️ 自如 實戰場景
我們又碰到了一個字體反爬的站點,自如。該站點的字體反爬不是用字體文件實現的,而是基於圖片+CSS,具體如下圖所示。

這裡運用 CSS 背景偏移技術實現數字的展示。
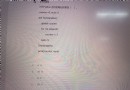
字體圖片如下所示。

圖片寬度和高度的比例是
300*28,其中 300 像素被等比例放置了 10 個數字,即每 30 個像素一個數字,實測間隔是 21.4 個像素。
後續可以參考該值做區分。
下面還需要確定一下每次刷新,圖片是否發生變化。
刷新了一下,發生了變化  ̄ □  ̄||
但是原理是一樣的,就是獲取圖片之後,然後解析對應的圖片,通過 OCR 技術,識別文字。
️ 自如 實戰編碼
獲取源碼,解析圖片地址。
import requests
from lxml import etree
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36"
}
res = requests.get('https://www.ziroom.com/z/',headers=headers)
tree = etree.HTML(res.text)
img_style = tree.xpath("//span[@class='num']/@style")[0]
# 不用正則,直接截取字符串
print(len('background-image: url(//'))
print(len(');background-position: -42.8px'))
# 不用正則,直接截取字符串
img_src = img_style[24:len(img_style)-30]
然後通過 OCR 軟件識別相關信息,然後進行提取。
# 下載圖片文件,通過 OCR 識別出數字
import ddddocr
ocr = ddddocr.DdddOcr()
res = requests.get('https://'+img_src,headers=headers)
# print(res.content)
# with open('./images/num_img1.png','wb') as f:
# f.write(res.content)
res = ocr.classification(res.content)
print(res)
測試中識別的數字為 5471380629,然後將其拆解即可。
測試發現截取圖片地址的時候,有時候會出現圖片地址錯誤,建議大家依舊使用正則表達式獲取。最後就是坐標與數字的對應關系了
其余的都參考這個原理即可。
你正在閱讀 【夢想橡皮擦】 的博客 閱讀完畢,可以點點小手贊一下 發現錯誤,直接評論區中指正吧 橡皮擦的第 <font color=red>670</font> 篇原創博客