TextCNN 是利用卷積神經網絡對文本進行分類的算法,由 Yoon Kim 在 “Convolutional Neural Networks for Sentence Classification” 一文 (見參考[1]) 中提出. 是 2014 年的算法.
圖 1-1 參考[1] The accompanying drawings in the paper
在這裡插入圖片描述
以下是閱讀 TextCNN 後的理解
步驟:
1.Segment the sentences first,一般使用“jieba”庫進行分詞.
2.在原文中,用了 6 A convolution kernel convolves the original word vector matrix.
卷積具有局部特征提取的功能, 所以可用 CNN 來提取句子中類似 n-gram 的關鍵信息.
size of the convolution kernel:2 個 46、2 個 36 和 2 個 2*6,如上圖所示;然後進行池化,Concatenate feature maps produced by the same convolution kernel;再進行 softmax 輸出 2 個類別.
1).這裡對 no-static 進行闡述,Use variable word vectors,This is closer to natural life,Sentences of different lengths mean different things,So in my opinion adopt no-static 比 static closer to semantics.
2).After convolution and pooling of a word vector,The resulting feature is only one 1*1 的向量,So it doesn't matter static 和 no-static The resulting feature is only one,It has no effect on the Bunsen network.
Why use convolution kernels of different sizes,different perception horizons,The width of the convolution kernel takes the latitude of the vocabulary,Conducive to semantic extraction.
體現在代碼中
tf.flags.DEFINE_string("filter_sizes", "3,4,5", "Comma-separated filter sizes (default: '3,4,5')")
filter_sizes=list(map(int, FLAGS.filter_sizes.split(","))),
是一個 list
5.Research proves why words are used,instead of words,The reason is the word granularity accuracy > Word granularity accuracy.There are two models,一種是詞袋模型,The second is the word vector model.The word vector model will be described below.
詞向量模型:
Usually starts at high latitudes,Highly sparse vector,Dimensionality reduction is performed using an embedding layer,Increase density.
The steps for text classification using word vectors are:
①.First use the word segmentation tool to extract the vocabulary.
②.Convert the content to be classified into word vectors.
a.分詞
b.Convert each word to word2vec 向量.
c.Combine in order word2vec,So long combined into a word vector.
d.降維,The low latitude set for us by the original high latitude reduction.
e.卷積、Pooling and connections,然後進行分類.
6.嵌入層
through a hidden layer word2vec The word vector of high latitude is converted to the word vector of low latitude space,The essence of this layer is feature extraction,Extract features from high latitude word vectors to low latitudes,In this way, words with similar semantics can be mapped to the low-dimensional space,European is closer.
參數與超參數
sequence_length
Q: 對於 CNN, Both input and output are fixed,Each sentence may vary in length, 怎麼處理?
A: Length processing is required, 比如定為 n, Truncation exceeded, 不足的補 0. Note supplementary 0 It has no effect on subsequent results,因為後面的 max-pooling Only the maximum value will be output,Zero-padded items are filtered out.
num_classes
多分類, 分為幾類.
vocabulary_size
The dictionary size of the corpus, 記為 |D|.
embedding_size
The dimension of the word vector, 由原始的 |D| 降維到 embedding_size.
filter_size_arr
多個不同 size 的 filter.
Embedding Layer
首先用 VocabularyProcessor 將 每一句話 轉為 詞 id 向量
Then the word embedding matrix is defined,word to be entered id Converted to word vectors,The word embedding matrix here is trainable,What we want is after training,輸入經過 W A hidden layer of fixed dimension resulting from matrix transformation,And word vector matrix via a word embedding matrix, 將 編碼的詞投影到一個低維空間中.
本質上是特征提取器,在指定維度中編碼語義特征. 這樣, 語義相近的詞, 它們的歐氏距離或余弦距離也比較近.
self.embedded_chars=tf.nn.embedding_lookup(W,self.input_x)

如果先用 word2vec_helpers 處理完,然後代用 textCNN 的情況下,這裡的 embeding Layer is not necessary?
The original is not used beforehand word2vec 的情況下:在網絡層有 embeding 層

and used in advance word2vec_helpers 處理完之後,

Convolution Layer
for different sizes filter Both build a convolutional layer. 所以會有多個 feature map.
An image is two-dimensional data composed of pixels, 有時還會有 RGB 三個通道, So their convolution kernels are at least two-dimensional.
從某種程度上講, word is to text as pixel is to image, So this convolution kernel size 與 stride 會有些不一樣.
xixi
xi∈Rkxi∈Rk, 一個長度為 n 的句子中, 第 i 個詞語的詞向量, 維度為 k.
xi:jxi:j
xi:j=xi⊕xi+1⊕…⊕xjxi:j=xi⊕xi+1⊕…⊕xj
表示在長度為 n 的句子中, 第 [i,j] The concatenation of word vectors for each word.
hh
The number of words in the window enclosed by the convolution kernel, The size of the convolution kernel is actually hkhk.
ww
w∈Rhkw∈Rhk, The weight matrix of the convolution kernel.
cici
ci=f(wxi:i+h1+b)ci=f(wxi:i+h1+b), The convolution kernel is on words i output at position.b∈RKb∈RK, 是 bias.ff is an activation function like the hyperbolic tangent.
c=[c1,c2,…,cnh+1]c=[c1,c2,…,cnh+1]
filter Do all possible swipes over the words in the sentence, 得到的 featuremapfeaturemap.
Max-Pooling Layer
max-pooling Only the maximum value will be output, Complement in input 0 做過濾.
SoftMax 分類 Layer
最後接一層全連接的 softmax 層,輸出每個類別的概率.
Small variant
在 word representation There will be some variations in handling.
CNN-rand
設計好 embedding_size 這個 Hyperparameter 後, 對不同單詞的向量作隨機初始化, 後續 BP 的時候作調整.
static
拿 pre-trained vectors from word2vec, FastText or GloVe 直接用, 訓練過程中不再調整詞向量. This is also an idea of transfer learning.
non-static
pre-trained vectors + fine tuning , 即拿 word2vec 訓練好的詞向量初始化, 訓練過程中再對它們微調.
multiple channel
類比於圖像中的 RGB 通道, 這裡也可以用 static 與 non-static Take two channels to do it.
一些結果表明,max-pooling 總是優於 average-pooling ,理想的 filter sizes 是重要的,But specific tasks are considered,It seems that with or without regularization NLP There's not a huge difference in tasks.
Text CNN 的 tf 實現
圖 8-1 Text CNN Convolution and Pooling in Networks 結構
需要注意的細節有.
tf.nn.embedding_lookup()
與 LeNet 作比較
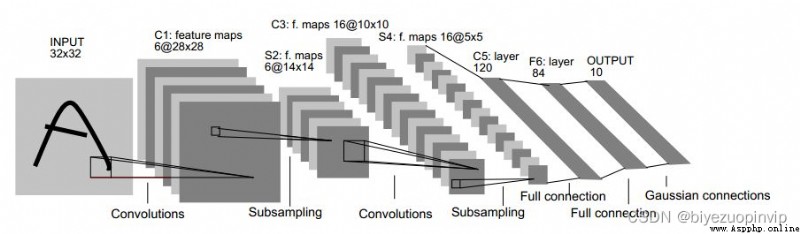
figure LeNet-5 網絡結構
# LeNet5
conv1_weights = tf.get_variable(
"weight",
[CONV1_SIZE, CONV1_SIZE, NUM_CHANNELS, CONV1_DEEP],
initializer=tf.truncated_normal_initializer(stddev=0.1))
tf.nn.conv2d(
input_tensor,
conv1_weights,
strides=[1, 1, 1, 1],
padding='SAME')
tf.nn.max_pool(
relu1,
ksize = [1,POOL1_SIZE,POOL1_SIZE,1],
strides=[1,POOL1_SIZE,POOL1_SIZE,1],
padding="SAME")
# TextCNN
conv1_weights = tf.get_variable(
"weight",
[FILTER_SIZE, EMBEDDING_SIZE, 1, NUM_FILTERS],
initializer=tf.truncated_normal_initializer(stddev=0.1))
tf.nn.conv2d(
self.embedded_chars_expanded,
conv1_weights,
strides=[1, 1, 1, 1],
padding="VALID")
tf.nn.max_pool(
h,
ksize=[1, SEQUENCE_LENGTH - FILTER_SIZE + 1, 1, 1],
strides=[1, 1, 1, 1],
padding='VALID')
LeNet 的 filter 是正方形的, And each layer uses only the same size of convolution kernel. Text-CNN 中, filter 是矩形, There are several lengths of rectangles, 一般取 (2,3,4), The width of the rectangle is fixed, 同 word 的 embedding_size 相同. Comes with every size NUM_FILTERS 個數目, 類比於 LeNet 中的 output_depth,所以得到的 feature_map is long, 寬度為 1.
Because it is convolution, 所以 stride 每個維度都是 1.
池化處理, 也叫下采樣. There is still a comparison here LeNet 網絡.
LeNet 的 kernel 是正方形, 一般也是 2*2 等, So it will be convoluted feature_map Reduced in size by half.
Text-CNN 的 kernel It's still a rectangle, 將整個 feature_map map to a point. 一步到位, There is only one pooling layer.
All are multi-category, The processing of this step is similar. The pooled matrix reshape 為二維, 用 tf.nn.sparse_softmax_cross_entropy_with_logits() 計算損失.
TextCNN 論文中的網絡結構
windows size 分別取 (3,4,5), Every size will have it 100 個 filter.
Hyperparameters and Training
For all datasets we use:
rectified linear units, filter
windows (h) of 3, 4, 5 with 100 feature maps each,
dropout rate (p) of 0.5, l2 constraint (s) of 3, and
mini-batch size of 50. These values were chosen
via a grid search on the SST-2 dev set.
1