ShowMeAI日報系列全新升級!覆蓋AI人工智能 工具&框架 | 項目&代碼 | 博文&分享 | 數據&資源 | 研究&論文 等方向.點擊查看 歷史文章列表,在公眾號內訂閱話題 #ShowMeAI資訊日報,可接收每日最新推送.點擊 專題合輯&電子月刊 快速浏覽各專題全集.點擊 這裡 回復關鍵字 日報 免費獲取AI電子月刊與資料包.
https://github.com/JanPalasek/pretty-jupyter
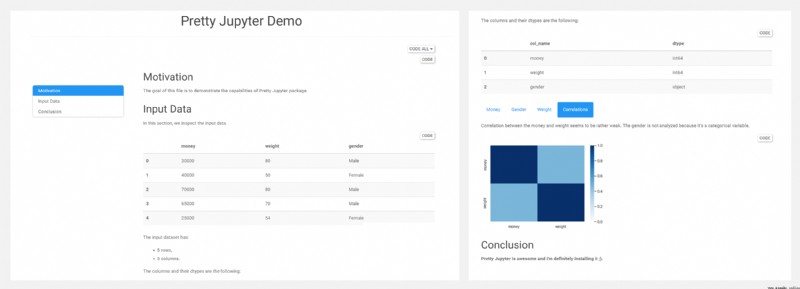
Pretty Jupyter 從 Jupyter Notebook 創建樣式精美的動態 html 網頁,可以自動生成目錄、折疊代碼塊等,並且這些功能直接集成在輸出的 html 頁面中,不需要在後端運行解釋器.項目提供了在線 demo,感興趣可以試一下!
https://github.com/microsoft/SynapseML
https://microsoft.github.io/SynapseML/
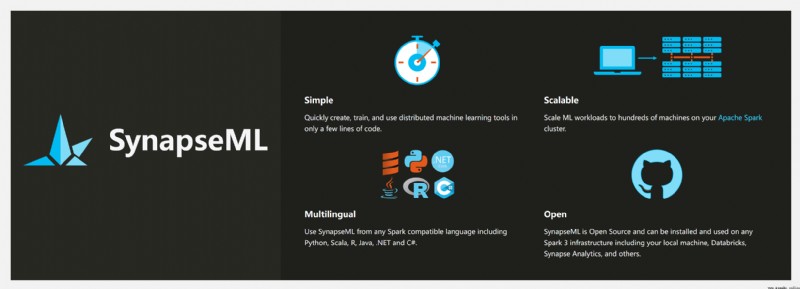
SynapseML 是一個開源庫,基於 Apache Spark 和 SparkML 構建,支持機器學習、分析和模型部署工作流.SynapseML 為 Spark 生態系統添加了許多深度學習和數據科學工具,包括 Spark 機器學習管道、開放神經網絡交換 (ONNX)、 LightGBM、 認知服務、 Vowpal Wabbit 和 OpenCV 的無縫集成等,為各種數據源提供強大且高度可擴展的預測和分析模型.
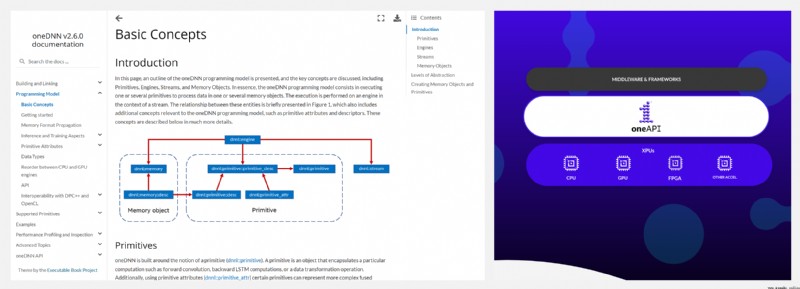
https://github.com/oneapi-src/oneDNN
oneDNN 是面向深度學習應用的開源跨平台性能庫,之前被稱作 Intel MKL-DNN、DNNL,是 oneAPI 的一部分.oneDNN 針對英特爾 架構處理器、英特爾處理器顯卡和 Xe 架構顯卡進行了優化,提高了英特爾 CPU 和 GPU 上的應用程序性能.對此感興趣的深度學習開發人員不要錯過~
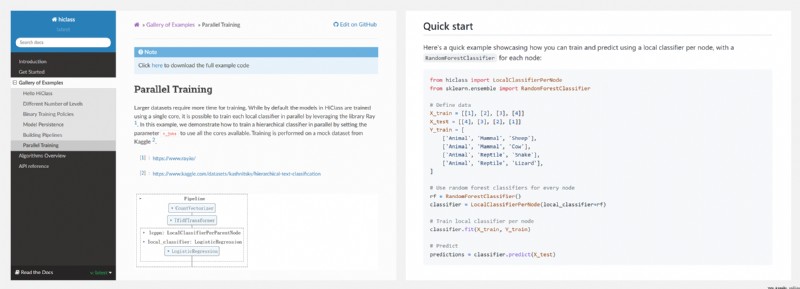
https://github.com/mirand863/hiclass
HiClass 是一個開源的 Python 庫,用於與 Scikit-Learn 兼容的層次化分類,反映了 Scikit-Learn 中流行的 API,並且允許使用最常見的本地層次化分類設計模式進行訓練和預測.
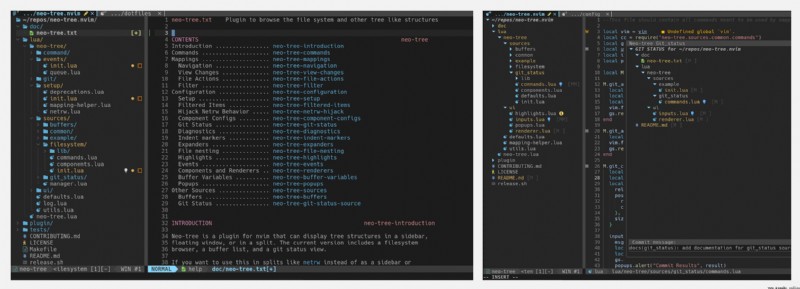
https://github.com/nvim-neo-tree/neo-tree.nvim
Neo-tree 是一個 Neovim 插件,可以浏覽文件系統和其他樹狀結構,包括側邊欄、浮動窗口等.
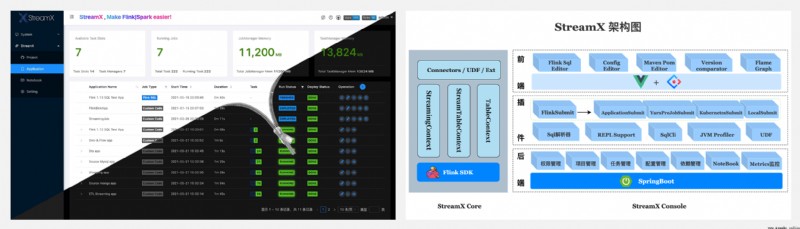
https://github.com/streamxhub/streamx
StreamX 提供開箱即用的流式大數據開發體驗,規范了項目的配置,鼓勵函數式編程,定義了最佳的編程方式,提供了一系列開箱即用的 Connectors,標准化了配置、開發、測試、部署、監控、運維的整個過程,提供了 Scala/Java 兩套 api,打造了一站式大數據平台.項目的初衷是讓流處理更簡單,極大降低學習成本和開發門檻, 讓開發者只用關心最核心的業務.
https://github.com/mikeroyal/Photogrammetry-Guide
為了幫助初學者在投稿時快速定位&避免一些小錯誤,項目總結了作者在投稿過程中的經驗.項目列寫的常見錯誤均配有正反示例,終稿必查可用於投稿前一周的自查,並匯總了網絡上優質的公開資源.

https://github.com/mikeroyal/Photogrammetry-Guide
Photogrammetry Guide 涵蓋攝影測量的學習資源、應用程序/庫/工具、Autodesk 開發、LiDAR 開發、游戲開發、機器學習、Python 開發、R 開發等,可以幫助使用者更高效地進行攝影測量開發.

https://github.com/mattharrison/effective_pandas_book
https://github.com/visionxiang/awesome-camouflaged-object-detection

可以點擊 這裡 回復關鍵字日報,免費獲取整理好的論文合輯.
科研進展
- CVPR 2022 『計算機視覺』 MiniViT: Compressing Vision Transformers with Weight Multiplexing
- 2022.07.20 『計算機視覺』 CoSMix: Compositional Semantic Mix for Domain Adaptation in 3D LiDAR Segmentation
- 2022.07.21 『計算機視覺』 TinyViT: Fast Pretraining Distillation for Small Vision Transformers
- 2022.07.16 『計算機視覺』 You Should Look at All Objects
論文時間:CVPR 2022
所屬領域:計算機視覺
對應任務:Image Classification,圖像分類
論文地址:https://arxiv.org/abs/2204.07154
代碼實現:https://github.com/microsoft/cream,https://github.com/microsoft/AutoML
論文作者:Jinnian Zhang, Houwen Peng, Kan Wu, Mengchen Liu, Bin Xiao, Jianlong Fu, Lu Yuan
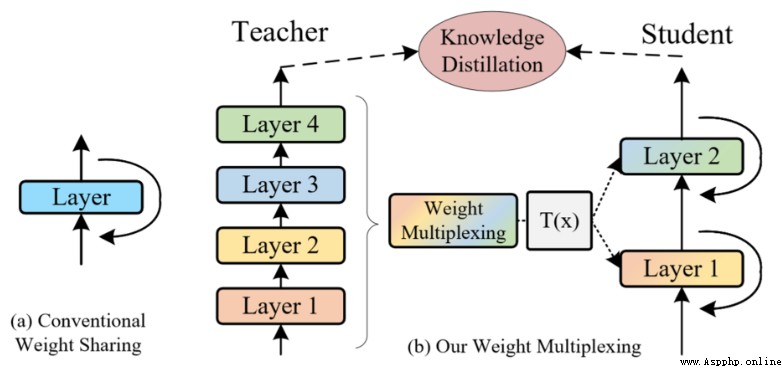
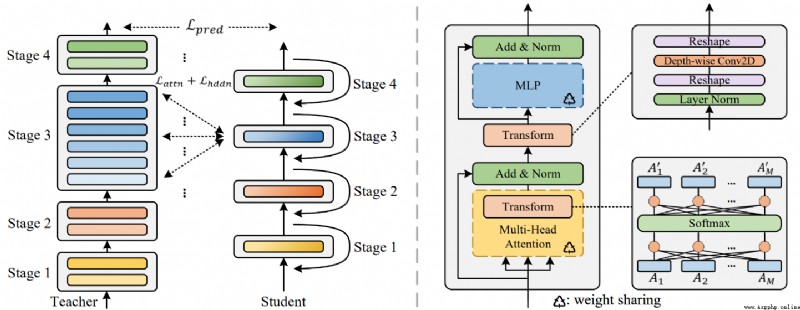
論文簡介:The central idea of MiniViT is to multiplex the weights of consecutive transformer blocks./MiniViT的核心思想是對連續的transformer塊的權重進行復用.
論文摘要:視覺Transformer(ViT)模型由於其較高的模型能力,最近在計算機視覺領域引起了廣泛關注.然而,ViT模型有大量的參數,限制了它們在有限內存設備上的適用性.為了緩解這個問題,我們提出了MiniViT,一個新的壓縮框架,它在保持相同性能的同時實現了視覺Transformer的參數減少.MiniViT的核心思想是復用連續Transformer塊的權重.更具體地說,我們使權重在各層之間共享,同時對權重進行轉換以增加多樣性.在自注意上的權重提煉也被應用於將知識從大規模的ViT模型轉移到權重復用的緊湊模型.綜合實驗證明了MiniViT的功效,表明它可以將預先訓練好的Swin-B變換器的大小減少48%,同時在ImageNet上實現了1.0%的Top-1准確性的提高.此外,使用單層參數,MiniViT能夠將DeiT-B的參數從86M壓縮到9M的9.7倍,而不會嚴重影響其性能.最後,我們通過報告MiniViT在下游基准上的表現來驗證它的可轉移性.
論文時間:20 Jul 2022
所屬領域:計算機視覺
對應任務:Autonomous Driving,Domain Adaptation,LIDAR Semantic Segmentation,Point Cloud Segmentation,Semantic Segmentation,Unsupervised Domain Adaptation,自主駕駛,領域適應,激光雷達語義分割,點雲分割,語義分割,無監督領域適應
論文地址:https://arxiv.org/abs/2207.09778
代碼實現:https://github.com/saltoricristiano/cosmix-uda
論文作者:Cristiano Saltori, Fabio Galasso, Giuseppe Fiameni, Nicu Sebe, Elisa Ricci, Fabio Poiesi
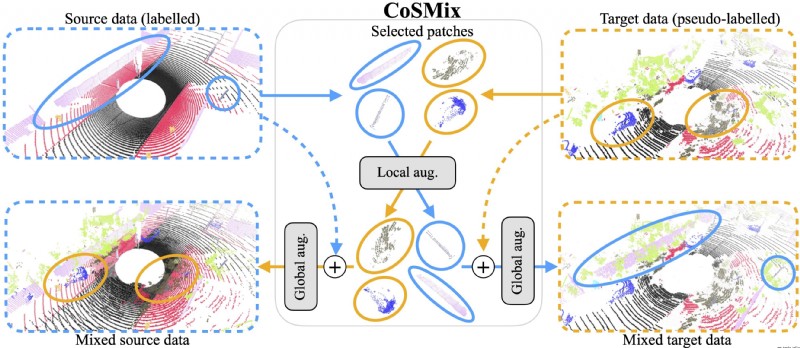
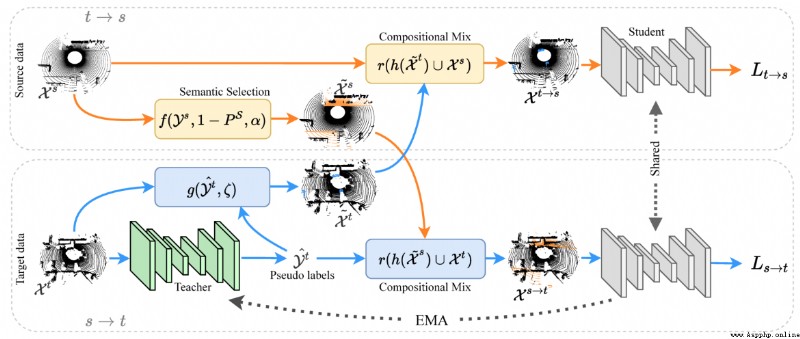
論文簡介:We propose a new approach of sample mixing for point cloud UDA, namely Compositional Semantic Mix (CoSMix), the first UDA approach for point cloud segmentation based on sample mixing./我們提出了一種用於點雲UDA的新的樣本混合方法,即組合式語義混合(CoSMix),這是第一個基於樣本混合的點雲分割UDA方法.
論文摘要:3D LiDAR語義分割是自主駕駛的基礎.最近提出了幾種用於點雲數據的無監督領域適應(UDA)方法,以提高不同傳感器和環境的模型通用性.在圖像領域研究UDA問題的研究人員已經表明,樣本混合可以緩解領域轉移.我們提出了一種用於點雲UDA的新的樣本混合方法,即組合式語義混合(CoSMix),這是第一個基於樣本混合的點雲分割UDA方法.CoSMix由一個雙分支的對稱網絡組成,可以同時處理標記的合成數據(源)和真實世界的無標記點雲(目標).每個分支通過混合來自另一個領域的選定數據,並利用從源標簽和目標偽標簽中獲得的語義信息,在一個領域中運行.我們在兩個大規模的數據集上對CoSMix進行了評估,結果顯示它在很大程度上勝過了最先進的方法.我們的代碼可在https://github.com/saltoricristiano/cosmix-uda獲取.

論文時間:21 Jul 2022
所屬領域:計算機視覺
對應任務:Image Classification,Knowledge Distillation,圖像分類,知識蒸餾
論文地址:https://arxiv.org/abs/2207.10666
代碼實現:https://github.com/microsoft/cream
論文作者:Kan Wu, Jinnian Zhang, Houwen Peng, Mengchen Liu, Bin Xiao, Jianlong Fu, Lu Yuan
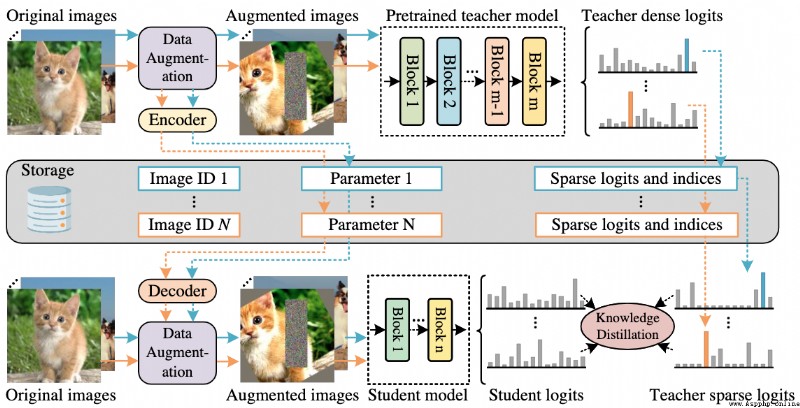
論文簡介:It achieves a top-1 accuracy of 84. 8% on ImageNet-1k with only 21M parameters, being comparable to Swin-B pretrained on ImageNet-21k while using 4. 2 times fewer parameters./它在ImageNet-1k上達到了84.8%的最高准確率.8%,與在ImageNet-21k上預訓練的Swin-B相當,而使用的參數少4.2倍.
論文摘要:視覺transformer(ViT)由於其顯著的模型能力,最近在計算機視覺領域引起了極大的關注.然而,大多數流行的ViT模型存在大量的參數,限制了它們在資源有限的設備上的適用性.為了緩解這個問題,我們提出了TinyViT,一個新的微小而高效的小型視覺transformer系列,通過我們提出的快速蒸餾框架對大規模數據集進行預訓練.其核心思想是將知識從大型預訓練模型轉移到小型模型上,同時使小型模型能夠獲得大規模預訓練數據的好處.更具體地說,我們在預訓練期間應用蒸餾法進行知識轉移.大型教師模型的對數被稀疏化並提前存儲在磁盤中,以節省內存成本和計算開銷.小小的學生transformer在計算和參數的限制下從大型預訓練模型中自動縮減.綜合實驗證明了TinyViT的功效.它在ImageNet-1k上僅用21M的參數就達到了84.8%的最高准確率,與在ImageNet-21k上預訓練的Swin-B相當,而使用的參數少了4.2倍.此外,提高圖像分辨率,TinyViT可以達到86.5%的准確率,略好於Swin-L,而只使用11%的參數.最後但同樣重要的是,我們證明了TinyViT在各種下游任務中的良好轉移能力.代碼和模型可在https://github.com/microsoft/Cream/tree/main/TinyViT獲取.
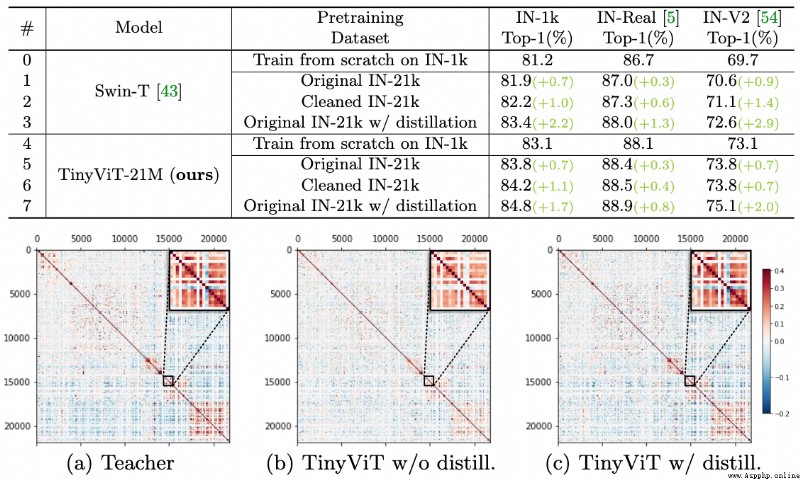
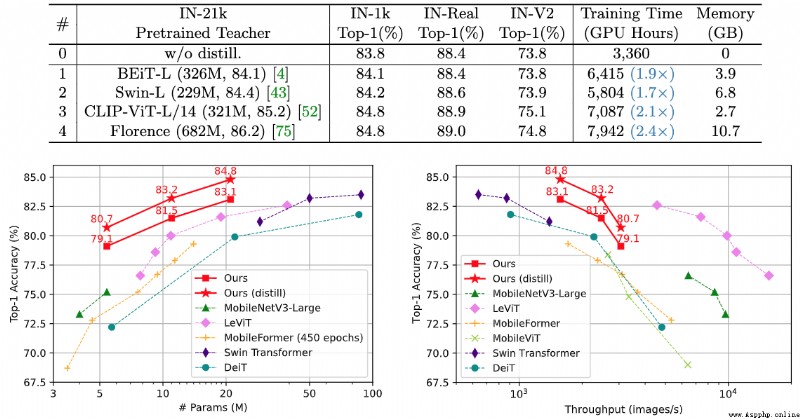
論文時間:16 Jul 2022
所屬領域:計算機視覺
對應任務:目標檢測
論文地址:https://arxiv.org/abs/2207.07889
代碼實現:https://github.com/charlespikachu/yslao
論文作者:Zhenchao Jin, Dongdong Yu, Luchuan Song, Zehuan Yuan, Lequan Yu
論文簡介:Feature pyramid network (FPN) is one of the key components for object detectors./特征金字塔網絡(FPN)是物體檢測器的關鍵組件之一.
論文摘要:特征金字塔網絡(FPN)是物體檢測器的關鍵組件之一.然而,對於研究人員來說,有一個長期的困惑,即引入FPN後,大規模物體的檢測性能通常會被抑制.為此,本文首先在檢測框架中重新審視FPN,並從優化的角度揭示了FPN成功的本質.然後,我們指出,大規模物體的性能下降是由於整合FPN後產生了不恰當的反向傳播路徑.這使得骨干網絡的每一級都只有能力查看一定規模范圍內的對象.基於這些分析,我們提出了兩種可行的策略,以使每一級骨干網絡能夠觀察到基於FPN的檢測框架中的所有物體.具體來說,一種是引入輔助目標函數,使每個骨干層在訓練時直接接收各種尺度物體的反傳播信號.另一個是以更合理的方式構建特征金字塔,避免不合理的反向傳播路徑.在COCO基准上進行的大量實驗驗證了我們的分析的合理性和我們方法的有效性.在沒有任何花哨技巧的情況下,我們證明了我們的方法在各種檢測框架上取得了堅實的改進(超過2%):單階段、雙階段、基於錨、無錨和基於transformer的檢測.
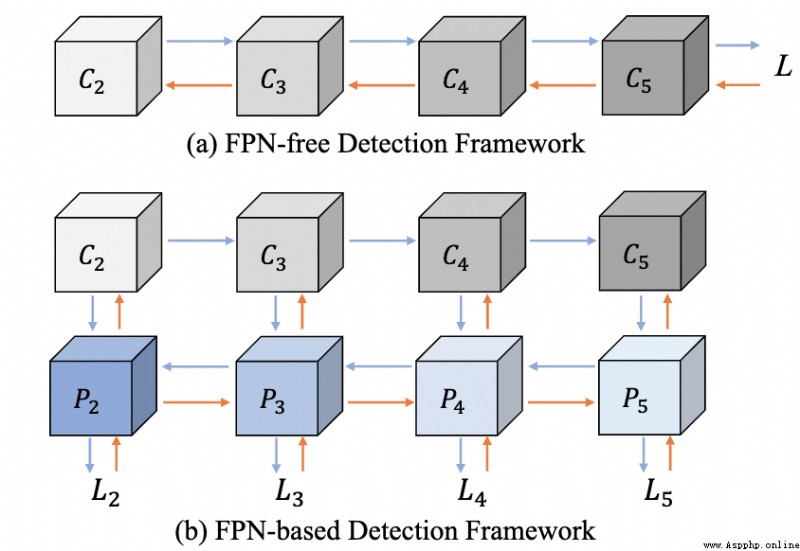
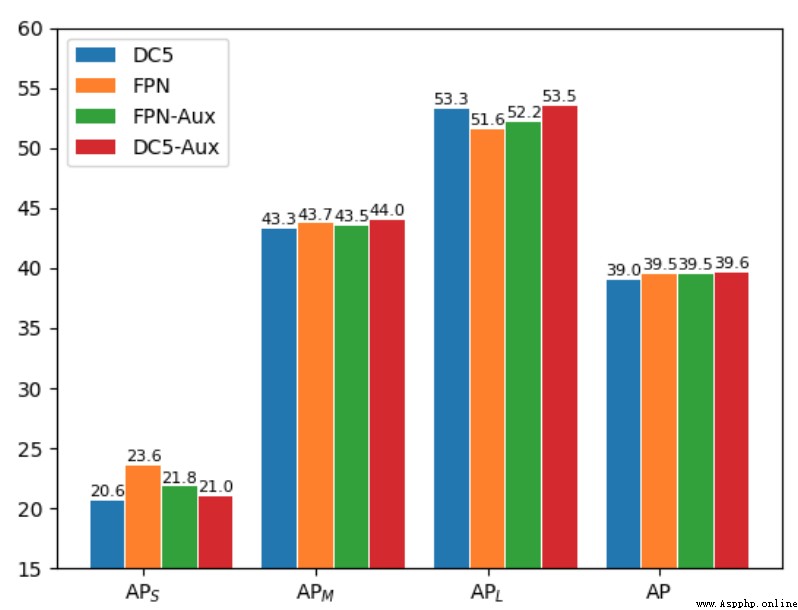
我們是 ShowMeAI,致力於傳播AI優質內容,分享行業解決方案,用知識加速每一次技術成長!點擊查看 歷史文章列表,在公眾號內訂閱話題 #ShowMeAI資訊日報,可接收每日最新推送.點擊 專題合輯&電子月刊 快速浏覽各專題全集.點擊 這裡 回復關鍵字 日報 免費獲取AI電子月刊與資料包.