Record the holes your reptiles have trodden , Last time I wrote something , But it is not clear enough , This time, , Write down the process of crawling .
This website is a volunteer service network of a province .
Is it the .
I asked crawling for some activities carried out by organizations , For example, this organization ,
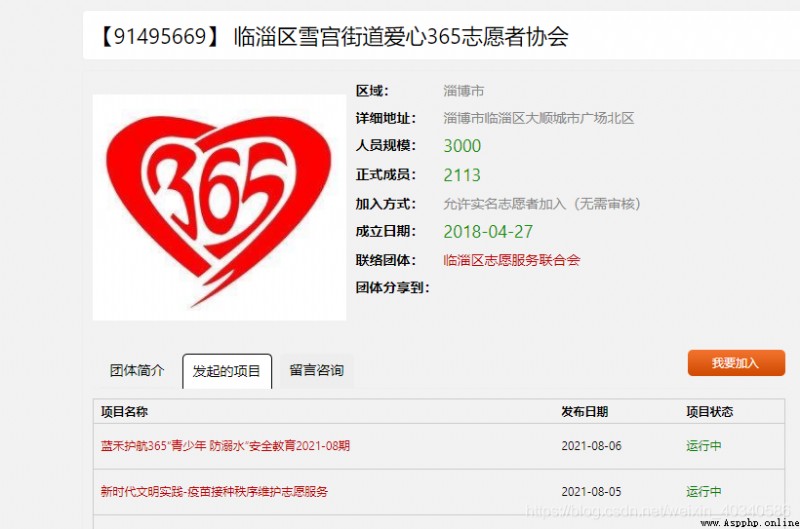
There is no problem finding and typing this organization's page , The organization's web address only needs to be spliced .
It seems easy .
The basic web address is :https://sd.zhiyuanyun.com/app/org/view.php?id=(*****)
Ahead is a pile of , You just need to put id The organization behind ID Just put it in , The organization's ID It's also very easy to find . It's OK to crawl directly from the front page . The front page of this website is not complicated .
But now I want to get a list of the activities carried out by this organization .
For example, this organization .
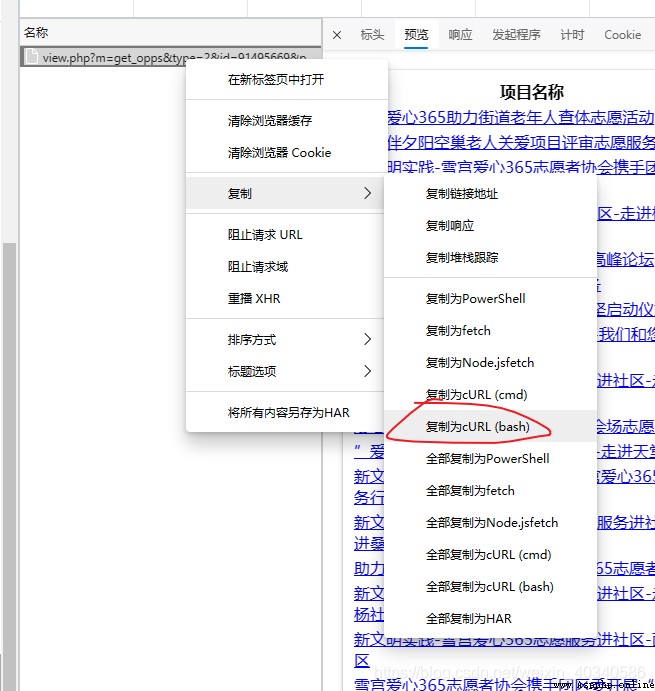
This organization has a lot of activities , It seems that there will be 16 page , There is a label at the bottom ,16.
The difficulty is how can I know that the last page is 16, Is the largest number , Some organizations only have 1 page , yes , we have 7, yes , we have 8. I need to know the number of the last page , To write a loop . You can't just write one while true To a break Well .
Now , You need to study the request mode of this web page .
This web page request uses post, instead of get. If it is get, Then the only page you can get is .
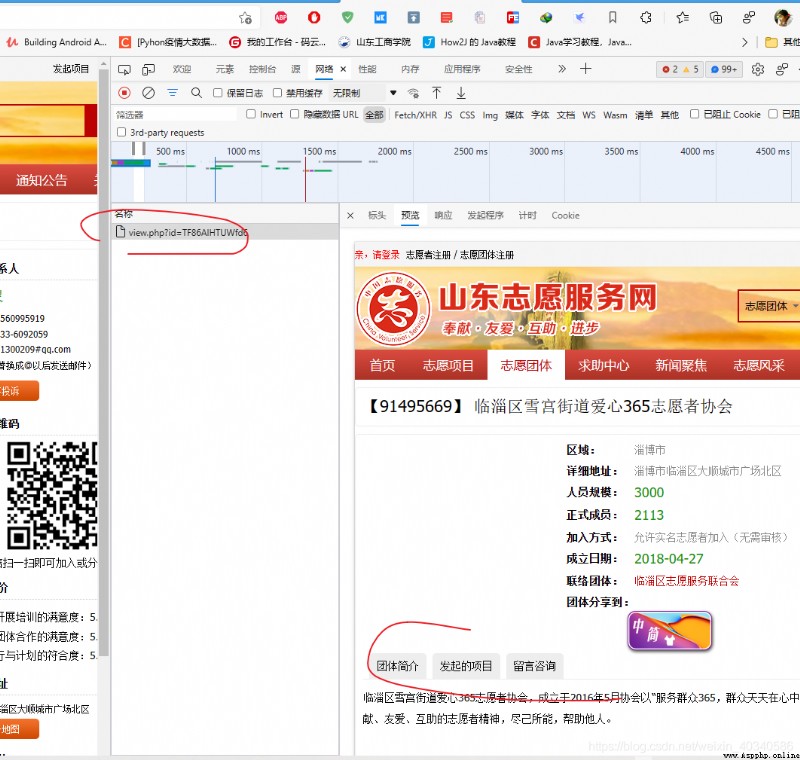
It's such a page ,get The requested URL is also correct .
https://sd.zhiyuanyun.com/app/org/view.php?id=TF86AlHTUWfd6
But this part of the project initiated , It's invisible . Study it carefully . In fact, during the request process , One more js request .
At first I thought it was xhr, namely ajax, I haven't found it for a long time .
Clear the network request information , Click on the item on a page . You'll see a post Requested
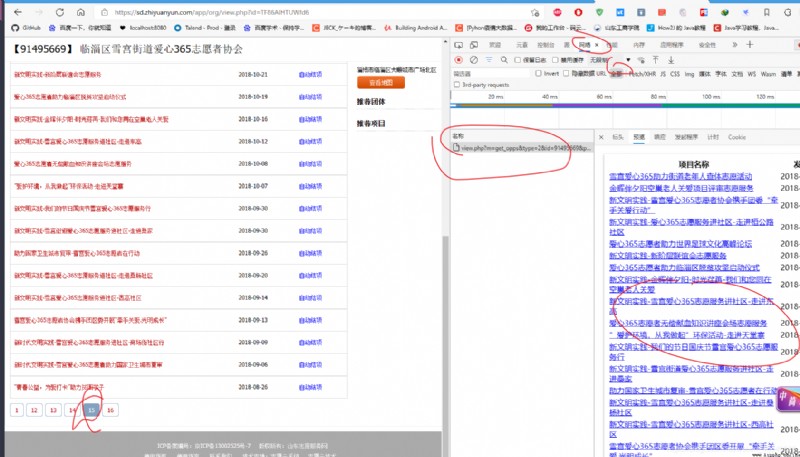
This post request , Copy it , Note that copying curl (bash)
Put this in Generate the requested web page , You can get python Request code for .
Convert curl command syntax to Python requests, Ansible URI, browser fetch, MATLAB, Node.js, R, PHP, Strest, Go, Dart, Java, JSON, Elixir, and Rust code (trillworks.com)
Convert curl command syntax to Python requests, Ansible URI, browser fetch, MATLAB, Node.js, R, PHP, Strest, Go, Dart, Java, JSON, Elixir, and Rust code
https://curl.trillworks.com/
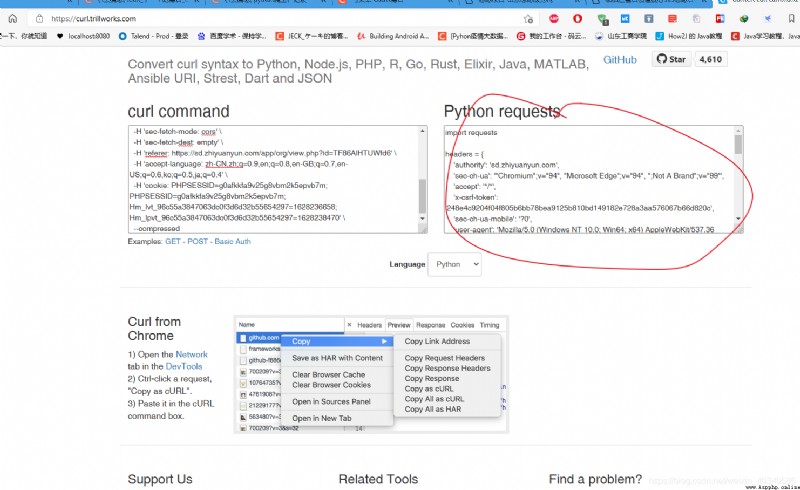
The code on the right is copied out , Put it in pycharm in ,
You can see that .
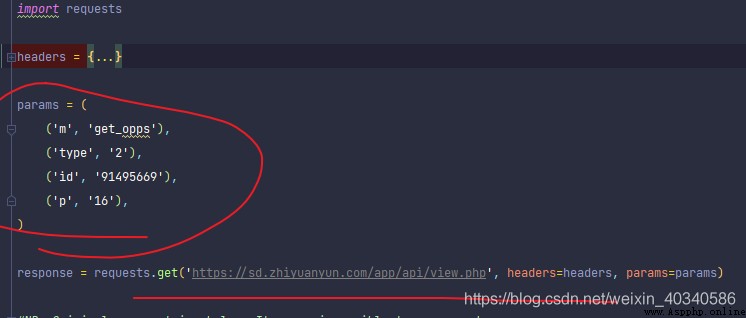
header Part omitted . The important part is the parameter part .
Note that the actual request URL here should look like this , Each parameter is combined into & and = No . The basic web address is on the horizontal line .
https://sd.zhiyuanyun.com/app/api/view.php?m=get_opps&type=2&id=91495669&p=16
So open this website , You can get the actual requested web page . That's true , A simple form page . The structure is very simple .
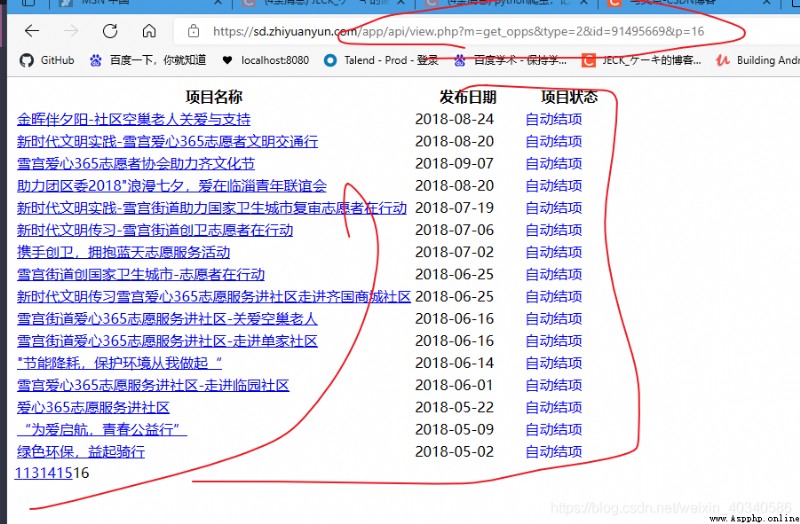
The address bar is our spliced web address ,? The following is the requested parameter , The name and value of each parameter are expressed in = link , Intermediate use & link .
So we got it .
This is the request process .
The next step is to save the data .
For this form , I've always been in trouble , So it is directly saved as a list , Put it in the dictionary .
When you use it later, you can disassemble it .
The result of the request is shown in the figure
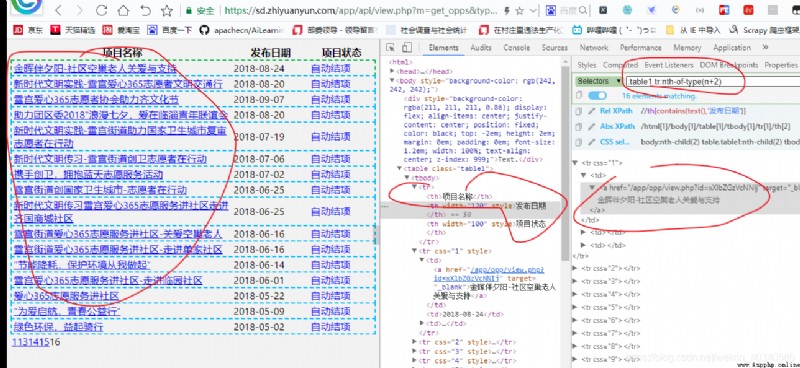
Got response In fact, it is a web page composed of forms . use selector Analyze it .
from scrapy.selector import Selector
import requests
headers = {*********************}
params = (
('m', 'get_opps'),
('type', '2'),
('id', '91495669'),
('p', '16'),
)
response = requests.get('https://sd.zhiyuanyun.com/app/api/view.php', headers=headers, params=params)
selector = Selector(response)
At this time , What I want is the information in the form , I don't want to , So I use it css Selectors , Select from tr Start ,tr Inside , In the first column tr It's the watch. , So don't use the header , use
.table1 tr:nth-of-type(n+2)
That's it
tr = selector.css(".table1 tr:nth-of-type(n+2)")
for xi in tr:
a = xi.css('td a::text').extract_first()
href = xi.css('td a::attr(href)').extract_first()
print( a , href)
Face , Then do a traversal , You can extract all the project name, time and other information .
All I want here is Project name and link , Print it out and you can see , That's true .
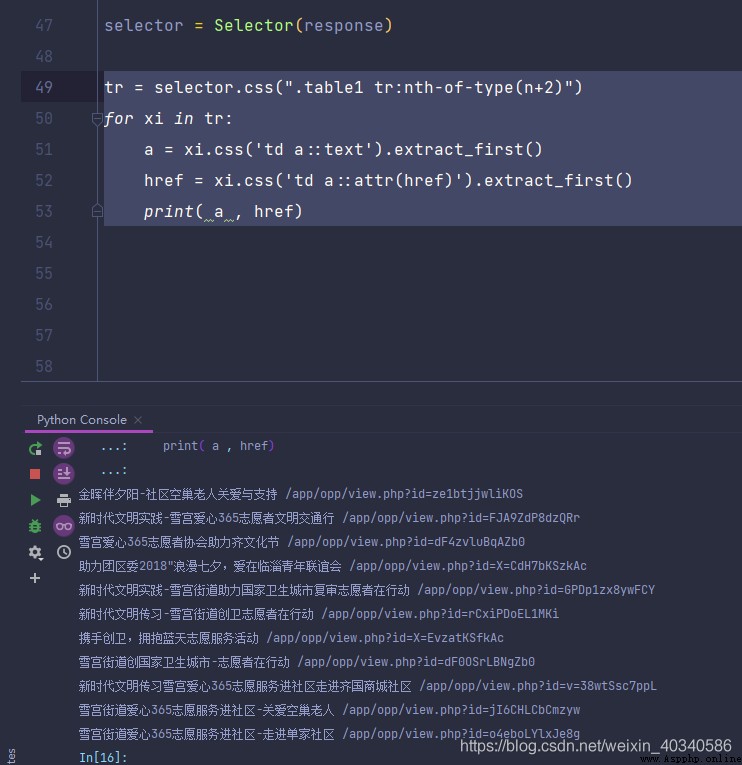
tr = selector.css(".table1 tr:nth-of-type(n+2)")
name_list = []
href_list = []
for xi in tr:
a = xi.css('td a::text').extract_first()
href = xi.css('td a::attr(href)').extract_first()
# print( a , href)
name_list.append(a)
href_list.append(href)
print(name_list, href_list)
dct_app = {}
dct_app.update(name = name_list, href = href_list)
dct_app
Save it as a dictionary , Last , Is to climb down all the organizations , This depends on how much you are willing to climb . There is also the parameter part requested above , The link of the organization in the parameter is a genetic character , And the requesting organization ID Indeed a string of numbers , This string of numbers is in square brackets before the name of each organization , therefore , This information is also necessary .