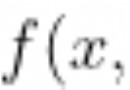數據分析中離不開對數據的相關性分析,並且需要把這些相關性進行可視化(繪圖),以方便人們對各種特征屬性之間呈現出來的相關性有更直接、清晰的感知和理解,提升數據的價值和數據挖掘的效益。本文以“鸢尾花數據集”為基礎,主要關注於各種關系圖的繪制,以及統計分析的數據可視化,提供和展示了12種關系圖及5種統計分析圖和回歸圖的方法(詳見以下目錄)。
由於從sklearn中獲取的“鸢尾花”數據集中,目標值(iris.target)是“0”和“1”,這種類型的數據方便實現“機器學習”的建模,但是在數據繪圖中不利於理解,因此我們會把數據集中的目標值與鸢尾花的品種(species)進行關聯,轉換為新的數據集,以獲取更好的可視化結果。
1. 箱型圖
2. 小提琴圖 -- violinplot()
3. 分簇散點圖
4. 散點圖
5. 散點矩陣圖
6. 直方圖矩陣
7. 密度圖
8. 直方密度線圖
9. 熱力圖
10. 平行坐標圖
11. 多變量聯合分布圖 -- pairplot()函數
12. 多組分類重疊密度圖 -- joy plot() 函數
1. 檢驗是否符合正態分布 -- p_test, Skewness(), Kurtosis()的計算
2. 正態概率分布圖
3. 正態分布圖 -- norm.pdf() 函數的計算與繪制
4. 回歸圖 -- lmplot() 函數
5. 回歸圖 -- regplot() 函數
**鸢尾花數據集(Iris數據集)**是一類多重變量分析的數據集。數據集包含150個數據樣本,分為3類,每類50個數據,每個數據包含4個屬性。通過花萼長度,花萼寬度,花瓣長度,花瓣寬度4個屬性可以預測鸢尾花卉屬於(Setosa,Versicolour,Virginica)三個種類中的哪一類。原數據集的目標值(iris.target)是“0”和“1”,但在數據可視化展示的時候,為了更清晰容易地理解數據的分類,我們需要將數據集中的目標值與鸢尾花的品種連接起來,即:把數據集中的編號"iris.target"與鸢尾花的品種連接,轉換為新的數據集。
import numpy as np
import pandas as pd
import sklearn
from sklearn import datasets
# 從sklearn中獲取鸢尾花數據集,並轉換為DataFrame
iris = datasets.load_iris()
dataset = pd.DataFrame(iris.data, columns=iris.feature_names)
dataset["target"]= iris.target
# 對數據集中的目標值進行鸢尾花品種的轉換
dict_species = dict(zip(np.array([0, 1, 2]), iris.target_names,))
dict_species
dataset["speices"] = dataset["target"].map(dict_species)
# 將整理好的數據集以csv文件的形式保存下來,也可以保存為Excel 文件
outputfile = r"d:/iris.csv"
dataset.to_csv(outputfile)
dataset.info()
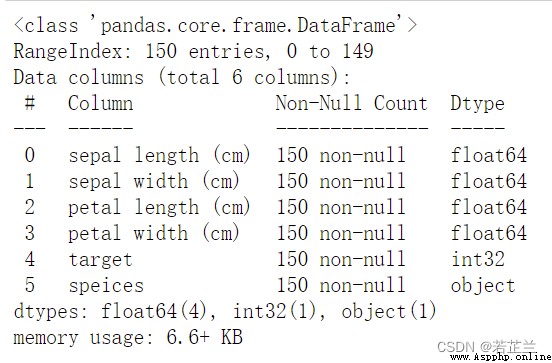
保存下來的csv文件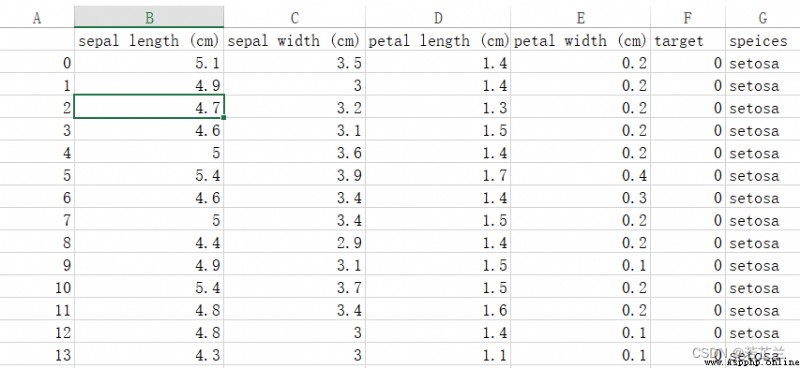
1. 箱型圖
# 1.1 繪制箱型圖 -- 根據不同類別的數據繪制箱型圖
data = dataset.drop(columns=["species"])
plt.boxplot(data, labels=data.columns, showmeans=True)
plt.show()

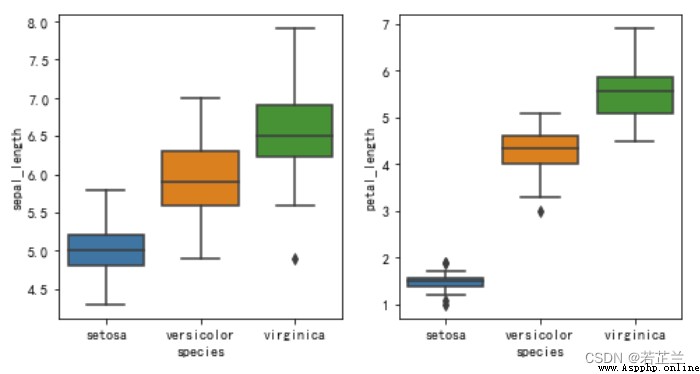
# 1. 2 繪制箱型圖 -- 按鸢尾花的品種展示花萼長度和花瓣長度
fig, axes = plt.subplots(1, 2, figsize=(10, 5))
sns.boxplot(x="species", y="sepal_length", data=dataset, ax=axes[0])
sns.boxplot(x="species", y="petal_length", data=dataset, ax=axes[1])
plt.show()
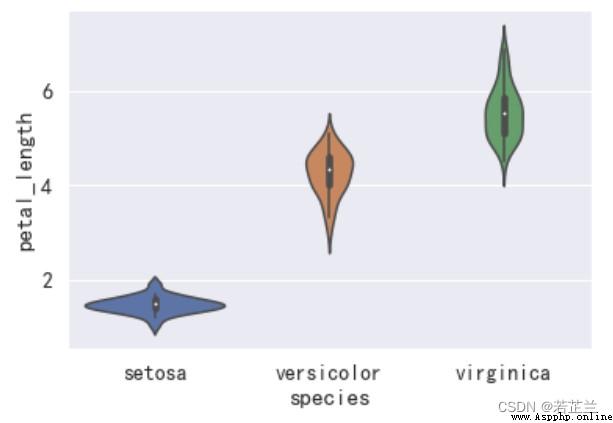
2. 小提琴圖 – violinplot() 函數
# 繪制小提琴圖
import seaborn as sns
sns.violinplot(x="species", y="petal_length", data=dataset)
plt.show()
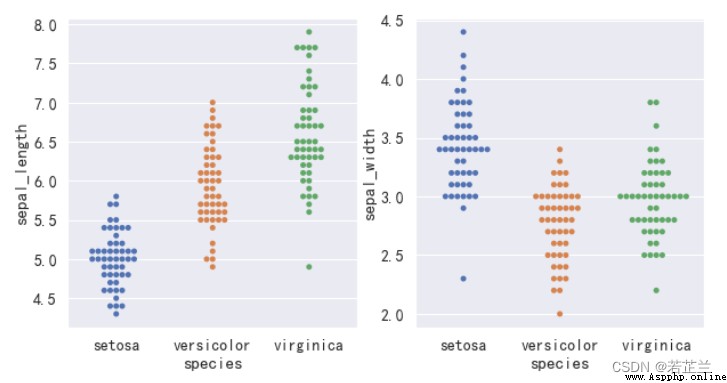
3. 分簇散點圖
# 分簇散點圖
fig, axes = plt.subplots(1, 2, figsize=(10, 5))
sns.swarmplot(x="species", y="sepal_length", data=dataset, ax=axes[0])
sns.swarmplot(x="species", y="sepal_width", data=dataset, ax=axes[1])
plt.show()
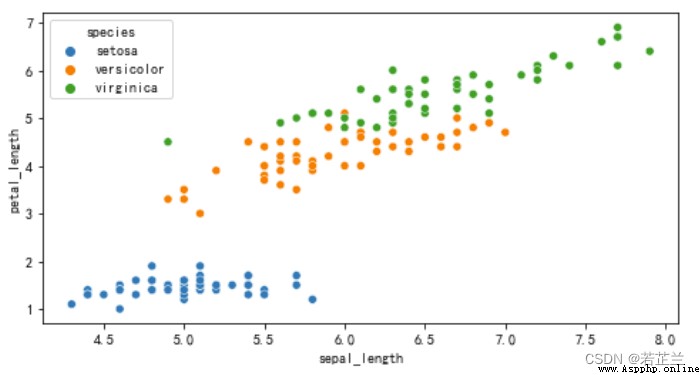
4. 散點圖
# 繪制散點圖
fig = plt.subplots(1, 1, figsize=(8, 4))
sns.scatterplot(x="sepal_length", y="petal_length", hue="species", data=dataset)
plt.show()
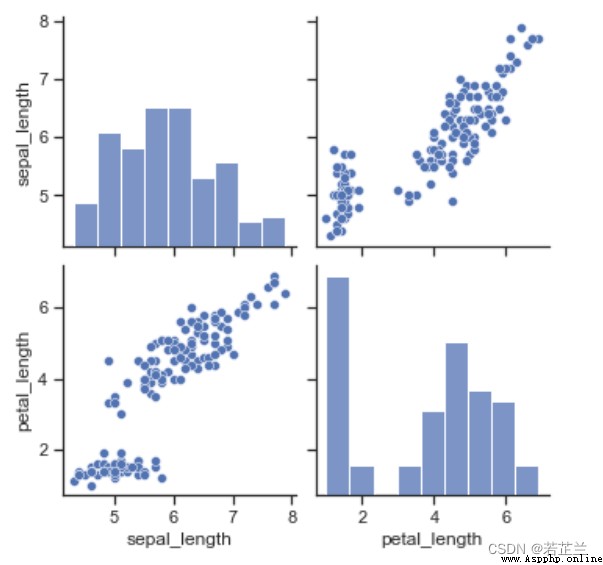
5. 散點矩陣圖
# 繪制散點圖矩陣示例
import seaborn as sns
sns.set()
sns.pairplot(dataset, vars=["sepal_length", "petal_length"])
plt.show()
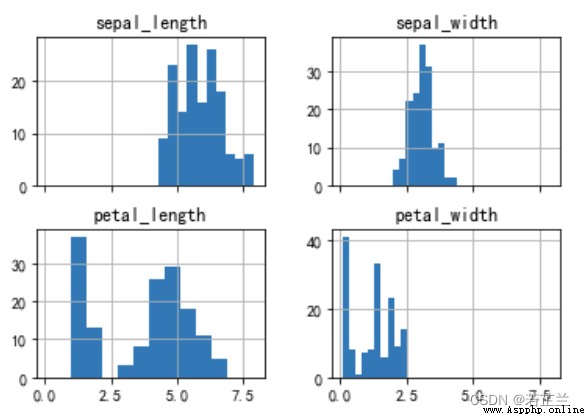
6. 直方圖矩陣
# 繪制直方圖矩陣 -- 對數據集中的所有特征屬性繪制直方圖
dataset.hist(sharex=True)
plt.show()
7. 繪制密度圖
# 繪制密度圖 -- 整個數據集
dataset.plot(kind="kde")
plt.show()
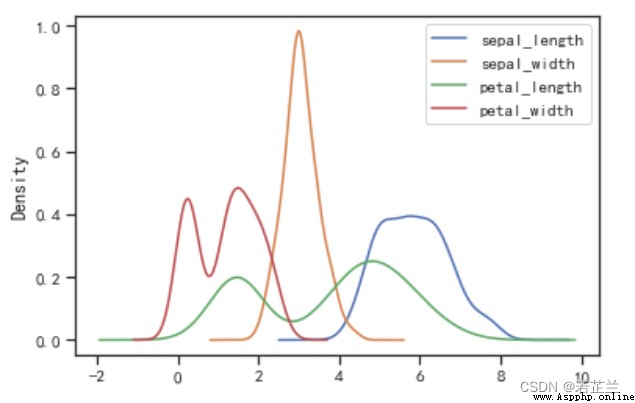
8. 直方密度線圖
# 繪制直方密度線圖 -- 並按不同品種分別呈現sepal_length數據的分布情況
import seaborn as sns
# kde: 是否顯示數據分布曲線,默認為False
sns.displot(x="sepal_length", data=dataset, bins=20, kde=True, hue="species")
plt.show()
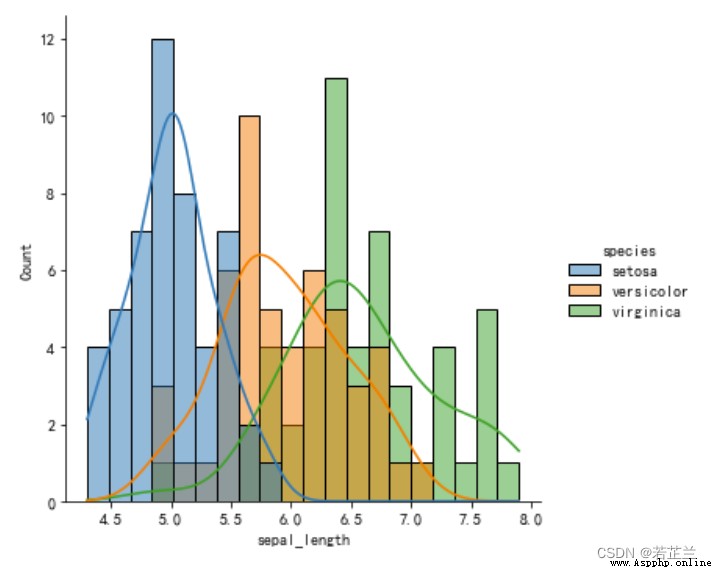
9. 熱力圖
# 繪制熱力圖
corrmat = dataset.corr()
k = 4
cols = corrmat.nlargest(k, "sepal_length")["sepal_length"].index
cm = np.corrcoef(dataset[cols].values.T)
sns.set(font_scale=1.25)
hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt=".2f", annot_kws={"size": 10},
yticklabels=cols.values, xticklabels=cols.values)
plt.show()
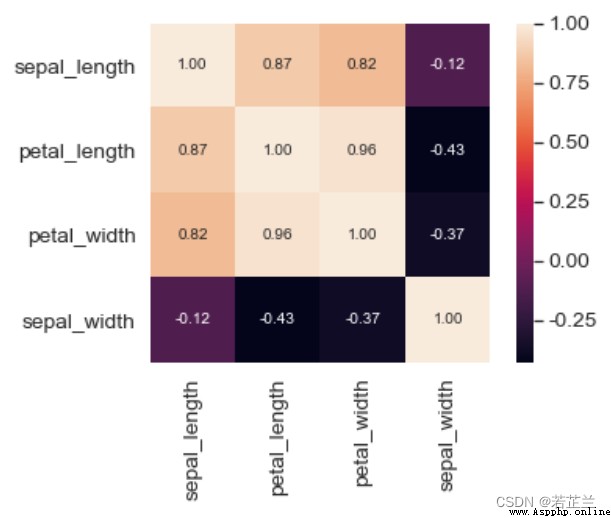
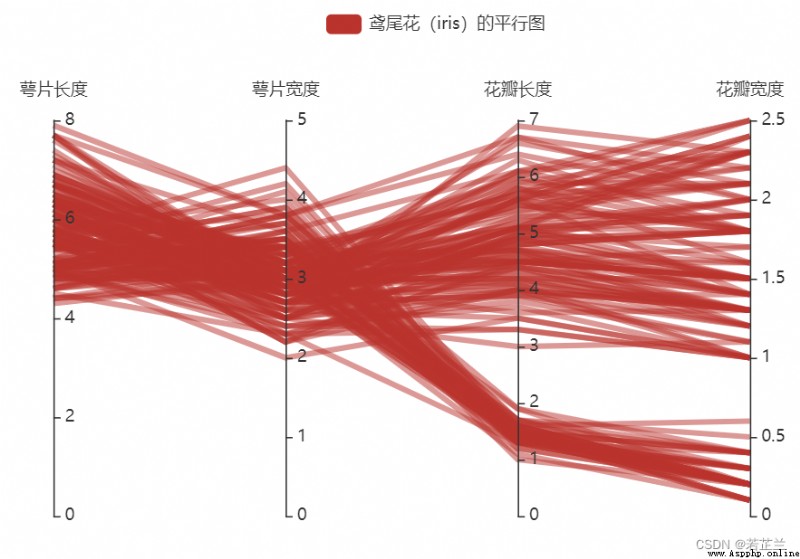
10. 平行坐標圖
平行坐標圖(Paralllel Coordinates Plot) 是對於具有多個屬性的一種可視化方法,可解決在維度增加時,散點矩陣變得不太有效的問題。在平行坐標圖中,數據集的一行數據在平行坐標圖中用一條折線表示,縱向是屬性,橫向是屬性類別。安裝方法:pip install pyecharts
# 繪制數據的平行坐標圖示例
from pyecharts.charts import Parallel
import pyecharts.options as opts
import seaborn as sns
import numpy as np
data_ = np.array(dataset[["sepal_length", "sepal_width", "petal_length", "petal_width"]]).tolist()
parallel_axis = [{"dim": 0, "name": "萼片長度"},
{"dim": 1, "name": "萼片寬度"},
{"dim": 2, "name": "花瓣長度"},
{"dim": 3, "name": "花瓣寬度"}]
parallel = Parallel(init_opts=opts.InitOpts(width="600px", height="400px"))
parallel.add_schema(schema=parallel_axis)
parallel.add("鸢尾花(iris)的平行圖", data=data_, linestyle_opts=opts.LineStyleOpts(width=4, opacity=0.5))
parallel.render_notebook()
11. 多變量聯合分布圖 – pairplot() 函數
11.1 以散點圖的形式循環展示數據屬性之間的相關性
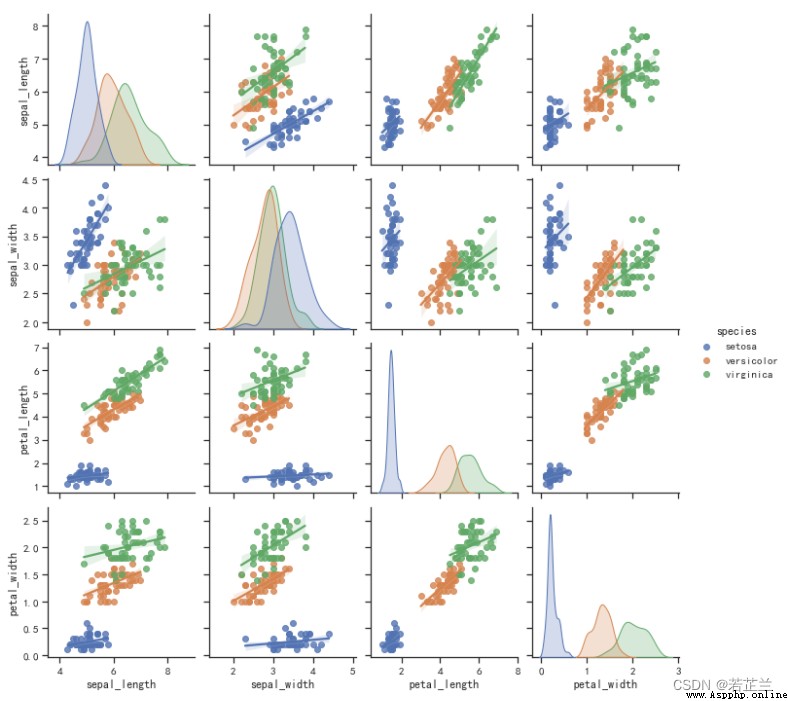
# 11.1:繪制以散點圖的形式展示數據屬性之間的相關性
import seaborn as sns
plt.figure(figsize=(10, 8), dpi=80)
plot_setting = dict(s=80, edgecolor="white", linewidth=2.5)
sns.pairplot(dataset, kind="scatter", hue="species", plot_kws=plot_setting)
plt.show()
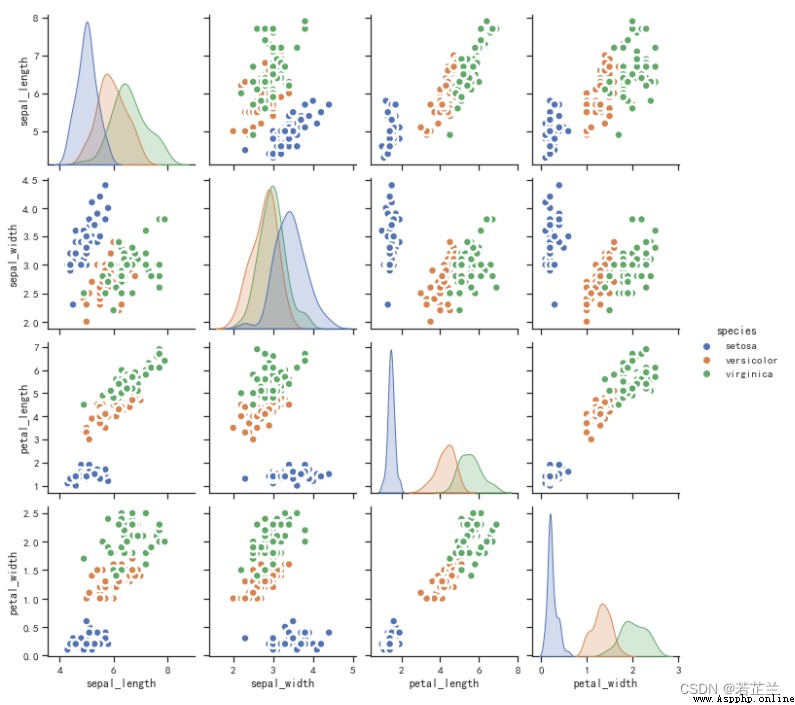
11.2 以回歸線的方式循環展示數據屬性之間的相關性
# 11.2:繪制以回歸線的方式循環展示數據屬性之間的相關性
plt.figure(figsize=(10, 8), dpi=80)
sns.pairplot(dataset, kind="reg", hue="species")
plt.show()
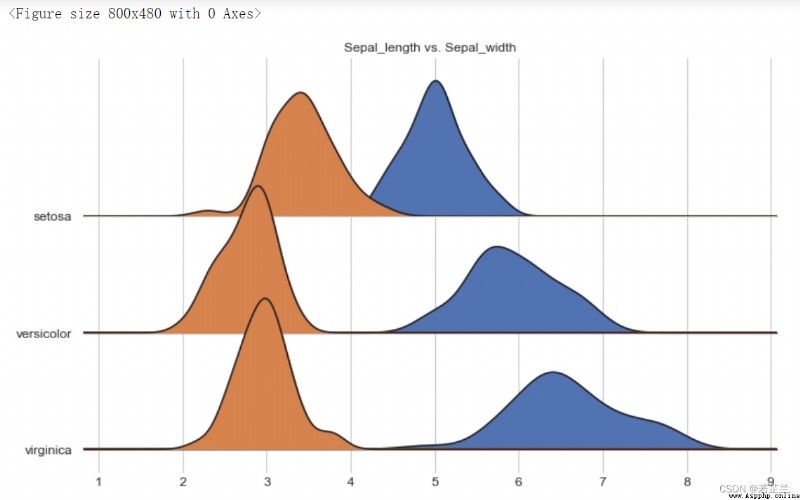
12. 多組分類重疊密度圖 – Joyplot() 函數
多組分類重疊密度圖(Joy plot)又稱為“峰巒圖”,是一種可視化大量分組數據的方法,通過部分堆疊、重疊的密度圖來展示不同類別的密度曲線折疊狀況,直觀地在一個維度上呈現和比較不同組別數據的分布。
安裝方法:pip install joyplot
# Joy Plot
import joypy
plt.figure(figsize=(10, 6), dpi=80)
fig, axes = joypy.joyplot(dataset, column=["sepal_length", "sepal_width"], by="species", figsize=(10, 6),
grid=True, title="Sepal_length vs. Sepal_width")
plt.show()
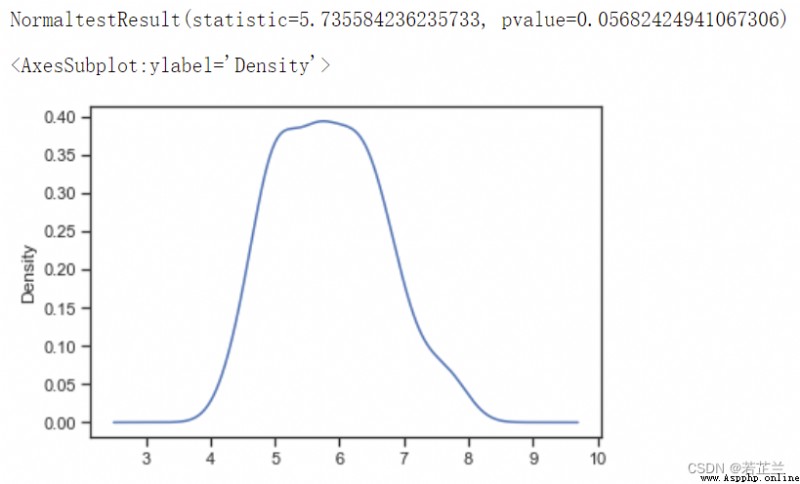
1. 檢驗是否符合正態分布 – p_test, Skewness(), Kurtosis()的計算
# 1.1 檢查是否屬於正態分布及偏度(Skewness)和峰度(Kurtosis)
print("偏度(Skewness): %f" % dataset["sepal_length"].skew())
print("峰度(Kurtosis): %f" % dataset["sepal_length"].kurt())
# 在統計學中,峰度(Kurtosis)衡量實數隨機變量概率分布的峰態。
# 峰度高就意味著方差增大是由低頻度的大於或小於平均值的極端差值引起的。

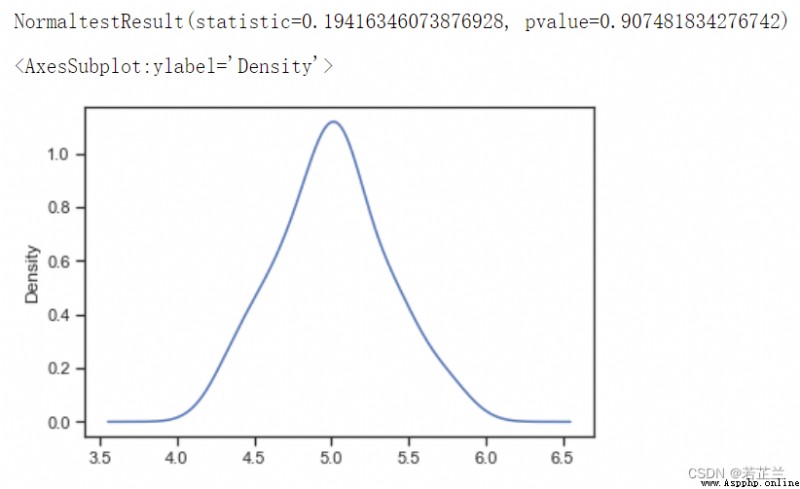
# 1.2檢驗數據的正態分布及p_test 的計算 -- 分析petal_length是否符合正態分布:
import scipy.stats as ss
p_test= np.array(dataset["sepal_length"].T)
print(ss.normaltest(p_test))
from matplotlib import pyplot as plt
p_test = pd.Series(p_test)
p_test.plot(kind="kde")
# 2.2 分析petal_length是否符合正態分布:
import scipy.stats as ss
data_ = dataset[dataset["species"] == "setosa"]
p_test= np.array(data_["sepal_length"].T)
print(ss.normaltest(p_test))
from matplotlib import pyplot as plt
p_test = pd.Series(p_test)
p_test.plot(kind="kde")
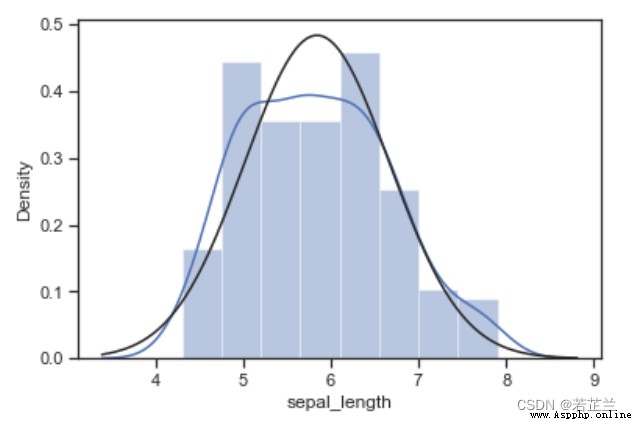
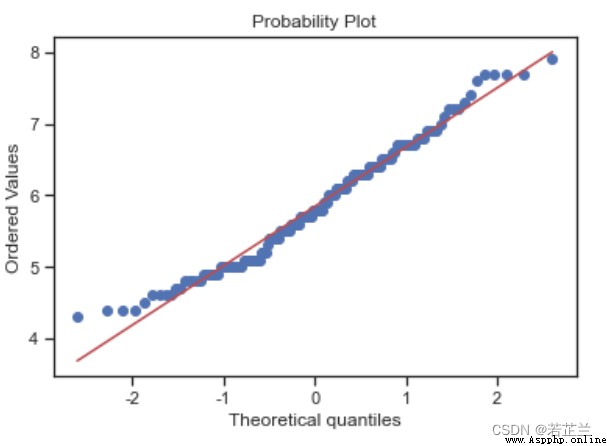
2. 正態概率分布圖
# 正態概率分布圖:-- histogram and normal probability plot
from scipy import stats
sns.distplot(dataset["sepal_length"], fit=norm)
fig = plt.figure()
res = stats.probplot(dataset["sepal_length"], plot=plt)
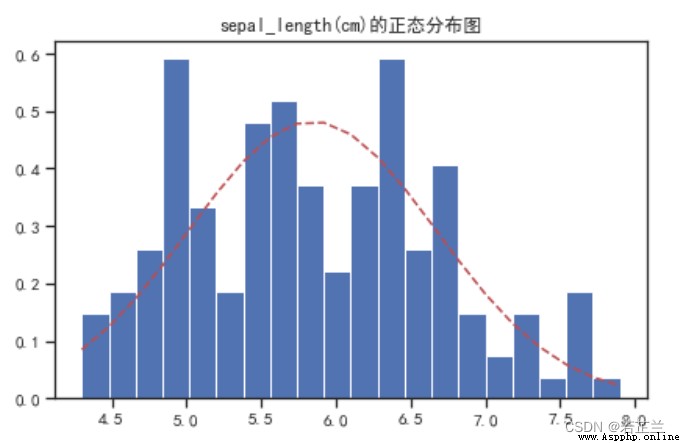
3. 正態分布圖 – norm.pdf() 函數的計算與繪制
# 3.1 繪制正態分布圖
from scipy.stats import norm
fig, axes = plt.subplots()
sigma = dataset["sepal_length"].std()
mu = dataset["sepal_length"].mean()
num_bins = 20
x = dataset["sepal_length"]
n, bins, patches = axes.hist(x, num_bins, density=1)
# 計算正態分布概率密度函數
y = norm.pdf(bins, mu, sigma)
axes.plot(bins, y, "r--")
axes.set_title("sepal_length(cm)的正態分布圖")
fig.tight_layout()
plt.show()
# 3.2 繪制正態分布圖 -- 關注於某種品種的花瓣長度的數據分析
mpl.rcParams["font.family"] = "SimHei"
data_ = dataset[dataset["species"]=="setosa"]
from scipy.stats import norm
fig, axes = plt.subplots()
sigma = data_["sepal_length"].std()
mu = data_["sepal_length"].mean()
num_bins = 20
x = data_["sepal_length"]
n, bins, patches = axes.hist(x, num_bins, density=1,color="g")
y = norm.pdf(bins, mu, sigma)
axes.plot(bins, y, "r--")
axes.set_title("Setosa: sepal_length(cm)的正態分布圖")
fig.tight_layout()
plt.show()

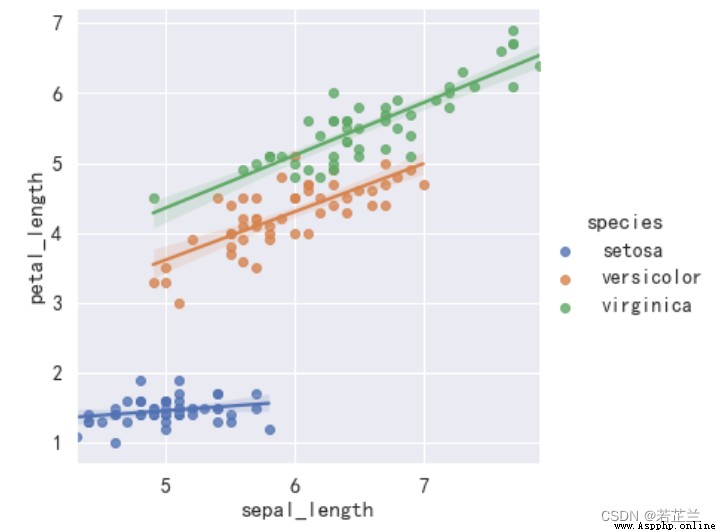
4. 回歸圖 – lmplot()函數
# 繪制回歸圖
import seaborn as sns
sns.lmplot(x="sepal_length", y="petal_length", hue="species", data=dataset)
plt.show()
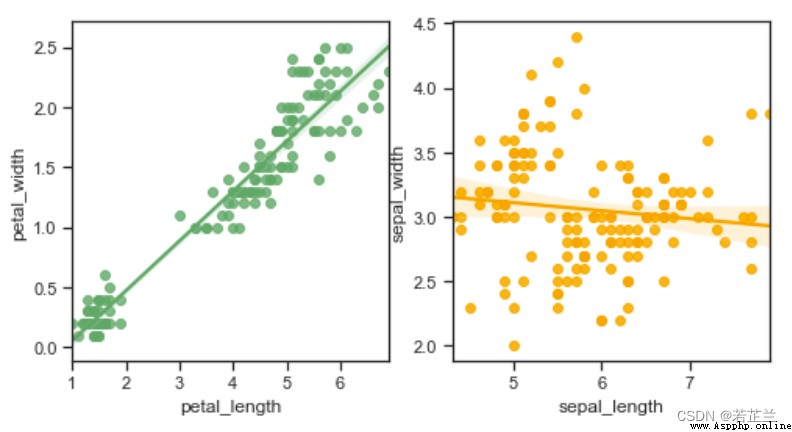
5. 回歸圖 – 使用regplot()函數
# 繪制線性回歸圖 -- 分別繪制
fig, axes = plt.subplots(1, 2, figsize=(8, 4))
sns.regplot(x="petal_length", y="petal_width", data=dataset, color="g", ax=axes[0])
sns.regplot(x="sepal_length", y="sepal_width", data=dataset, color="orange", ax=axes[1])
plt.show()
1. Joyplot() 函數的介紹
‘data:繪制數據集’
‘column’:使用data的中的有限列進行繪圖
‘by=None’:分組列
‘gird=false:添加網格線
‘xlabelsize=none x軸標簽的大小
‘ylabelsize=none y軸標簽的大小
‘xrot=none x軸刻度線標簽旋轉角度
‘yrot=none y軸刻度線標簽旋轉角度
‘hist=flase顯示直方圖
‘fade=flase如果設定的是true,則顯示漸變色
‘ylim’=‘max共享y軸的刻度
ll=‘true 曲線下的填充顏色
linecolor=‘None;曲線的顏色
blackground=none:背景顏色
overlap=1:控制重疊程度
‘title’=none 添加圖表的標題
‘colormap=none 色譜