函數就可以在對象上執行操作。忽略了對象的真正類型,只關注對象又沒有實現所需的方法。簡單點說,只要你有同樣的方法,就屬於同一個類。我個人感覺,鴨子類型就是多態的進一步擴展,不需要繼承和方法重寫
MRO列表會遵循如下三條准則
1. 子類會優先於父類被檢查
2. 多個父類會根據它們在列表中的順序被檢查
3. 如果對下一個類存在兩個合法的選擇,選擇第一個父類
super()獲得父類定義
在子類中,如果想要獲得父類的方法,可以通過super()來做,super()代表父類的定義,而不是父類對象
但凡在類中定義一個函數,默認就是綁定給對象的,應該由對象來調用,會將對象當作第一個參數自動傳入
classmethods:綁定給類的方法,由類來調用,自動將類本身當作第一個參數傳入
staticmethod:非綁定方法,不與類和對象綁定,類和對象都可以調用,普通函數,沒有自動傳值 property:一種特殊屬性、訪問它時會執行一段功能,用來綁定給對象的方法,將函數對象偽裝成數據屬性,然後返回值
應用:django模型類中寫子序列化的方法,跨表操作
abstractmethod: 實現多態性的一種限制,用來限制子類必須實現某種方法,也可以用raise拋異常的方式實現,在drf序列化源碼baseserializer中有應用
python的反射就是通過字符串操作對象相關的屬性,python中一切皆對象,都可以用到反射
反射機制指的是在程序運行狀態中
對任意一個類,都可以知道這個類的所有屬性和方法;對任意一個對象,都能調用他的任意方法和屬性。這種動態獲取程序信息以及動態調用對象的功能稱為反射機制
hasattr 檢查是否含有屬性
getattr 獲取屬性
setattr 設置屬性
delattr 刪除屬性
好處: 可以提前定義好接口、接基於類的視圖
CBV源碼中應用很多
根據請求方式的不同自動匹配執行對應的方法,在url路由中的views.類名.as_view()的源碼下可以看到@classmethods修飾的類方法。內部定義閉包函數傳參並返回閉包函數名、在django啟動的時候會執行urls的as_view()產生變形為views.view,在接受請求的時候會觸發view方法,通過view下的self使用用類產生對象。返回self.dispatch屬性、在父類中的dispatch函數通過反射機制就通過字符串操作對象屬性,執行對應的方法
drf的APIView源碼: 繼承view,新增一點功能,使csrf認證在drf中失效
元類: 創建類的類就是元類,函數type其實就是一個元類,type就是python在背後用來創建所有類的元類。 object繼承type類,type類又是object類的元類, type是type的元類
魔法方法:
__call__,__init__,__new__,__str__,__enter__,__exit__
猴子補丁:
猴子補丁主要功能就是動態的屬性替換。用ujson替換json
進程是CPU資源分配的基本單位,線程是獨立運行和獨立調度的基本單位(CPU上真正運行的是線程)
進程擁有自己的資源空間,一個進程包含若干個線程,線程與cpu資源分配無關,多個線程共享同一進程內的資源
線程的調度與切換比進程快很多
協程是單線程下的並發,是一種用戶態的輕量級線程,即協程是有用戶程序自己控制調度的
對於多核CPU,利用多進程+協程的方式,能充分利用CPU,獲得極高的性能
''' 通過gevent模塊,實現並發同步或者異步編程,在gevent中用到的主要模式是Greenlet, '''
四種IO模型:
阻塞IO,
非阻塞IO(發送請求後開始輪詢直到數據返回),
IO多路復用 利用select來監管多個程序 一旦某個程序需要的數據存在於內存中了 那麼立刻通知該程序去取即可,
異步IO 只需要發起一次系統調用 之後無需頻繁發送 有結果並准備好之後會通過異步回調機制反饋給調用者
同步: 指提交一個任務,任務提交後在原地等待提交結束,之後再去提交下一個任務。沒有得到結果之前,改調用就不會返回
異步: 提交一個任務,提交之後不能提交的任務運行完直接提交下一個任務。
同步就是當一個進程發起一個函數(任務)調用的時候,一直等到函數 (任務)完成,而進程繼續處於激活狀態。而異步情況下是當一個進程發起一個函數(任務)調用的時候,不會等函數 返回,而是繼續往下執行當,函數返回的時候通過狀態、通知、事件等方式通知進程任務完成。
GIL鎖: 全局解釋器鎖,它不是python的特性,它是cpython解釋器,為了保證同一時刻只有一個線程可以執行代碼而設計的。
只有當前線程遇到I/O,或者字節碼執行100行(python中計時器時間達到阙值),才會釋放GIL鎖。線程的運行仍然有先後順序,並不是同時進行
python使用多進程可以利用多核CPU的優勢
多線程爬取比單線程性能有提升,因為遇到IO阻塞會自動釋放GIL鎖。多進程可以充分使cpu的兩個內核,而多線程不能充分使用cpu的兩個內核。GIL鎖,導致我們使用多線程的時候無法實現並行
解決方案:
1. 更換解釋器
2. 使用其他語言,c go
3. 采用多進程完成多任務的處理
采用多進程操作同一份數據,會出現數據錯亂的問題
針對上述問題,解決方案就是進行加鎖處理。將並發變成串行,通過犧牲效率保證數據安全
行鎖,表鎖,
HTTP協議,又叫超文本傳輸協議,是一個基於請求響應,無狀態,短鏈接,作用於tcp/ip應用層上的協議。規定了浏覽器和服務端之間的數據交互的格式。缺點: 明文傳輸,不安全
HTTPS協議
安全超文本協議,HTTP+SSL/TLS,采用密文傳輸
HTTP特點:
(1)無狀態:協議對客戶端沒有狀態存儲,對事物處理沒有“記憶”能力,比如訪問一個網站需要反復進行登錄操作
(2)無連接:HTTP/1.1之前,由於無狀態特點,每次請求需要通過TCP三次握手四次揮手,和服務器重新建立連接。比如 某個客戶機在短時間多次請求同一個資源,服務器並不能區別是否已經響應過用戶的請求,所以每次需要重新響應請 求,需要耗費不必要的時間和流量。
(3)基於請求和響應:基本的特性,由客戶端發起請求,服務端響應
(4)簡單快速、靈活
(5)通信使用明文、請求和響應不會對通信方進行確認、無法保護數據的完整性
HTTPS特點:
(1)基於HTTP協議,通過SSL或TLS提供加密處理數據、驗證對方身份以及數據完整性保護
(2)內容加密:采用混合加密技術,中間者無法直接查看明文內容
(3)驗證身份:通過證書認證客戶端訪問的是自己的服務器
(4)保護數據完整性:防止傳輸的內容被中間人冒充或者篡改
websocket協議 數據傳輸是密文
請求首行
請求頭
請求體
響應首行
響應頭
響應體
tcp協議:
也叫流式協議,可靠傳輸協議,通過3次握手建立鏈接,四次揮手斷開鏈接,數據通過連接通道傳輸,tcp提供超時重發,丟棄重復數據,檢驗數據,流量控制等功能,確保數據傳輸安全有保障。
udp協議:
又叫不可靠傳輸協議,是一個簡單的面向數據報的傳輸層協議。udp不可靠,只負責把數據報發送出去,不確保數據的安全抵達,沒有超時重發等機制,因此傳輸速度很快
Django是一個由python 編寫的一個開放源代碼的 web 應用框架,特點是大而全,功能強大,有很多內置的中間件,可重用性高。能實習快速開發
Django的MTV模式本質上和MVC是一樣的,只是在定義上有些許不同,
M: 模型 負載業務對象和數據庫的關系映射ORM
T: 模板 負責如何把頁面展示給用戶
V: 視圖 負責業務邏輯
docker-compose
單機下的容器編排工具,批量管理docker容器
docker-compose中可以通過haproxy做負載均衡
Redis適合做計數器原因
1.incr, decr 自增自檢 incr age
incrby, decrby 增加減少指定數 incrby age 10
2. redis單線程架構(6.0之前的版本),無競爭,無線程切換
redis 單線程快的原因
1. 基於內存
2. 底層采用基於epll的io多路復用
3. 避免了線程之間的切換和競態消耗
注意:
做持久化的是另外的線程
計算網站每個用戶主頁的訪問量可以用 hincrby 實現
muti 開啟事務 watch + muti 實現樂觀鎖
網站日活用set類型,優化 hyperLogLog(或者布隆過濾器)完成日活統計
樂觀鎖: 樂觀的認為取出數據不一定修改,數據不加鎖,修改前會再次取出數據,數據沒改變,執行修改操作,改 變了就重新執行,或者不執行
悲觀鎖: 悲觀的認為取出數據就一定修改,就給數據加鎖,直到數據處理完,釋放鎖,別的線程才能拿到數據
通過不斷地縮小想要獲取的數據的范圍來篩選出最終想要的結果,同時把隨機的事件變成順序的事件
B+樹特點,
1. 非葉子結點不存儲數據,只存儲鍵(樹的一個結點就是一個頁,數據庫中的頁的大小是固定的,innodb存儲引擎默認一頁為16kb),所以在頁大小固定的前提下,能放入更多的結點,相應的樹的高度就會更矮,查找磁盤的IO操作就會更少,數據查詢的效率也會更快
2. B+樹的所有數據都存儲在葉子結點,並且是按找循序排序的。
主鍵和唯一索引得區別
主鍵是一種約束,唯一索引是一種索引,兩者在本質上就不同
主鍵創建後一定包含一個唯一索引,唯一索引並不一定就是主鍵
唯一性索引允許為空,主鍵不允許為空 不為空+唯一索引
主鍵索引可以被引用為外鍵,而唯一索引不能
一個表只能由一個主鍵,唯一索引又多個
celery 提供異步任務,延遲任務(需要通過utc時間)和定時任務(也可以用linux的crontab來執行),
包結構:
1. 建一個celery_task包
2. 在包裡面建一個celery.py的文件,加載django環境(去manage.py中copy)
3. 在reids中添加broker任務隊列和任務執行完的結果存儲在哪
4. 生成一個celery對象,對象裡面傳入任務和任務路徑
5. 然後把任務分類建在不同的py文件中即可,最後啟動worker和beat(觸發器:到時間就把任務提交給celery)
def hubble_sort(li):
for i in range(len(li)-1):
exchange = False
for j in range(len(li)-i-1):
if li[j] > li[j+1]:
li[j], li[j+1] = li[j+1], li[j]
exchange = True
if not exchange:
return
比較相鄰的元素。如果第一個比第二個大,就交換他們兩個。
對每一對相鄰元素做同樣的工作,從開始第一對到結尾的最後一對。在這一點,最後的元素應該會是最大的數。
針對所有的元素重復以上的步驟,除了最後一個。
持續每次對越來越少的元素重復上面的步驟,直到沒有任何一對數字需要比較。
原理按照索引先獲取一個值,然後比較這個值和後面值的大小,順序,如果這個值小於後面的值,值做交換後,繼續往後比較
可以通過for循環嵌套實現
簡單版本,每次取出列表中最小的值,append追加到一個空列表中
def select_sort(li):
for i in range(len(li) - 1):
min_loc = i
# 每一次循環,l[min_loc] 就是當前的最小值
for j in range(i+1, len(li))
if li[j] < li[min_loc]:
min_loc = j
# 交叉賦值,把最小的值放在前面
if min_loc != i:
li[i], li[min_loc] = li[min_loc], li[i]
通過循環,每次取出亂序列表中的最小值,然後把值追加到排好序的列表最後面
def insert_sort(li):
for i in range(1, len(li)): # 排好序的最後一個值得索引
tmp = li[i]
j = i-1 # j 指得是手裡得拍得下表
while j >= 0 and li[j] > tmp:
li[j+1] = li [j]
j -= 1
li[j+1] = tmp
1. 默認列表中第一個值是已經排好序的
2. 從亂序列表中,挨個取值j,與順序列表的值從後往前依次做比較,當j的值小於已經排好序的列表中的值,把j的插入那個值前面,直到亂序列表中的值取完
參考:Python中self_個人_理解
參考:python元組(tuple)和列表(list)區別
tuple 不可變的好處
相對於 list 而言,tuple 是不可變的,這使得它可以作為 dict 的 key,或者扔進 set 裡,而 list 則不行。
tuple 放棄了對元素的增刪(內存結構設計上變的更精簡),換取的是性能上的提升:創建 tuple 比 list 要快,存儲空間比 list 占用更小。所以就出現了“能用 tuple 的地方就不用 list”的說法。
多線程並發的時候,tuple 是不需要加鎖的,不用擔心安全問題,編寫也簡單多了。
參考:_python_之淺_拷貝_和深_拷貝_的區別
淺拷貝:
淺拷貝是對一個對象父級(外層)的拷貝,並不會拷貝子級(內部)。使用淺拷貝的時候,分為兩種情況。
深拷貝:
深拷貝對一個對象是所有層次的拷貝(遞歸),內部和外部都會被拷貝過來。
深拷貝也分兩種情況:
深拷貝的作用:
地址: 更多面經