其實Excel合並這個需求,應該是一個極為普遍的需求了。今天我們就利用Python完成“Excel合並(拆分)” 操作,具體如下:

其實完成這些操作,涉及到了太多的知識點,因此在講述上述這個知識點以前,我們要帶大家復習一些常用的知識點。
對於os模塊,我們主要講述os.walk()、os.path.join()等知識點。
對於這個知識點,我們需要說明以下幾點:
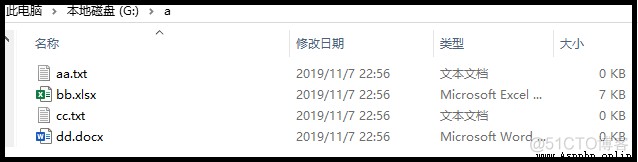
如果說,有一個如圖所示的文件夾。
利用下方的代碼,我們可以得到什麼結果呢?
pwd = "G:\\a"
print( os. walk( pwd))
for i in os. walk( pwd):
print( i)
for path, dirs, files in os. walk( pwd):
print( files)```
結果如下:
< generator object walk at 0x0000029BB5AEAB88 >
( 'G:\\a', [], [ 'aa.txt', 'bb.xlsx', 'cc.txt', 'dd.docx'])
[ 'aa.txt', 'bb.xlsx', 'cc.txt', 'dd.docx']
這個函數,主要用於將多個路徑組合後返回,超級簡單,就不做過多闡述。
path1 = 'G:\\a'
path2 = 'aa.txt'
print( os. path. join( path1, path2))
結果如下:
G:\ a\ aa. txt
由於是需要利用Pandas進行Excel的合並,因此我們要學會,如何利用Pandas進行數據的縱向合並。
我們先創建2個數據框(DataFrame):
import numpy as np
xx = np. arange( 15). reshape( 5, 3)
yy = np. arange( 1, 16). reshape( 5, 3)
xx = pd. DataFrame( xx, columns =[ "語文", "數學", "外語"])
yy = pd. DataFrame( yy, columns =[ "語文", "數學", "外語"])
print( xx)
print( yy)
效果如下:
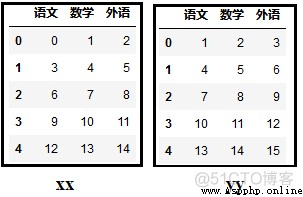
接著,可以利用Pandas中的concat()函數,完成縱向拼接的操作。
concat_list = []
concat_list. append( xx)
concat_list. append( yy)
z = pd. concat( concat_list, ignore_list = True)
print( z)
效果如下:
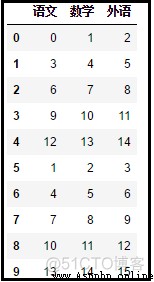
xlsxwriter模塊一般是和xlrd模塊搭配使用的,
xlsxwriter:負責寫入數據,
xlrd:負責讀取數據。
接下來,我們分別對這兩個庫的常見用法,進行介紹。
import xlsxwriter
# 這一步相當於創建了一個新的"工作簿";
# "demo.xlsx"文件不存在,表示新建"工作簿";
# "demo.xlsx"文件存在,表示新建"工作簿"覆蓋原有的"工作簿";
workbook = xlsxwriter. Workbook( "demo.xlsx")
# close是將"工作簿"保存關閉,這一步必須有,否則創建的文件無法顯示出來。
workbook. close()
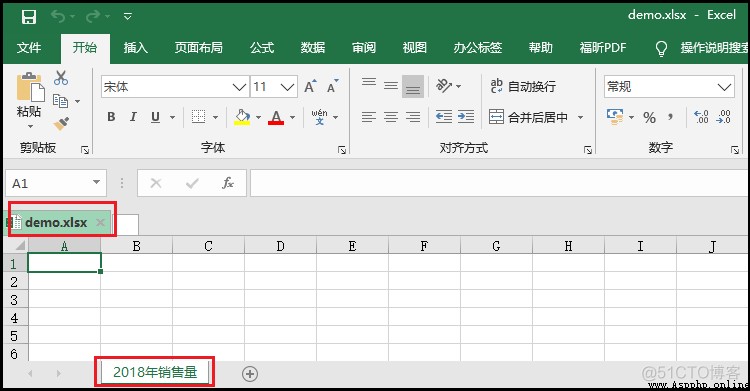
我們知道,一個Excel文件就是一個Excel工作簿,而每一個工作簿中,又有很多的“Sheet工作表”。接下來,我們如何用代碼實現這個操作呢?
import xlsxwriter
workbook = xlsxwriter. Workbook( "cc.xlsx")
worksheet = workbook. add_worksheet( "2018年銷售量")
workbook. close()
效果如下:
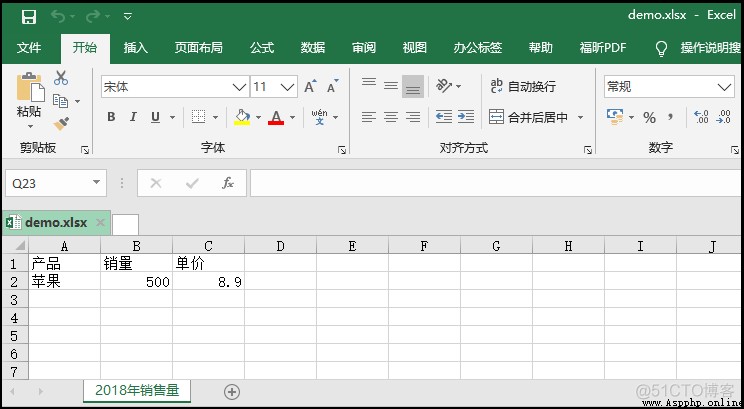
import xlsxwriter
# 創建一個名為【demo.xlsx】工作簿;
workbook = xlsxwriter. Workbook( "demo.xlsx")
# 創建一個名為【2018年銷售量】工作表;
worksheet = workbook. add_worksheet( "2018年銷售量")
# 使用write_row方法,為【2018年銷售量】工作表,添加一個表頭;
headings = [ '產品', '銷量', "單價"]
worksheet. write_row( 'A1', headings)
# 使用write方法,在【2018年銷售量】工作表中插入一條數據;
# write語法格式:worksheet.write(行,列,數據)
data = [ "蘋果", 500, 8.9]
for i in range( len( headings)):
worksheet. write( 1, i, data[ i])
workbook. close()
效果如下:
這裡有一個工作簿“test.xlsx”,該文件中有兩個“Sheet工作表”,分別命名為“2018年銷售量”、“2019年銷售量”,如圖所示。
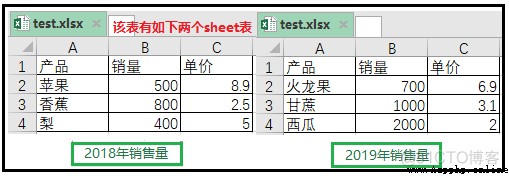
# 這裡所說的"打開"並不是實際意義上的打開,只是將該表加載到內存中打開。
# 我們並看不到"打開的這個效果"
import xlrd
file = r"G:\Jupyter\test.xlsx"
xlrd. open_workbook( file)
結果如下:
< xlrd. book. Book at 0x29bb8e4eda0 >
import xlrd
file = r"G:\Jupyter\test.xlsx"
fh = xlrd. open_workbook( file)
fh. sheet_names()
結果如下:
[ '2018年銷售量', '2019年銷售量']
import xlrd
file = r"G:\Jupyter\test.xlsx"
fh = xlrd. open_workbook( file)
fh. sheets()
結果如下:
[ < xlrd. sheet. Sheet at 0x29bb8f07a90 >, < xlrd. sheet. Sheet at 0x29bb8ef1390 >]
我們可以利用索引,獲取每一個sheet表的對象,然後可以針對每一個對象,進行操作。
fh. sheets()[ 0]
< xlrd. sheet. Sheet at 0x29bb8f07a90 >
fh. sheets()[ 1]
< xlrd. sheet. Sheet at 0x29bb8ef1390 >
import xlrd
file = r"G:\Jupyter\test.xlsx"
fh = xlrd. open_workbook( file)
fh. sheets()
fh. sheets()[ 0]. nrows # 結果是:4
fh. sheets()[ 0]. ncols # 結果是:3
fh. sheets()[ 1]. nrows # 結果是:4
fh. sheets()[ 1]. ncols # 結果是:3
import xlrd
file = r"G:\Jupyter\test.xlsx"
fh = xlrd. open_workbook( file)
sheet1 = fh. sheets()[ 0]
for row in range( fh. sheets()[ 0]. nrows):
value = sheet1. row_values( row)
print( value)
效果如下:


有四張表,圖示中一目了然,就不做過多解釋。
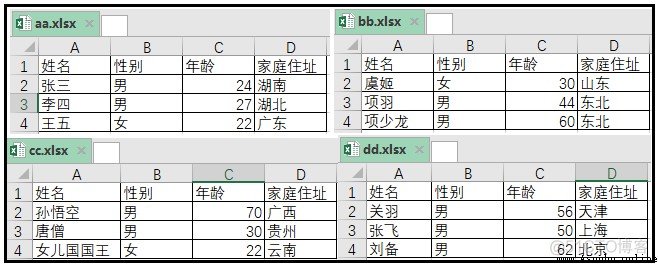
實現代碼如下:
import pandas as pd
import os
pwd = "G:\\b"
df_list = []
for path, dirs, files in os. walk( pwd):
for file in files:
file_path = os. path. join( path, file)
df = pd. read_excel( file_path)
df_list. append( df)
result = pd. concat( df_list)
print( result)
result. to_excel( 'G:\\b\\result.xlsx', index = False)
結果如下:
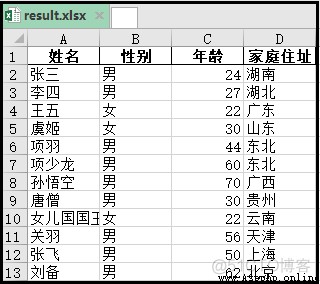
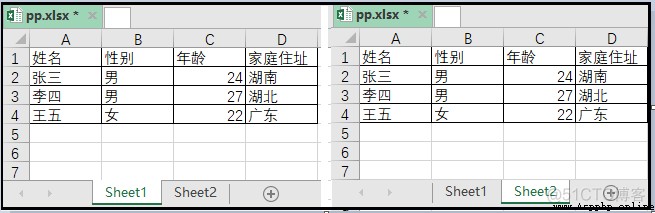
有兩個工作簿,如圖所示。一個工作簿是pp.xlsx,一個工作簿是qq.xlsx。工作簿pp.xlsx下,有sheet1和sheet2兩個工作表。工作簿qq.xlsx下,也有sheet1和sheet2兩個工作表。
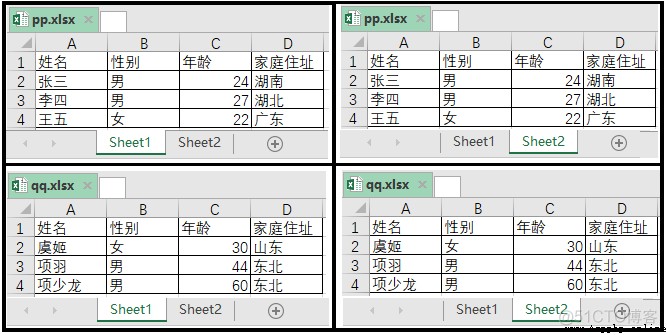
實現代碼如下:
import xlrd
import xlsxwriter
import os
# 打開一個Excel文件,創建一個工作簿對象
def open_xlsx( file):
fh = xlrd. open_workbook( file)
return fh
# 獲取sheet表的個數
def get_sheet_num( fh):
x = len( fh. sheets())
return x
# 讀取文件內容並返回行內容
def get_file_content( file, shnum):
fh = open_xlsx( file)
table = fh. sheets()[ shnum]
num = table. nrows
for row in range( num):
rdata = table. row_values( row)
datavalue. append( rdata)
return datavalue
def get_allxls( pwd):
allxls = []
for path, dirs, files in os. walk( pwd):
for file in files:
allxls. append( os. path. join( path, file))
return allxls
# 存儲所有讀取的結果
datavalue = []
pwd = "G:\\d"
for fl in get_allxls( pwd):
fh = open_xlsx( fl)
x = get_sheet_num( fh)
for shnum in range( x):
print( "正在讀取文件:" + str( fl) + "的第" + str( shnum) + "個sheet表的內容...")
rvalue = get_file_content( fl, shnum)
# 定義最終合並後生成的新文件
endfile = "G:\\d\\concat.xlsx"
wb1 = xlsxwriter. Workbook( endfile)
# 創建一個sheet工作對象
ws = wb1. add_worksheet()
for a in range( len( rvalue)):
for b in range( len( rvalue[ a])):
c = rvalue[ a][ b]
ws. write( a, b, c)
wb1. close()
print( "文件合並完成")
效果如下:
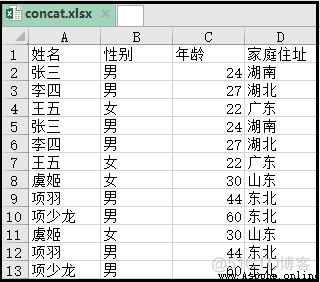
實現代碼如下:
import xlrd
import pandas as pd
from pandas import DataFrame
from openpyxl import load_workbook
excel_name = r"D:\pp.xlsx"
wb = xlrd. open_workbook( excel_name)
sheets = wb. sheet_names()
alldata = DataFrame()
for i in range( len( sheets)):
df = pd. read_excel( excel_name, sheet_name = i, index = False, encoding = 'utf8')
alldata = alldata. append( df)
writer = pd. ExcelWriter( r"C:\Users\Administrator\Desktop\score.xlsx", engine = 'openpyxl')
book = load_workbook( writer. path)
writer. book = book
# 必須要有上面這兩行,假如沒有這兩行,則會刪去其余的sheet表,只保留最終合並的sheet表
alldata. to_excel( excel_writer = writer, sheet_name = "ALLDATA")
writer. save()
writer. close()
效果如下:
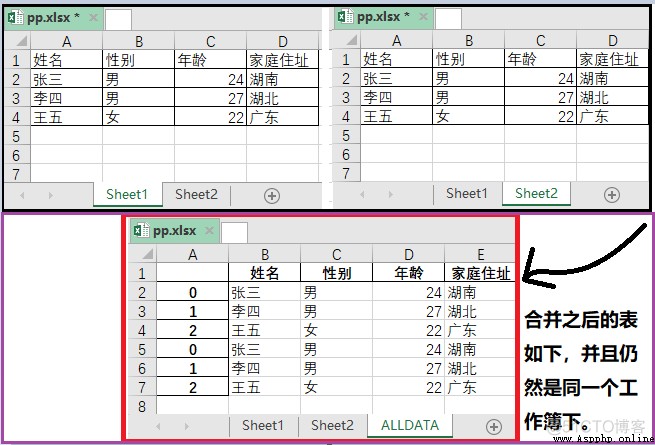
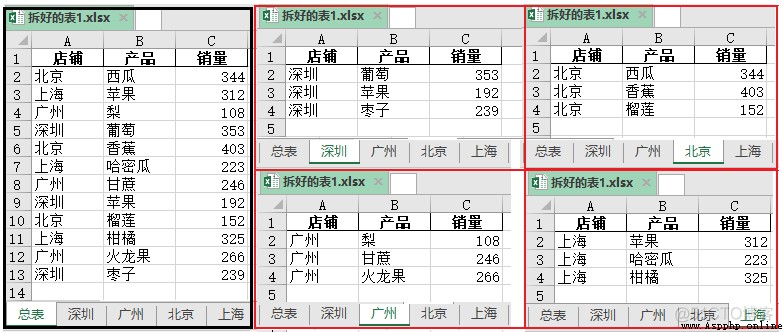
實現代碼如下:
import pandas as pd
import xlsxwriter
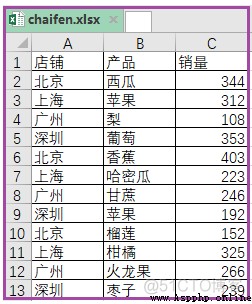
data = pd. read_excel( r"C:\Users\Administrator\Desktop\chaifen.xlsx", encoding = 'gbk')
area_list = list( set( data[ '店鋪']))
writer = pd. ExcelWriter( r"C:\Users\Administrator\Desktop\拆好的表1.xlsx", engine = 'xlsxwriter')
data. to_excel( writer, sheet_name = "總表", index = False)
for j in area_list:
df = data[ data[ '店鋪'] == j]
df. to_excel( writer, sheet_name = j, index = False)
writer. save() #一定要加上這句代碼,“拆好的表”才會顯示出來
效果如下: