With the development of various social platform,User generated content on the network more and more,Produce a large number of text information,如新聞、微博、博客等,In the face of such a large and rich emotional expression of text information,Fully consider by exploring their potential value service for the people.So in recent years, sentiment analysis by the researchers in the field of computer linguistics pays close attention to,Become a into the hot research task.
The task goal for accuracy in a large data set to distinguish the polarity text emotion,Emotional divided into three categories in the middle of a negative.In the face of vast news information,Accurate recognition in the emotional tendencies.
News data provided by the official emotional polarity classification,The positive emotions correspond0,Corresponding neutral emotion1As well as the corresponding negative emotion2.根據提供的訓練數據,The algorithm or model judge the emotional polarity test set news.
Packets by twocsv文件組成:第一個是Train_Dataset,包含7360條新聞的id號,News headlines and news content.第二個是Train_Dataset_Label,包含了DatasetIn the newsid號,With its news emotional score(用0,1,2表示).
In essence the problem of the classification and handling of information,So the core content is to use a suitable classifier.其次,Because the news is made up of text language,A news emotions can usually be determined by the words in the text of the emotional.於是,Another important content is how the data preprocessing,By deleting useless words,And cut the news text into Chinese words.
Observe the content of the training focus on news,Discovery news text in a mess,There are all sorts of do not belong to the Chinese word library symbols.So the first step of preprocessing is to do not belong to Chinese text deleted(包括各種標點符號).Pretreatment of the second step is to the revised text segmentation words,從而將一整段話切分為一個個詞語.
There are three kinds of emotion label assignment:積極、中立和消極.So all the second classifier can not use,Such as standard senseSVM支持向量機等.Considering the running time and efficiency,We will choose the simple bayesian classifier as the preferred(事實上,Test results also show that naive bayes classifier is a higher efficiency and accuracy are classifier)
實現細節,Model design and selection,數據預處理方式
以下是整個處理過程的具體實現:
對非中文無用數據的清理,需要將以下類別的數據從訓練集和測試集中清除:
html = re.compile('<.*?>')
http = re.compile(r'http[s]?://(?:[a-zA-Z]|[0-9]|[[email protected]&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+')
src = re.compile(r'\b(?!src|href)\w+=[\'\"].*?[\'\"](?=[\s\>])')
space = re.compile(r'[\\][n]')
ids = re.compile('[(]["微信"]?id:(.*?)[)]')
wopen = re.compile('window.open[(](.*?)[)]')
english = re.compile('[a-zA-Z]')
others= re.compile(u'[^\u4e00-\u9fa5\u0041-\u005A\u0061-\u007A\u0030-\u0039\u3002\uFF1F\uFF01\uFF0C\u3001\uFF1B\uFF1A\u300C\u300D\u300E\u300F\u2018\u2019\u201C\u201D\uFF08\uFF09\u3014\u3015\u3010\u3011\u2014\u2026\u2013\uFF0E\u300A\u300B\u3008\u3009\!\@\#\$\%\^\&\*\(\)\-\=\[\]\{\}\\\|\;\'\:\"\,\.\/\<\>\?\/\*\+\_"\u0020]+')
需要將html鏈接、數據來源、用戶名、英語字符和其他單個非中文字符清除,采用以上正則表達式描述需要刪除的類別,配合sub命令將其從訓練集和數據集中刪除.
數據劃分使用的庫為jieba分詞,具體的操作如下:
if __name__ =='__main__':
jieba.load_userdict('dict.txt')
jieba.enable_parallel(2)
print("Processing: cutting train data...")
cut_Train_Data = cutData('Train/preprocessed_train_data.csv')
cut_Train_Data.to_csv('Train/preprocessed_train_data.csv')
print("Processing: cutting test data...")
cut_Test_Data = cutData('Test/Test_DataSet_P.csv')
cut_Test_Data.to_csv('Test/result.csv')
We use the dictionary is notjiebaThe built-in dictionary,But the custom dictionarydict.txt,Word segmentation process open double thread optimization.
分詞函數cutData的定義:
def cutData(filePath):
cutData = pd.read_csv(filePath,index_col=0)
cutData['title'] = pd.DataFrame(cutData['title'].astype(str))
cutData['title'] = cutData['title'].apply(lambda x: cut_char(x))
cutData['content'] = pd.DataFrame(cutData['content'].astype(str))
cutData['content'] = cutData['content'].apply(lambda x: cut_char(x))
cutData['combine'] = cutData['content']+'/'+70*(cutData['title']+'/')
print(cutData.head())
return cutData
Of data setstitle和content進行分詞,And after the end of the handle will reassemble the two,中間用“/”隔開.In the experiment of the sequence we found,Title more than article can accurately describe the news emotional(In not encounterUCUnder the condition of the browser's news),所以使用70Repeat the content of the words in a title to increase in importance(Its frequency).分詞方式使用jiebaThe whole precision segmentation way.
經過以上兩步,我們已經將文本成功分割為獨立的中文詞語,接下來需要統計每個詞出現的頻率及分布.
stop_words=get_custom_stopwords('ChineseStopWords.txt')
首先需要獲得停用詞表.這裡我們使用的是百度停用詞表、哈工大停用詞表、中文停用詞表等多個詞表的綜合結果.
Vectorizer = CountVectorizer( max_df = 0.8,
min_df = 2,
token_pattern = u'(?u)\\b[^\\d\\W]\\w+\\b',
stop_words =frozenset(stop_words)
)
Vectorizer_Title = CountVectorizer( max_df = 0.8,
min_df = 3,
token_pattern = u'(?u)\\b[^\\d\\W]\\w+\\b',
stop_words =frozenset(stop_words) )
CountVectorizer是通過fit_transform函數將文本中的詞語轉換為詞頻矩陣,矩陣元素a[i][j] 表示j詞在第i個文本下的詞頻.即各個詞語出現的次數,通過get_feature_names()可看到所有文本的關鍵字,通過toarray()可看到詞頻矩陣的結果.
X = trainData['content'].astype('U')
y = trainData.label
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=2019)
test = pd.DataFrame(Vectorizer.fit_transform(X_train).toarray(), columns=Vectorizer.get_feature_names())
先對文本內容進行詞頻統計.值得一提的是,We carried out in the sequence of operation, the title of word frequency statistics and comprehensive title and text word frequency statistics,And focused on the statistical results of the three matrix on three bayesian classification.
此處需要說明的是,We will training focus randomly selected80%The data used in the training of the classifier,剩余20%Used for testing the result of the training.
Naive bayesian method is based on a group of supervised learning algorithm of bayesian theorem,即“簡單”To assume between each pair of features are independent of each other. 給定一個類別

回到原問題,Considering the goal of our classification is not a word,But based on the text generated word vector,So when choosing a specific classifier we chose the multinomial distribution simple bayesian.Many naive bayes is characterized by distribution parameters by each type of
In the sum of all the characteristics of the count.這樣一來,We can through the news in a variety of word frequency and a posteriori probability of emotion classification on the news.
nb = MultinomialNB()
X_train_vect = Vectorizer.fit_transform(X_train)
nb.fit(X_train_vect, y_train)
train_score = nb.score(X_train_vect, y_train)
print("content train score is : ",train_score)
The multinomial distribution simple bayesian training.
Content train scoreReflect the classifier on the training data scores(To classify the correct proportion for reference)
X_test_vect = Vectorizer.transform(X_test)
print("content test score is : ", nb.score(X_test_vect, y_test))
y_predict = nb.predict(Vectorizer.transform(X_test))
print("content test macro f1_score:",sklearn.metrics.f1_score(y_test, y_predict, average='macro'))
Content test scoreReflect the classifier in other randomly selected20%Scores on the training set data(To classify the correct proportion for reference)
Give a trainer in the training set20%測試集上的F1-score.F1-score : 2(PR)/(P+R)
Among them the meaning of each symbol:
准確率§ : TP/ (TP+FP)
召回率 : TP(TP + FN)
真陽性(TP): 預測為正, 實際也為正
假陽性(FP): 預測為正, 實際為負
假陰性(FN): 預測為負,實際為正
真陰性(TN): 預測為負, 實際也為負
from sklearn.metrics import confusion_matrix
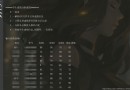
cm = confusion_matrix(y_test, y_predict)
print(cm)
Print classifier in training20%On the test set classification confusion matrix.
print("Apply to Test Data...")
testData = pd.read_csv('Test/result.csv',index_col=0)
testResult = nb.predict(Vectorizer.transform(testData['content'].astype('U')))
testData['label_content'] = testResult
The division of data sets using simple random sampling way,Random seed,The sample of the training set80%用來訓練,剩余20%Used to test the classifier performance after training.
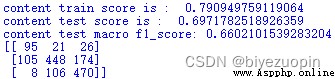
可以看出,Only the text to the training effect is not very good,Correct classification rate of training set itself79%,To keep out of the test set of the correct classification rate is also only70%,F1得分為0.66.As can be seen from the confusion matrix,Classifier is not good for the classification of the neutral attitude.
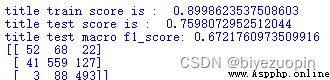
Only the headlines for training,性能有較大提升.The correct classification rate of training set itself by11個百分點,Also have to the promotion of retention test set6%,F1得分有0.012的提高,變動不大.分析混淆矩陣,Find the classification of the headlines in the classification of the neutral and negative emotions have greater performance,But for the positive emotions of the classification effect is poorer(Even with random classification about).
By the above two training result,Text classification faults in neutral emotions,Title classification faults in positive emotions,So according to the weight the text and title will be the joint training should be avoid.Considering the length of the headlines and the length of the news text is a far cry from,We have adopted in data preprocessing to news headlines are repeated many times the word frequency of the words in a way of increasing the headlines(We use the repeat70次).
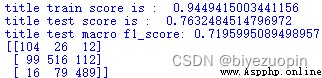
經過修正後,To the training set themselves the correct classification rate of94.5%,To keep the classification of the test set to76.3%,F1得分為0.72,To achieve the ideal,The average classification level gap smaller result.