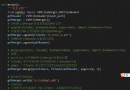
說明: 如果需要匹配的字符是正則表達式中的特殊字符,那麼可以使用\進行轉義處理,例如想匹配小數點可以寫成\.就可以了,因為直接寫.會匹配任意字符;同理,想匹配圓括號必須寫成\(和\),否則圓括號被視為正則表達式中的分組。
Python提供了re模塊來支持正則表達式相關操作,下面是re模塊中的核心函數。
說明: 上面提到的re模塊中的這些函數,實際開發中也可以用正則表達式對象的方法替代對這些函數的使用,如果一個正則表達式需要重復的使用,那麼先通過compile函數編譯正則表達式並創建出正則表達式對象無疑是更為明智的選擇。
""" 驗證輸入用戶名和QQ號是否有效並給出對應的提示信息 要求: 用戶名必須由字母、數字或下劃線構成且長度在6~20個字符之間 QQ號是5~12的數字且首位不能為0 """
import re
def main():
username = input('請輸入用戶名: ')
qq = input('請輸入QQ號: ')
m1 = re.match(r'^[0-9a-zA-Z_]{6,20}$', username)
print(m1.group()) # 打印出匹配出的值
if not m1:
print('請輸入有效的用戶名.')
m2 = re.match(r'^[1-9]\d{4,11}$', qq)
if not m2:
print('請輸入有效的QQ號.')
if m1 and m2:
print('你輸入的信息是有效的!')
if __name__ == '__main__':
main()
import re
def main():
# 創建正則表達式對象 使用了前瞻和回顧來保證手機號前後不應該出現數字
pattern = re.compile(r'(?<=\D)(1[38]\d{9}|14[57]\d{8}|15[0-35-9]\d{8}|17[678]\d{8})(?=\D)')
sentence = ''' 重要的事情說8130123456789遍,我的手機號是13512346789這個靓號, 不是15600998765,也是110或119,王大錘的手機號才是15600998765。 '''
# 查找所有匹配並保存到一個列表中
mylist = re.findall(pattern, sentence)
print(mylist)
print('--------華麗的分隔線--------')
# 通過迭代器取出匹配對象並獲得匹配的內容
for temp in pattern.finditer(sentence):
print(temp.group(1))
print('--------華麗的分隔線--------')
# 通過search函數指定搜索位置找出所有匹配
m = pattern.search(sentence)
while m:
print(m.group())
m = pattern.search(sentence, m.end())
if __name__ == '__main__':
main()
""" 不良內容過濾 """
import re
def main():
sentence = '你丫是傻叉嗎? 我操你大爺的. Fuck you.'
purified = re.sub('[操肏艹]|fuck|shit|傻[比屄逼叉缺吊屌]|煞筆',
'*', sentence, flags=re.IGNORECASE)
print(purified)
if __name__ == '__main__':
main()
""" 字符串是否含有某些字符 """
files = ["str", 'str1', 'str2', 'str1.str2']
for file in files:
r = re.search(r'str1|str2', file)
if r:
print(f'{
file} OK')
else:
print(f'{
file} not OK')
import re
def fun(value:str) ->str:
if value is None:
res = None
else:
value = re.sub('[,\s]','',str(value)) # 去除千分位的逗號和空白符號
# pattern = re.compile('-?\d+\.?\d*[萬元]{,2}') # 最重要的表達式,慢慢理解吧 -?表示適配負數
pattern = re.compile('[-\d\.萬元]*') # 粗略些的表達式
result = re.findall(pattern, value)
if result:
val = result[0]
if val.isdigit() or re.sub('[-.]', '', val).isdigit():
res = val
elif re.search("萬元|萬", val):
val = re.sub("萬元|元", '', val)
res = str(float(val) * 10000)
elif re.search("元", val):
res = re.sub("萬", '', val)
else:
res = '0'
else:
res = "0"
return res
pattern = re.compile(‘-?\d+.?\d+[萬元]{,2}’) 解析如下:
-?支持查找負數\d+數據的整數部分,至少1位數據\.?轉義後的小數點, 0或1個\d*數據的小數部分,[萬元]{,2}數據的單位, 最多匹配2個, 這裡僅支持萬或萬元和元轉換為元,其它單位再補充吧
匹配輸入串A: 1001000100
貪婪匹配:
使用 1.1 將會匹配到10010001
非貪婪匹配:
使用 1.?1 將會匹配到1001
主要區別在於是否加
?
當加了?緊隨任何其他限定符之後時,匹配模式是"非貪心的"。
“非貪心的"模式匹配搜索到的、盡可能短的字符串,
而默認的"貪心的"模式匹配搜索到的、盡可能長的字符串