隨著各種社交平台的興起,網絡上用戶的生成內容越來越多,產生大量的文本信息,如新聞、微博、博客等,面對如此龐大且富有情緒表達的文本信息,完全可以考慮通過探索他們潛在的價值為人們服務。因此近年來情緒分析受到計算機語言學領域研究者們的密切關注,成為一項進本的熱點研究任務。
本賽題目標為在龐大的數據集中精准的區分文本的情感極性,情感分為正中負三類。面對浩如煙海的新聞信息,精確識別蘊藏在其中的情感傾向。
對官方提供的新聞數據進行情感極性分類,其中正面情緒對應0,中性情緒對應1以及負面情緒對應2。根據提供的訓練數據,通過算法或模型判斷出測試集中新聞的情感極性。
數據包由兩個csv文件組成:第一個是Train_Dataset,包含7360條新聞的id號,新聞標題和新聞內容。第二個是Train_Dataset_Label,包含了Dataset中新聞的id號,以其新聞的情感得分(用0,1,2表示)。
該問題實質上為對信息的分類處理,所以核心內容是使用一個合適的分類器。其次,由於新聞是由文本構成的語言,一條新聞的情感通常可以由文本中詞語的情感性決定。於是,另一個重要的內容是如何將數據進行預處理,即刪除無用文字,並將新聞文本切分成一個個中文詞語。
觀察訓練集中新聞的內容,發現新聞文本亂七八糟,有各種不屬於中文詞庫的符號。所以預處理的第一步就是將不屬於中文的文本刪除(包括各種標點符號)。預處理的第二步是將修正後的文本進行詞語的切分,從而將一整段話切分為一個個詞語。
情感標簽有三種賦值:積極、中立和消極。於是所有的二分類器就不可以使用,比如標准意義下的SVM支持向量機等。考慮到運行時間和效率,我們將選擇樸素貝葉斯分類器作為首選(事實上,測試結果也表明樸素貝葉斯分類器是效率和正確率均較高的分類器)
實現細節,模型設計和選擇,數據預處理方式
以下是整個處理過程的具體實現:
對非中文無用數據的清理,需要將以下類別的數據從訓練集和測試集中清除:
html = re.compile('<.*?>')
http = re.compile(r'http[s]?://(?:[a-zA-Z]|[0-9]|[[email protected]&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+')
src = re.compile(r'\b(?!src|href)\w+=[\'\"].*?[\'\"](?=[\s\>])')
space = re.compile(r'[\\][n]')
ids = re.compile('[(]["微信"]?id:(.*?)[)]')
wopen = re.compile('window.open[(](.*?)[)]')
english = re.compile('[a-zA-Z]')
others= re.compile(u'[^\u4e00-\u9fa5\u0041-\u005A\u0061-\u007A\u0030-\u0039\u3002\uFF1F\uFF01\uFF0C\u3001\uFF1B\uFF1A\u300C\u300D\u300E\u300F\u2018\u2019\u201C\u201D\uFF08\uFF09\u3014\u3015\u3010\u3011\u2014\u2026\u2013\uFF0E\u300A\u300B\u3008\u3009\!\@\#\$\%\^\&\*\(\)\-\=\[\]\{\}\\\|\;\'\:\"\,\.\/\<\>\?\/\*\+\_"\u0020]+')
需要將html鏈接、數據來源、用戶名、英語字符和其他單個非中文字符清除,采用以上正則表達式描述需要刪除的類別,配合sub命令將其從訓練集和數據集中刪除。
數據劃分使用的庫為jieba分詞,具體的操作如下:
if __name__ =='__main__':
jieba.load_userdict('dict.txt')
jieba.enable_parallel(2)
print("Processing: cutting train data...")
cut_Train_Data = cutData('Train/preprocessed_train_data.csv')
cut_Train_Data.to_csv('Train/preprocessed_train_data.csv')
print("Processing: cutting test data...")
cut_Test_Data = cutData('Test/Test_DataSet_P.csv')
cut_Test_Data.to_csv('Test/result.csv')
我們使用的詞典並非jieba的內置詞典,而是用戶自定義詞典dict.txt,分詞過程開雙線程優化。
分詞函數cutData的定義:
def cutData(filePath):
cutData = pd.read_csv(filePath,index_col=0)
cutData['title'] = pd.DataFrame(cutData['title'].astype(str))
cutData['title'] = cutData['title'].apply(lambda x: cut_char(x))
cutData['content'] = pd.DataFrame(cutData['content'].astype(str))
cutData['content'] = cutData['content'].apply(lambda x: cut_char(x))
cutData['combine'] = cutData['content']+'/'+70*(cutData['title']+'/')
print(cutData.head())
return cutData
分別對數據集的title和content進行分詞,並在處理結束之後將二者重新拼接,中間用“/”隔開。在後序的實驗中我們發現,標題比文章更能准確地表述新聞的情感(在不碰到UC浏覽器的新聞的情況下),所以使用70次重復標題中詞語的內容來加大重要性(即其出現頻率)。分詞方式使用jieba的全精度分詞方式。
經過以上兩步,我們已經將文本成功分割為獨立的中文詞語,接下來需要統計每個詞出現的頻率及分布。
stop_words=get_custom_stopwords('ChineseStopWords.txt')
首先需要獲得停用詞表。這裡我們使用的是百度停用詞表、哈工大停用詞表、中文停用詞表等多個詞表的綜合結果。
Vectorizer = CountVectorizer( max_df = 0.8,
min_df = 2,
token_pattern = u'(?u)\\b[^\\d\\W]\\w+\\b',
stop_words =frozenset(stop_words)
)
Vectorizer_Title = CountVectorizer( max_df = 0.8,
min_df = 3,
token_pattern = u'(?u)\\b[^\\d\\W]\\w+\\b',
stop_words =frozenset(stop_words) )
CountVectorizer是通過fit_transform函數將文本中的詞語轉換為詞頻矩陣,矩陣元素a[i][j] 表示j詞在第i個文本下的詞頻。即各個詞語出現的次數,通過get_feature_names()可看到所有文本的關鍵字,通過toarray()可看到詞頻矩陣的結果。
X = trainData['content'].astype('U')
y = trainData.label
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=2019)
test = pd.DataFrame(Vectorizer.fit_transform(X_train).toarray(), columns=Vectorizer.get_feature_names())
先對文本內容進行詞頻統計。值得一提的是,在後序的操作中我們相繼進行了對標題的詞頻統計和綜合標題和文本的詞頻統計,並針對這三個矩陣的統計結果進行了三次貝葉斯分類。
此處需要說明的是,我們將訓練集中隨機選出的80%數據用於分類器的訓練,剩余20%用於測試訓練的結果。
樸素貝葉斯方法是基於貝葉斯定理的一組有監督學習算法,即“簡單”地假設每對特征之間相互獨立。 給定一個類別

回到原問題,考慮到我們分類的目標不是某一個詞語,而是基於文本生成的詞向量,於是在選擇具體的分類器時我們選擇了多項分布樸素貝葉斯。多項分布樸素貝葉斯的特征是分布參數由每類
中出現所有特征的計數總和。這樣一來,我們可以通過一條新聞內出現各種詞的頻率和後驗概率對該新聞進行情感分類。
nb = MultinomialNB()
X_train_vect = Vectorizer.fit_transform(X_train)
nb.fit(X_train_vect, y_train)
train_score = nb.score(X_train_vect, y_train)
print("content train score is : ",train_score)
接下來進行多項分布樸素貝葉斯的訓練。
Content train score反映的是分類器在訓練數據上的得分情況(以分類正確的比例為參考)
X_test_vect = Vectorizer.transform(X_test)
print("content test score is : ", nb.score(X_test_vect, y_test))
y_predict = nb.predict(Vectorizer.transform(X_test))
print("content test macro f1_score:",sklearn.metrics.f1_score(y_test, y_predict, average='macro'))
Content test score反映的是分類器在其他隨機選出的20%訓練集數據上的得分情況(以分類正確的比例為參考)
給出訓練器在訓練集中的20%測試集上的F1-score。F1-score : 2(PR)/(P+R)
其中各符號的含義:
准確率§ : TP/ (TP+FP)
召回率 : TP(TP + FN)
真陽性(TP): 預測為正, 實際也為正
假陽性(FP): 預測為正, 實際為負
假陰性(FN): 預測為負,實際為正
真陰性(TN): 預測為負, 實際也為負
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_predict)
print(cm)
打印分類器在訓練集中的20%測試集上分類的混淆矩陣。
print("Apply to Test Data...")
testData = pd.read_csv('Test/result.csv',index_col=0)
testResult = nb.predict(Vectorizer.transform(testData['content'].astype('U')))
testData['label_content'] = testResult
數據集的劃分采用樸素的隨機采樣方式,選取隨機種子,將樣本訓練集的80%用來訓練,剩余20%用來測試訓練後分類器的性能。
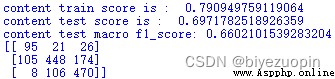
可以看出,僅對文本進行訓練的效果不是很好,對訓練集自身的正確分類率有79%,對保留出來的測試集的正確分類率也只有70%,F1得分為0.66。從混淆矩陣中可以看出,分類器對中立態度的分類情況不甚理想。
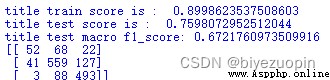
僅對新聞標題進行訓練,性能有較大提升。對訓練集自身的正確分類率提高11個百分點,對保留測試集的提升也有6%,F1得分有0.012的提高,變動不大。分析混淆矩陣,發現新聞標題的分類在中性和負面情緒的分類性能有較大提升,但對正面情緒的分類效果較差(甚至和隨機分類差不多)。
由上面兩次訓練的結果可知,文本分類的缺點在中性情緒,標題分類的缺點在正面情緒,所以按權重將文本和標題聯合訓練應該會將二者的問題避免。考慮到新聞標題的長度與新聞文本的長度相去甚遠,我們采用了在數據預處理時將新聞標題多次重復出現的方式適當提高新聞標題中詞語的詞頻(我們使用的是重復70次)。
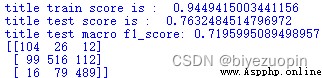
經過修正後,對訓練集自身的正確分類率達到94.5%,對保留測試集的分類達到76.3%,F1得分為0.72,達到了較為理想,平均分類水平差距較小的結果。