攜手創作,共同成長!這是我參與「掘金日新計劃 · 8 月更文挑戰」的第10天,點擊查看活動詳情
ShowMeAI日報系列全新升級!覆蓋AI人工智能 工具&框架 | 項目&代碼 | 博文&分享 | 數據&資源 | 研究&論文 等方向.點擊查看 歷史文章列表,在公眾號內訂閱話題 #ShowMeAI資訊日報,可接收每日最新推送.點擊 專題合輯&電子月刊 快速浏覽各專題全集.
github.com/JanPalasek/…
Pretty Jupyter 從 Jupyter Notebook Create beautifully styled dynamics html 網頁,可以自動生成目錄、Folding code blocks, etc,And these functions are directly integrated in the output html 頁面中,There is no need to run an interpreter on the backend.Projects are offered online demo,感興趣可以試一下!

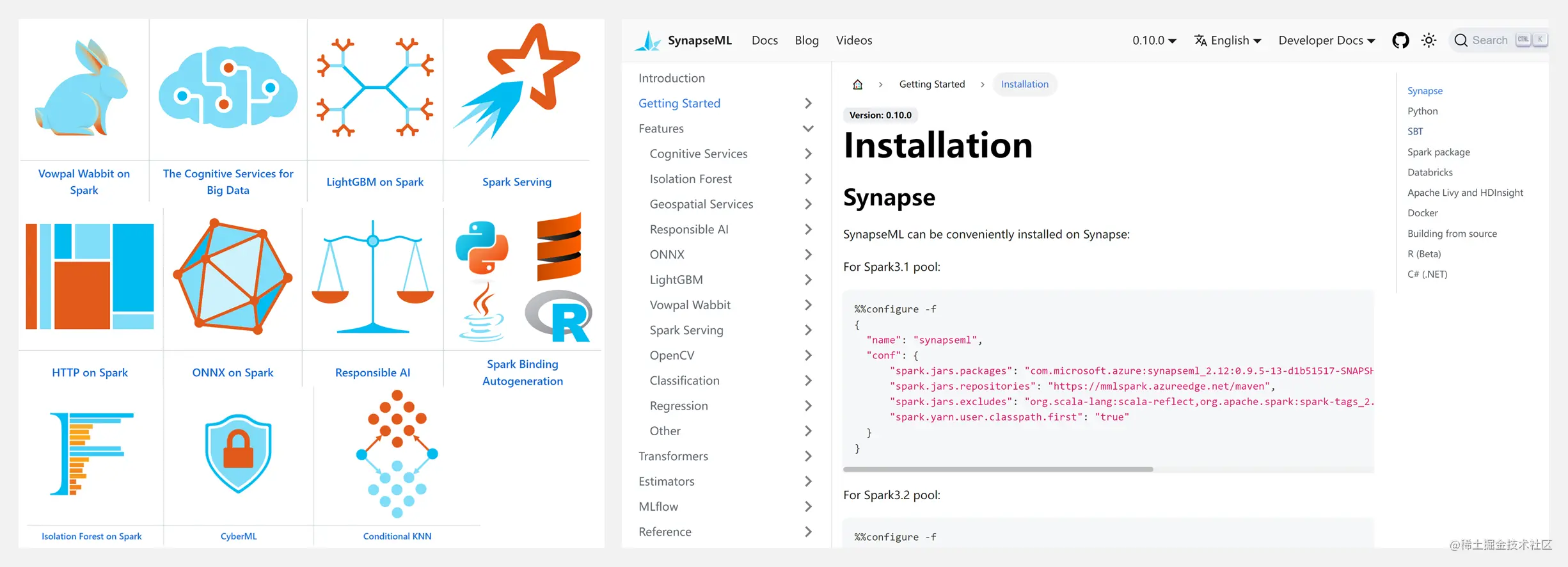
github.com/microsoft/S…
microsoft.github.io/SynapseML/
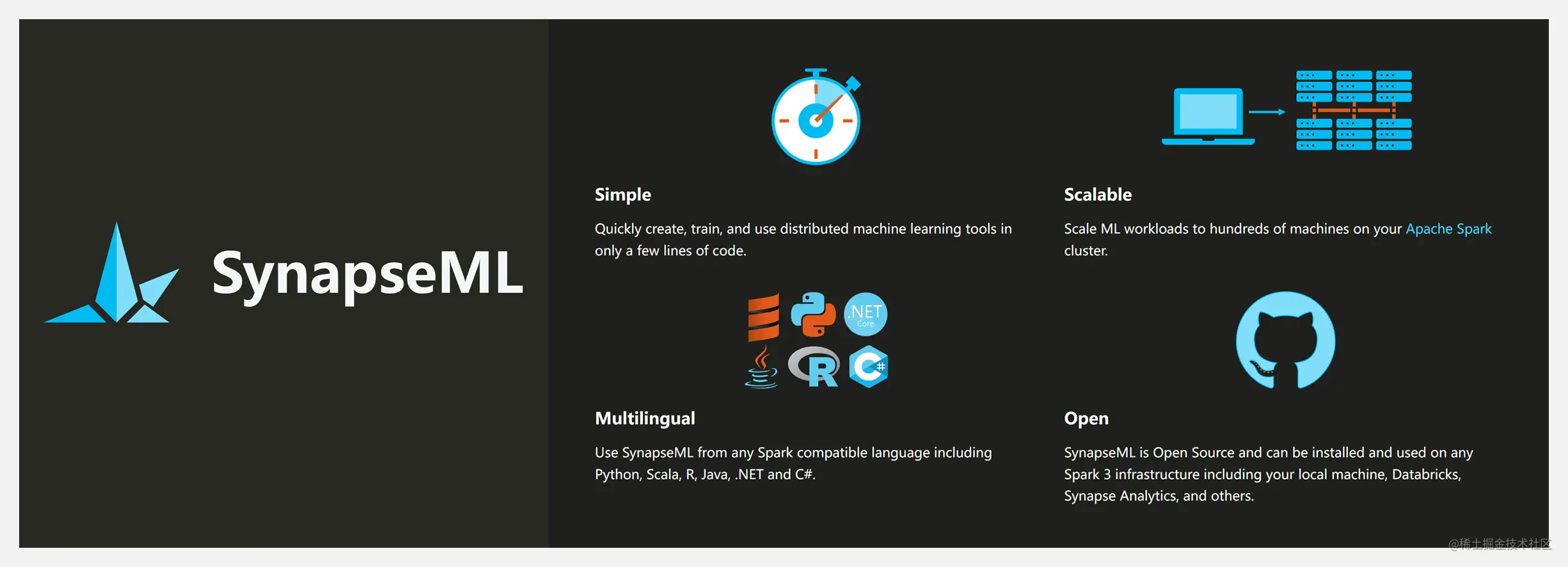
SynapseML 是一個開源庫,基於 Apache Spark 和 SparkML 構建,支持機器學習、Analysis and model deployment workflows.SynapseML 為 Spark 生態系統添加了許多深度學習和數據科學工具,包括 Spark 機器學習管道、開放神經網絡交換 (ONNX)、 LightGBM、 認知服務、 Vowpal Wabbit 和 OpenCV seamless integration, etc,Powerful and highly scalable predictive and analytical models for a variety of data sources.
github.com/oneapi-src/…
oneDNN It is an open source cross-platform performance library for deep learning applications,之前被稱作 Intel(R) MKL-DNN、DNNL,是 oneAPI 的一部分.oneDNN 針對英特爾(R) 架構處理器、Intel processor graphics and Xe The architecture graphics card has been optimized,Raised Intel CPU 和 GPU application performance.Not to be missed by deep learning developers interested in this~
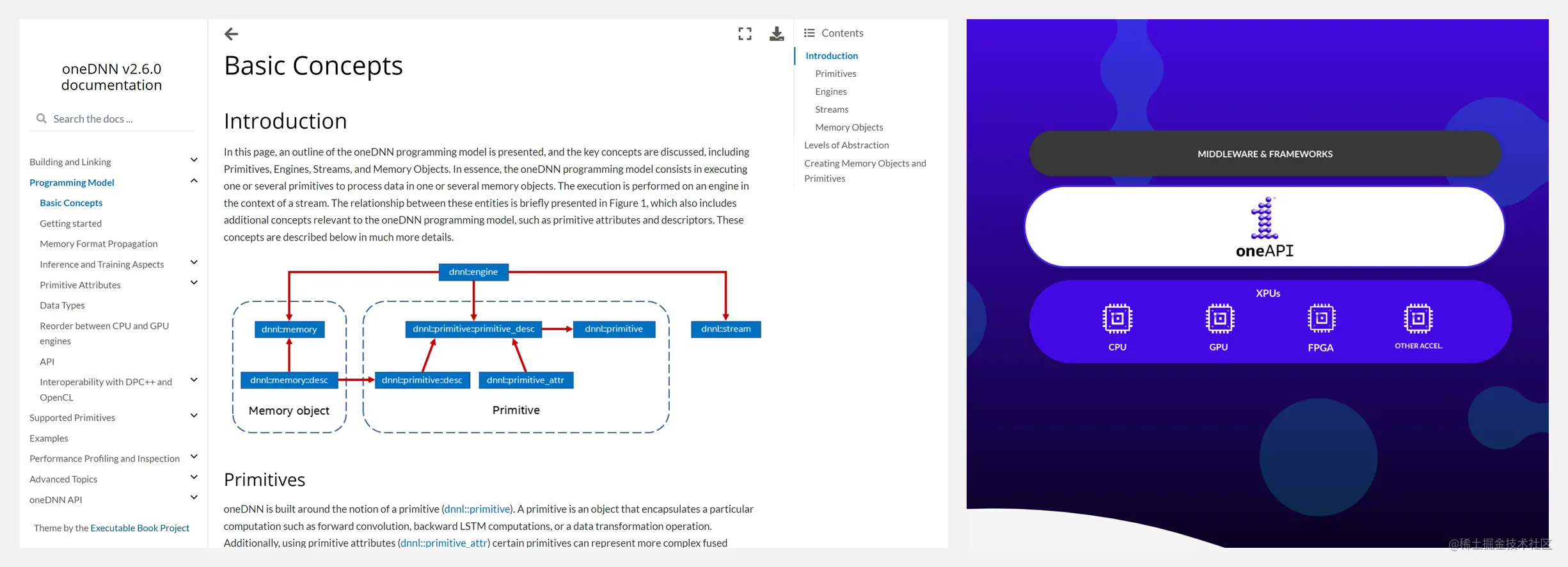
github.com/mirand863/h…
HiClass 是一個開源的 Python 庫,用於與 Scikit-Learn Compatible hierarchical classification,反映了 Scikit-Learn 中流行的 API,And allows training and prediction using the most common local hierarchical classification design patterns.
github.com/nvim-neo-tr…
Neo-tree 是一個 Neovim 插件,File systems and other tree structures can be browsed,包括側邊欄、浮動窗口等.
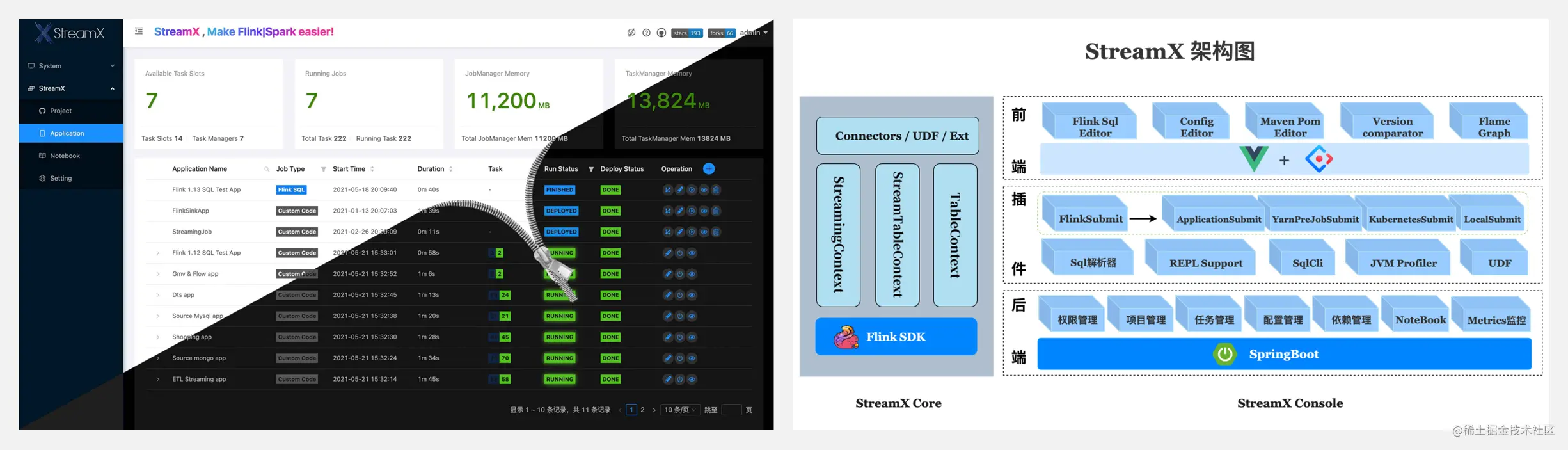
github.com/streamxhub/…
StreamX 提供開箱即用的流式大數據開發體驗,規范了項目的配置,鼓勵函數式編程,定義了最佳的編程方式,提供了一系列開箱即用的 Connectors,標准化了配置、開發、測試、部署、監控、運維的整個過程,提供了 Scala/Java 兩套 api,Created a one-stop big data platform.The original intention of the project is to make stream processing simpler,Greatly reduce the learning cost and development threshold, 讓開發者只用關心最核心的業務.
github.com/mikeroyal/P…
In order to help beginners quickly locate when submitting manuscripts&Avoid small mistakes,The project summarizes the author's experience in the submission process.Common mistakes in the project listing are provided with positive and negative examples,The final manuscript check can be used for self-checking one week before submission,And summarizes the high-quality public resources on the Internet.
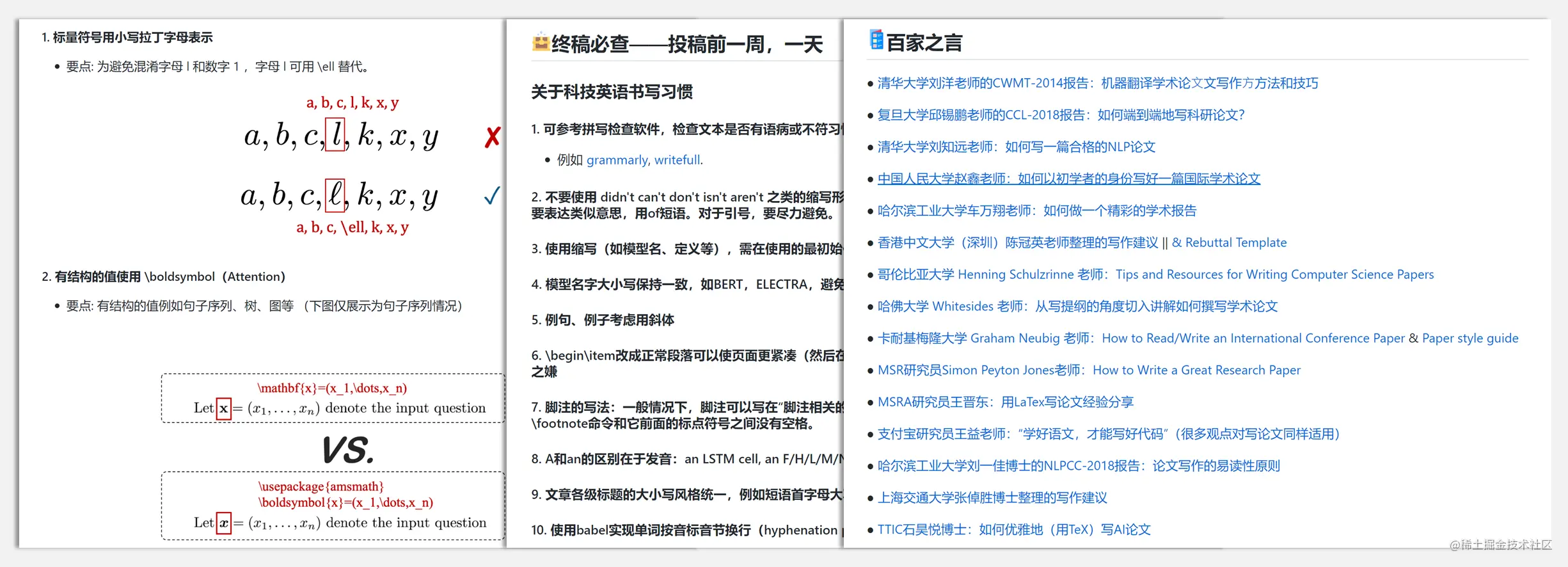
github.com/mikeroyal/P…
Photogrammetry Guide Learning resources covering photogrammetry、應用程序/庫/工具、Autodesk 開發、LiDAR 開發、游戲開發、機器學習、Python 開發、R 開發等,It can help users to develop photogrammetry more efficiently.
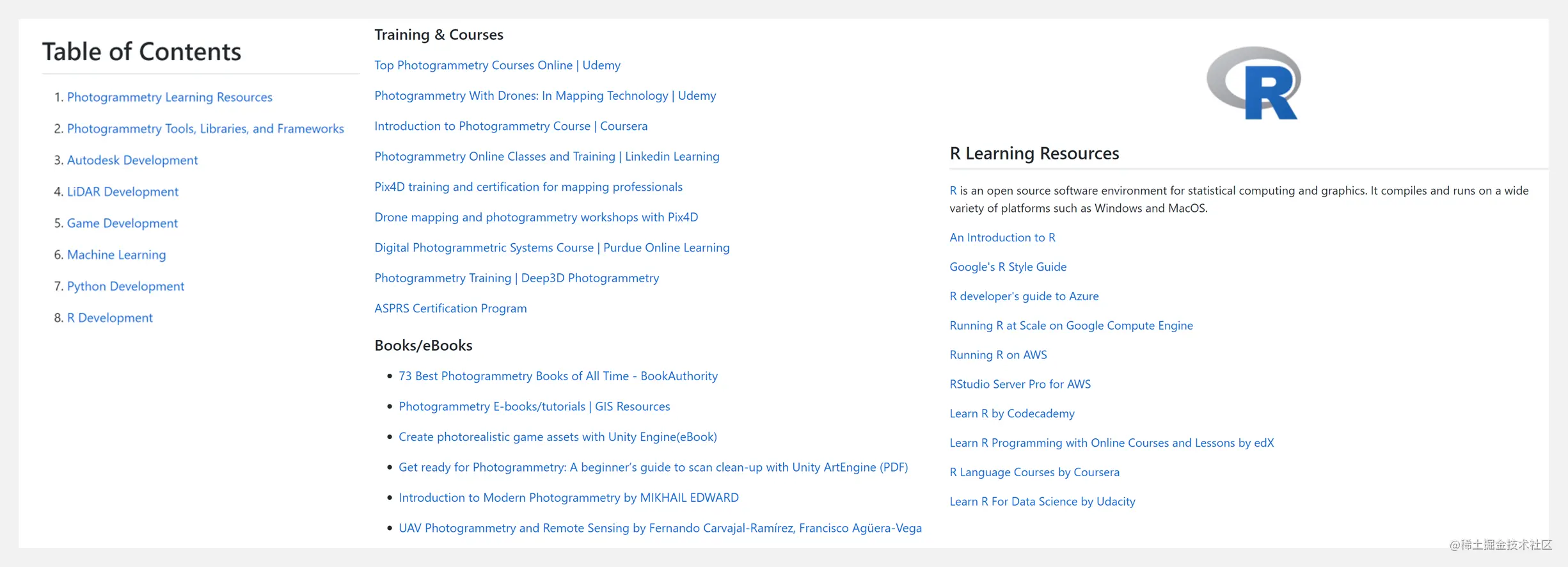

github.com/mattharriso…

github.com/visionxiang…

公眾號回復關鍵字日報,免費獲取整理好的論文合輯.
科研進展
- CVPR 2022 『計算機視覺』 MiniViT: Compressing Vision Transformers with Weight Multiplexing
- 2022.07.20 『計算機視覺』 CoSMix: Compositional Semantic Mix for Domain Adaptation in 3D LiDAR Segmentation
- 2022.07.21 『計算機視覺』 TinyViT: Fast Pretraining Distillation for Small Vision Transformers
- 2022.07.16 『計算機視覺』 You Should Look at All Objects
論文時間:CVPR 2022
所屬領域:計算機視覺
對應任務:Image Classification,圖像分類
論文地址:arxiv.org/abs/2204.07…
代碼實現:github.com/microsoft/c…
論文作者:Jinnian Zhang, Houwen Peng, Kan Wu, Mengchen Liu, Bin Xiao, Jianlong Fu, Lu Yuan
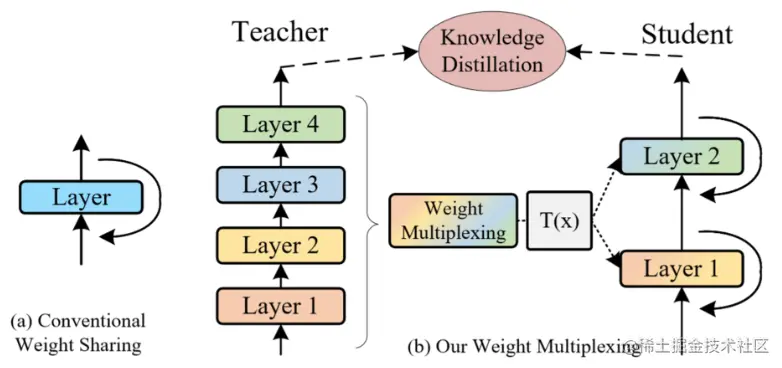
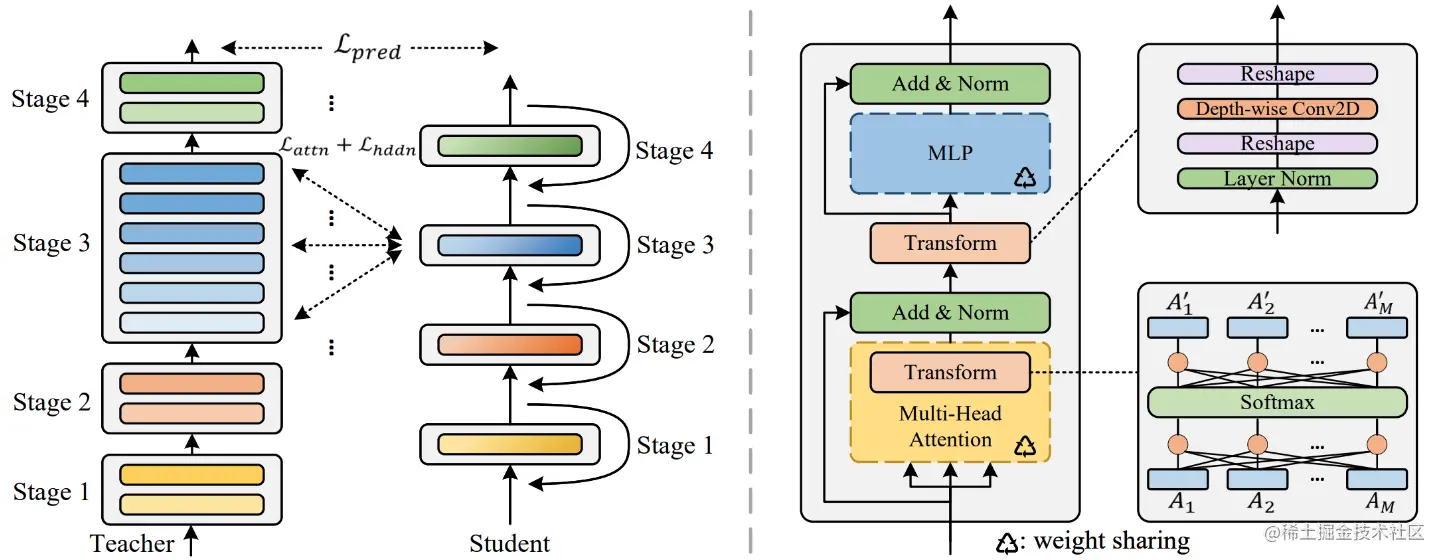
論文簡介:The central idea of MiniViT is to multiplex the weights of consecutive transformer blocks./MiniViTThe core idea is about continuitytransformerThe weights of the blocks are reused.
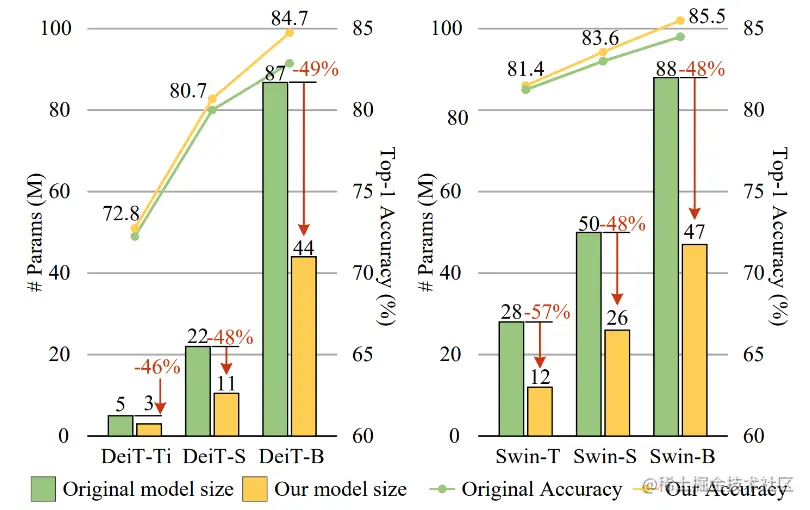
論文摘要:視覺Transformer(ViT)model due to its higher model capability,最近在計算機視覺領域引起了廣泛關注.然而,ViT模型有大量的參數,Limiting their applicability on devices with limited memory.為了緩解這個問題,我們提出了MiniViT,A new compression framework,It achieves vision while maintaining the same performanceTransformer的參數減少.MiniViTThe core idea is to reuse continuousTransformerblock weight.更具體地說,We make the weights shared among the layers,同時對權重進行轉換以增加多樣性.Weight refinement on self-attention is also applied to extract knowledge from large scaleViT模型轉移到權重復用的緊湊模型.綜合實驗證明了MiniViT的功效,show that it can be pre-trainedSwin-BThe size of the converter is reduced48%,同時在ImageNet上實現了1.0%的Top-1准確性的提高.此外,使用單層參數,MiniViT能夠將DeiT-B的參數從86M壓縮到9M的9.7倍,without seriously affecting its performance.最後,We pass the reportMiniViTperformance on downstream benchmarks to verify its transferability.
論文時間:20 Jul 2022
所屬領域:計算機視覺
對應任務:Autonomous Driving,Domain Adaptation,LIDAR Semantic Segmentation,Point Cloud Segmentation,Semantic Segmentation,Unsupervised Domain Adaptation,自主駕駛,領域適應,激光雷達語義分割,點雲分割,語義分割,無監督領域適應
論文地址:arxiv.org/abs/2207.09…
代碼實現:github.com/saltoricris…
論文作者:Cristiano Saltori, Fabio Galasso, Giuseppe Fiameni, Nicu Sebe, Elisa Ricci, Fabio Poiesi
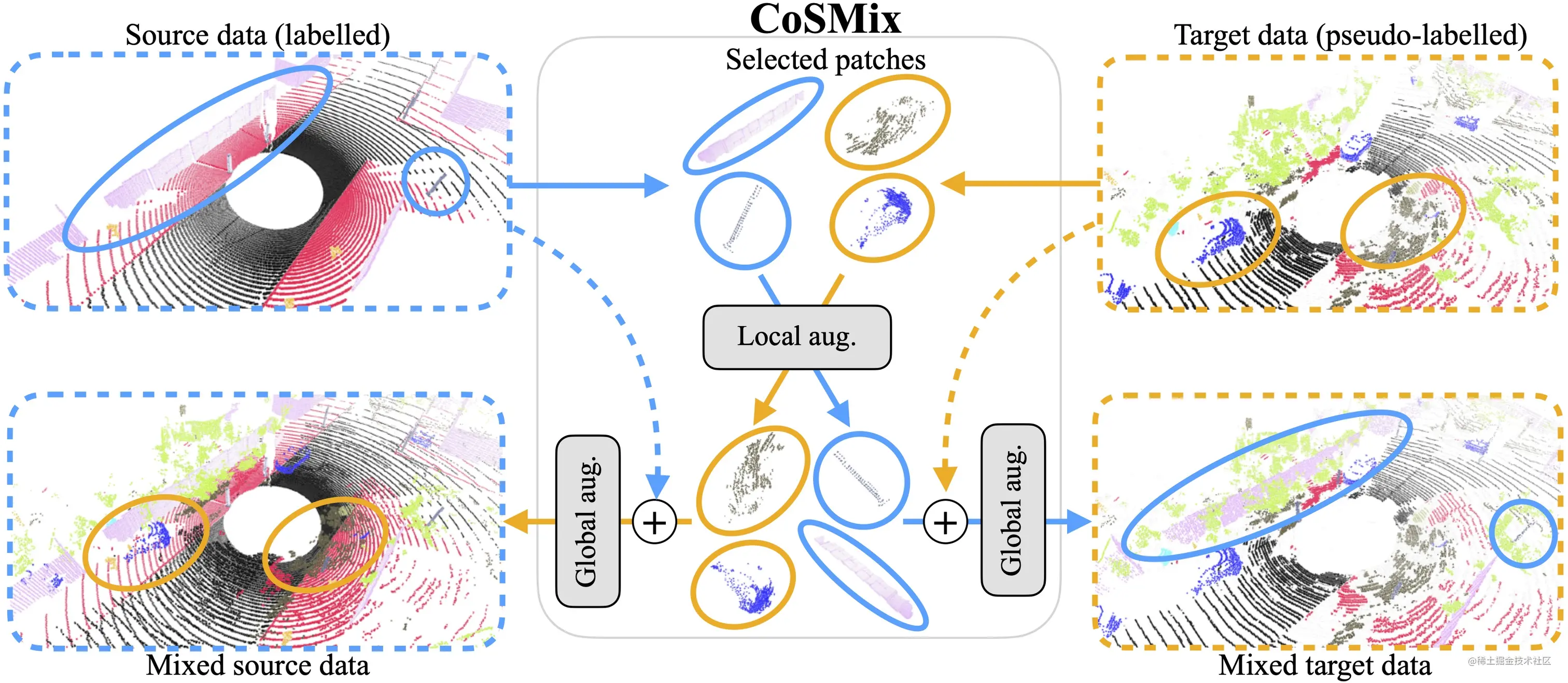
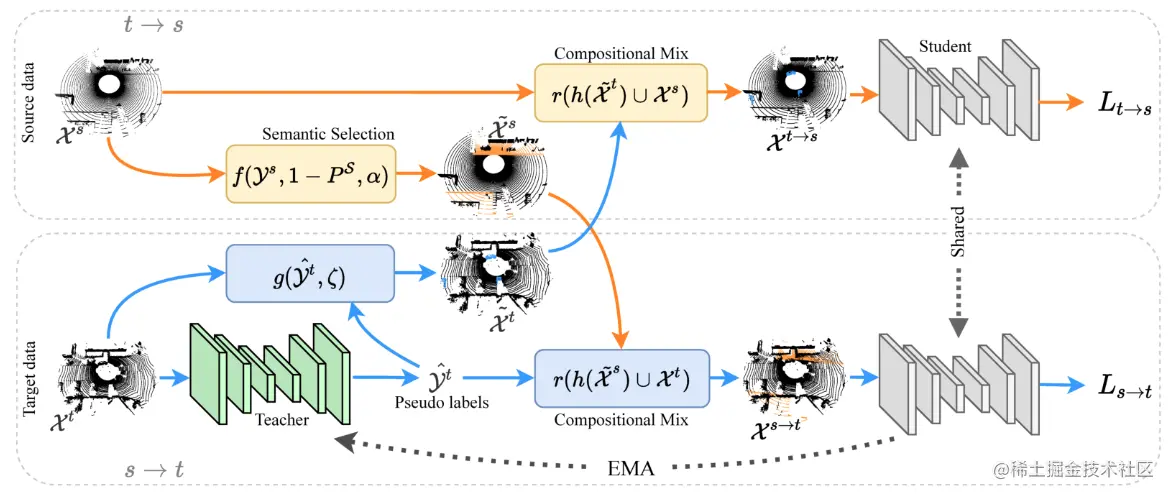
論文簡介:We propose a new approach of sample mixing for point cloud UDA, namely Compositional Semantic Mix (CoSMix), the first UDA approach for point cloud segmentation based on sample mixing./We propose a method for point cloudsUDAThe new sample mixing method,That is, compositional semantic mixing(CoSMix),This is the first point cloud segmentation based on sample blendingUDA方法.
論文摘要:3D LiDARSemantic segmentation is the foundation of autonomous driving.Several unsupervised domain adaptations for point cloud data have been proposed recently(UDA)方法,To improve model versatility for different sensors and environments.Research in the field of imagesUDAProblem researchers have shown,Sample mixing can ease field shifting.We propose a method for point cloudsUDAThe new sample mixing method,That is, compositional semantic mixing(CoSMix),This is the first point cloud segmentation based on sample blendingUDA方法.CoSMixIt consists of a two-branched symmetric network,Labeled synthetic data can be processed concurrently(源)and real-world markerless point clouds(目標).Each branch works by blending selected data from another field,And utilize the semantic information obtained from source labels and target pseudo-labels,operate in a field.We match on two large-scale datasetsCoSMix進行了評估,The results show that it outperforms state-of-the-art methods by a large margin.我們的代碼可在github.com/saltoricris…

論文時間:21 Jul 2022
所屬領域:計算機視覺
對應任務:Image Classification,Knowledge Distillation,圖像分類,知識蒸餾
論文地址:arxiv.org/abs/2207.10…
代碼實現:github.com/microsoft/c…
論文作者:Kan Wu, Jinnian Zhang, Houwen Peng, Mengchen Liu, Bin Xiao, Jianlong Fu, Lu Yuan
論文簡介:It achieves a top-1 accuracy of 84. 8% on ImageNet-1k with only 21M parameters, being comparable to Swin-B pretrained on ImageNet-21k while using 4. 2 times fewer parameters./它在ImageNet-1k上達到了84.8%的最高准確率.8%,與在ImageNet-21k上預訓練的Swin-B相當,And less parameters are used4.2倍.
論文摘要:視覺transformer(ViT)due to its remarkable model capability,It has attracted a lot of attention recently in the field of computer vision.然而,大多數流行的ViTThe model has a large number of parameters,Limiting their applicability on resource-constrained devices.為了緩解這個問題,我們提出了TinyViT,A new tiny and efficient small visiontransformer系列,Pre-training on large-scale datasets with our proposed fast distillation framework.The core idea is to transfer knowledge from large pretrained models to small ones,At the same time enabling small models to reap the benefits of large-scale pre-trained data.更具體地說,We apply distillation for knowledge transfer during pre-training.The log of the large teacher model is sparse and stored on disk ahead of time,to save memory cost and computational overhead.little studenttransformerAutomatic downscaling from large pretrained models under computational and parameter constraints.綜合實驗證明了TinyViT的功效.它在ImageNet-1k上僅用21M的參數就達到了84.8%的最高准確率,與在ImageNet-21k上預訓練的Swin-B相當,And less parameters are used4.2倍.此外,提高圖像分辨率,TinyViT可以達到86.5%的准確率,略好於Swin-L,而只使用11%的參數.最後但同樣重要的是,我們證明了TinyViTGood transfer ability in various downstream tasks.代碼和模型可在github.com/microsoft/C…
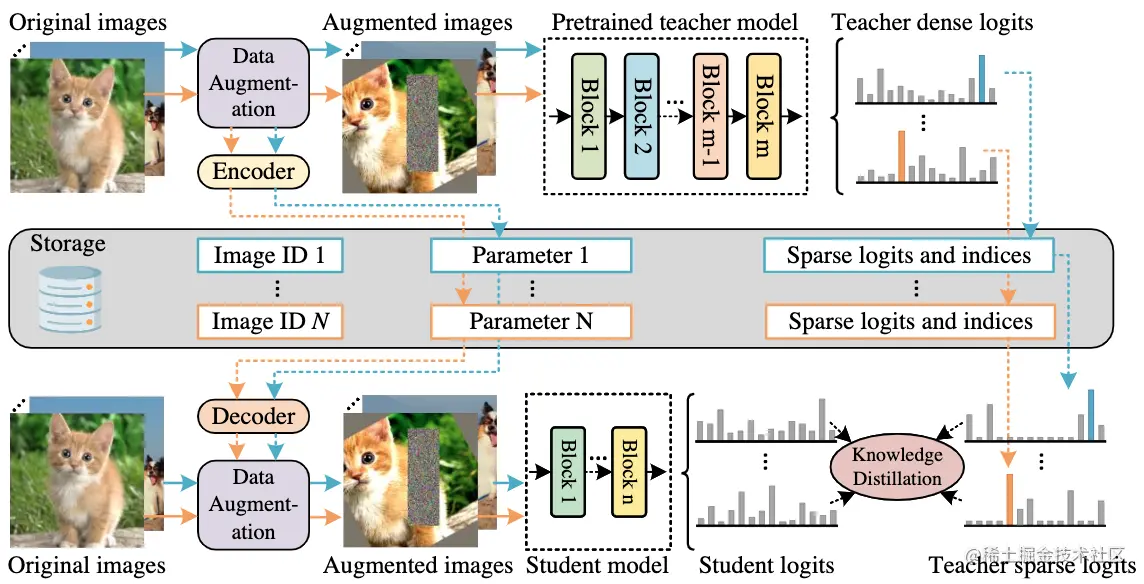
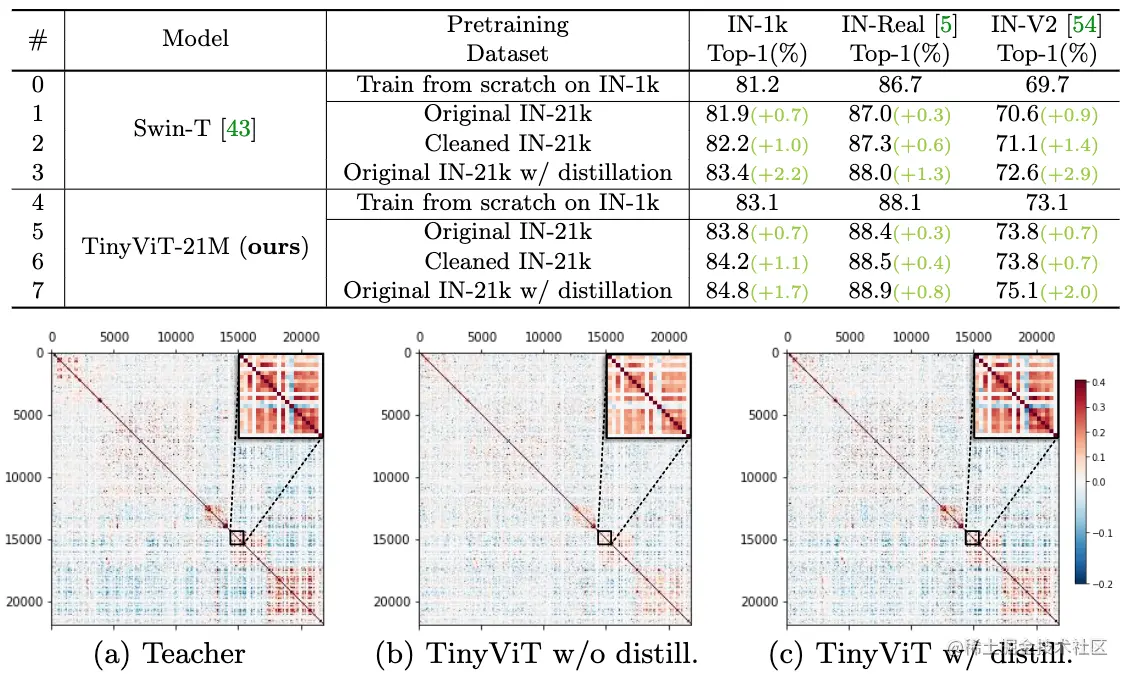
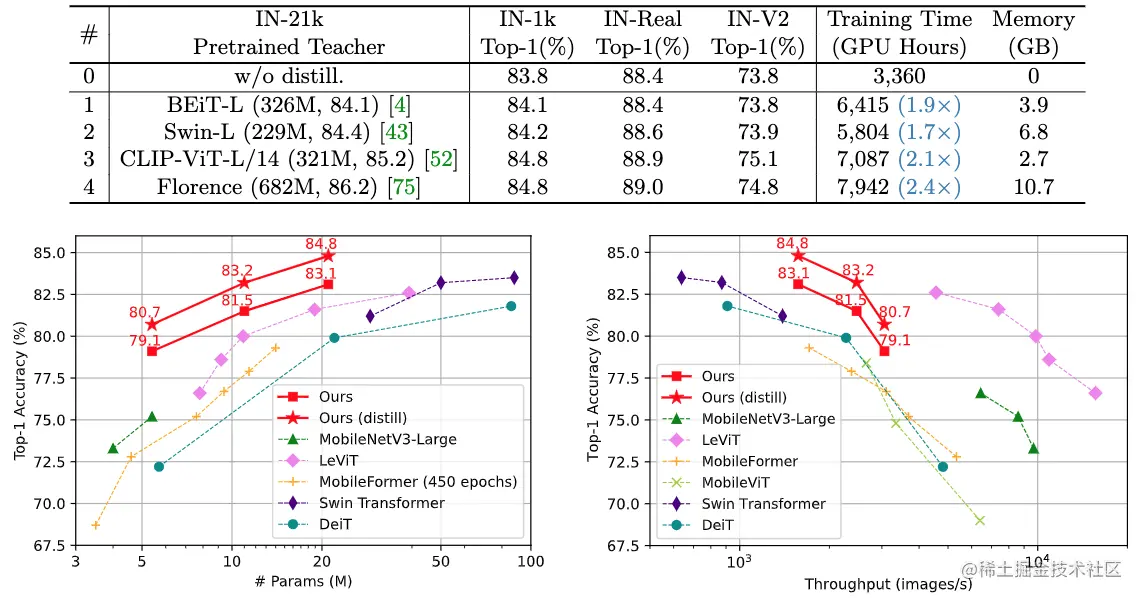
論文時間:16 Jul 2022
所屬領域:計算機視覺
對應任務:目標檢測
論文地址:arxiv.org/abs/2207.07…
代碼實現:github.com/charlespika…
論文作者:Zhenchao Jin, Dongdong Yu, Luchuan Song, Zehuan Yuan, Lequan Yu
論文簡介:Feature pyramid network (FPN) is one of the key components for object detectors./特征金字塔網絡(FPN)is one of the key components of object detectors.
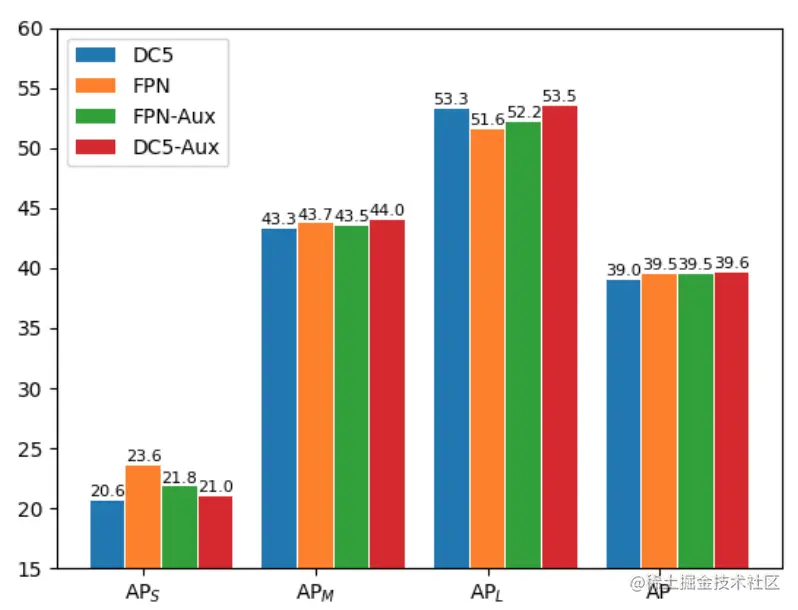
論文摘要:特征金字塔網絡(FPN)is one of the key components of object detectors.然而,對於研究人員來說,There is a longstanding confusion,即引入FPN後,The detection performance of large-scale objects is often suppressed.為此,This paper first revisits in the detection frameworkFPN,And revealed from an optimization point of viewFPNThe essence of success.然後,我們指出,The performance degradation for large-scale objects is due to consolidationFPNAn inappropriate back-propagation path is then generated.This leaves each level of the backbone network only capable of viewing objects within a certain size range.基於這些分析,We propose two feasible strategies,so that each level of backbone network can be observed based onFPNto detect all objects in the frame.具體來說,One is to introduce auxiliary objective function,Make each backbone layer directly receive back-propagation signals of objects of various scales during training.The other is to build a feature pyramid in a more reasonable way,Avoid unreasonable backpropagation paths.在COCOExtensive experiments on benchmarks validate the soundness of our analysis and the effectiveness of our approach.without any fancy tricks,We demonstrate that our method achieves solid improvements on various detection frameworks(超過2%):單階段、雙階段、基於錨、Anchorless and basedtransformer的檢測.
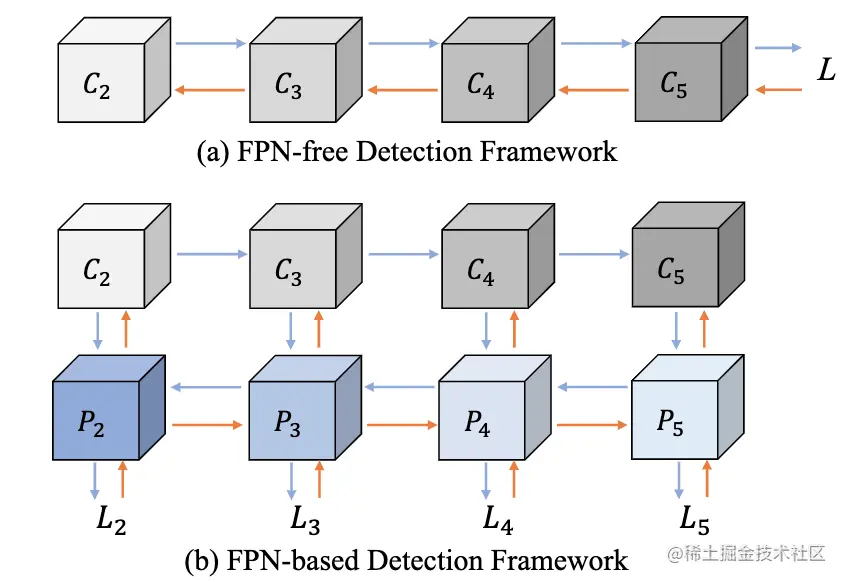
我們是 ShowMeAI,致力於傳播AI優質內容,分享行業解決方案,用知識加速每一次技術成長!點擊查看 歷史文章列表,在公眾號內訂閱話題 #ShowMeAI資訊日報,可接收每日最新推送.點擊 專題合輯&電子月刊 快速浏覽各專題全集.