應用背景:在正式開始文章之前,先闡述一下項目的應用背景——項目需要對已有的電子檔案數據進行“大數據”處理和呈現,但是由於之前進行檔案電子化時都是以掃描文件的圖像格式存儲在硬盤上(准確來說是電子化的檔案,不是數字化的檔案),且文檔的命名是00100001.jpg等完全與檔案內容無關的數字格式。為了對這些檔案文件進行數字化,首先就需要對檔案內容進行OCR識別,這樣才能為將來的檔案大數據處理奠定基礎,例如基於內容的檢索、分詞和詞頻統計、添加標簽、檔案數據的可視化呈現等操作。同時,由於檔案的敏感性和保密性原因,不能利用百度或騰訊之類的在線上傳類OCR應用,只能選擇不聯網的離線實現的OCR方式。另外,為了與現有的大數據系統便於集成,需要將上述的OCR功能做成命令行的方式;最後,現有的大數據系統是基於centOS7系統,所以需要基於Linux平台實現OCR功能。
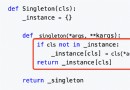
言歸正傳,經過簡單的調研,發現基於Python可以實現上述目標,共有3種途徑:一個是大名鼎鼎Google的tesseract-ocr(資源我都放在百度網盤上了,需要的可以自取,鏈接:https://pan.baidu.com/s/1Z2Lq2nEfqIrNjvfn4ziB3A?pwd=7777 ),但是很不幸,與Google的聲名在外相比,tesseract的中文OCR識別效果在我測試的幾種開源庫中是最差的,基本上相當於是Adobe Acrobat上面自帶的OCR那種水平,而且需要先安裝tesseract-ocr-w64-setup-v5.0.0.20211201.exe,然後再pip install pytesseract才能使用,而項目需要在Linux平台上實現,所以Pass!另一個是百度的飛槳PaddleOCR,百度的人工智能做的不錯,飛槳的OCR功能也很強大,但是感覺相對於一個簡單的OCR文字識別來說,百度的飛槳系統好像太大了(其實就是我有點兒懶不想預熱太久而想快速上手),有點兒殺雞用牛刀的感覺。最終我還是選擇了一個在GitHub上星星最多的easyOCR(資源我都放在百度網盤上了,需要的可以自取,鏈接:百度網盤 請輸入提取碼 ),簡約而不簡單,上手極快,大約只花了半個小時就可以快速實現自己的離線OCR識別了!很快就寫出了第一個版本的OCR命令行式程序,也就是下面的第一個版本,包括注釋在內僅三十多行:
#!/home/super/miniconda3/bin/python
#encoding=utf-8
#命令行模式下全文ocr識別,命令格式為:python imgs2txts.py 文件1.jpg 文件2.jpg 文件3.jpg ... ---> 文件.txt
#語言庫目錄為home下的固定目錄: /home/langdata
import sys
import os
import easyocr
ocrreader=easyocr.Reader(['ch_sim', 'en'], model_storage_directory=r'/home/langdata')#Linux
#ocrreader=easyocr.Reader(['ch_sim', 'en'], model_storage_directory=r'E:\WorkDir\ocr\EasyOCR\langdata')#Windows
threshold=0.1#默認阈值
for i in range(1,len(sys.argv)):#獲取命令行參數:argv[0]表示可執行文件本身
imgfile=sys.argv[i]#待識別文件名
imgfilext=os.path.splitext(imgfile)[-1]#文件後綴名
if imgfilext.upper() not in ['.JPG','.JPEG','.PNG','.BMP']:#轉換為大寫後再比對
print('\t', imgfile, ' 不是有效圖片格式(jpg/jpeg/png/bmp)!')
continue
result = ocrreader.readtext(imgfile)
paper=''
for w in result:
if w[2]>threshold:#設置一定的置信度阈值
paper = paper+w[1]
paper.replace(' ','').replace('_','').replace('^','').replace('~','').replace('`','').replace('&','')#刪除無效數據
#記錄當前文件的識別結果,保存為同名的txt文件
newfname=os.path.splitext(imgfile)[0]+'.txt'#與原文件同名的txt文件(包括目錄)
#newfname=os.path.splitext(imgfile)[0].split('/')[-1].split('\\')[-1]+'.txt'#與原文件同名的txt文件(不包括目錄,僅文件名)
try:
with open(newfname, 'w') as txtfile:
txtfile.write(paper)
except(Exception) as e:
print('\t', newfname, ' OCR Error: ', e)#輸出異常錯誤
continue
簡單說明一下:
第1行的
#!/home/super/miniconda3/bin/python不是注釋,而是在Linux系統中起作用的命令行,有了這一句,在命令行中運行這個OCR時就可以省略掉python這個“單詞”!假如把上述的python程序存儲為img2txt.py文件,而待識別的圖片為001.jpg和002.jpg,那麼就可以在命令行中輸入:
python ./img2txt.py 001.jpg 002.jpg即可在同目錄下得到001.txt和002.txt文件了。在第1句添加#!開頭的那句話以後,在命令行中僅僅輸入:
./img2txt.py 001.jpg 002.jpg即可達到相同的效果!注意:img2txt.py文件前面表述路徑的./不可省略,不然,系統會提示img2txt.py不是系統命令而出錯。
當然,在利用conda產生多個虛擬python環境後,系統中可能存在多個python,甚至版本各不相同,這時就要輸入正確的python解釋器路徑了,可以利用
whereis python命令來查看所有的python解釋器供參考!
第2行是編碼聲明,再後面就是導入包和導入語言包,語言包如果沒有利用model_storage_directory選項顯式的給出其路徑,將會進行聯網查詢,由於我這裡需要實現的是離線的OCR識別,所以需要事先將語言包下載下來,下載語言包還比較困難,我都在百度網盤鏈接中給出了,可供直接下載使用;這裡我采用固定路徑的方式,將語言包放在home根目錄下的langdata文件夾下,拷貝時需要sudo權限,大家也可以放在其他路徑下。
可以看見,目前這個版本十分的簡單,也基本實現了所需的功能!但是,後面我還是進行了四五個版本的升級改進,下一個版本就是命令行中支持文件夾,當判斷是文件夾後就對文件夾中的文件進行遍歷,當是圖像類型文件時就進行OCR識別,預知後事如何,且看下回分解!