pdfplumber,io
http://yjgl.tj.gov.cn/ZWFW5050/bjjggs1/202202/W020220216348928027515.pdf
http://yjgl.tj.gov.cn/ZWFW5050/bjjggs1/202201/W020220130595559114737.pdf
http://yjgl.tj.gov.cn/ZWFW5050/bjjggs1/202201/W020220130595121321067.pdf
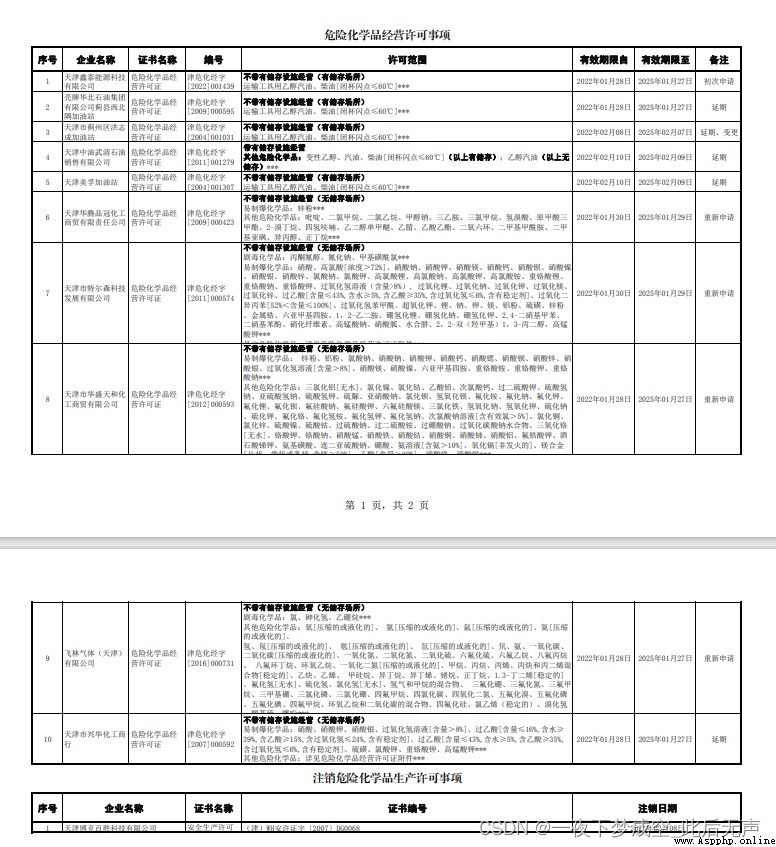
通過爬取對應pdf文件,將其二進制數據寫入內存,通過io的BytesIO對象,實現內存讀取,之後通過pdfplumber加載,最終實現對pdf文件的操作
import pdfplumber
import re
import io
import requests
def pdf_parse():
url = 'http://yjgl.tj.gov.cn/ZWFW5050/bjjggs1/202201/W020220130595559114737.pdf'
resp = requests.get(url, stream=True)
resp.encoding = resp.apparent_encoding
with pdfplumber.load(io.BytesIO(resp.content)) as pdf:
# with pdfplumber.open('video.pdf') as pdf: # 直接對本地文件操作
pages = pdf.pages
head_list = list()
for page in pages:
tables = page.extract_tables()
for table in tables:
num = 0
flag = 0
for col in table:
for i in range(len(col)):
col[i] = format_value(col[i])
num += 1
if num == 1:
if col[0][0].isnumeric():
data = dict(zip(head_list, col))
print(data)
else:
head_list = col
for i in range(len(col)):
if '注銷' in col[i]:
flag = 1
elif flag == 1:
continue
else:
if col[0] == '' and col[1] == '':
continue
data = dict(zip(head_list, col))
print(data)
if __name__ == '__main__':
pdf_parse()