Welcome to Dinosaur Land! 6500萬年前,Dinosaurs already exist,and under that assignment they came back.Suppose you are in charge of a special task,Leading biology researchers are creating new species of dinosaur,And plans to put them into the earth,And your job is to name these new dinosaurs.if the dinosaur didn't like its name,it can get crazy,So you need to choose wisely!
幸運的是,You have some knowledge of deep learning,you will use it to save time.Your assistant has collected they can find all the name list of dinosaur,and compile it to thisdataset中.(Please click the previous link to view)要創建新的恐龍名稱,You will build a letter-level language model to generate new names.Your algorithm will learn different name patterns,and randomly generate new names.Hopefully this algorithm saves you and your team from the wrath of dinosaurs!
complete this assignment,你將學習:
outside will loadrnn_utilsSome of the functions provided for you in.具體來說,you can access things likernn_forward和rnn_backward之類的函數,These functions are equivalent to the functions you implemented in the previous assignment.
import numpy as np
from utils import *
import random
from random import shuffle
Run the following cell to read a dataset containing dinosaur names,Create a list of unique characters(例如a-z),And calculate the data sets and vocabulary.
# 獲取名稱
data = open("datasets/dinos.txt", "r").read()
# 轉化為小寫字符
data = data.lower()
# 轉化為無序且不重復的元素列表
chars = list(set(data))
# 獲取大小信息
data_size, vocab_size = len(data), len(chars)
print(chars)
print("共計有%d個字符,唯一字符有%d個"%(data_size,vocab_size))
['y', 'o', 'm', 'q', 'g', 'v', 'j', 'i', 't', 'r', 'h', 's', 'b', 'n', 'd', 'k', 'p', 'c', '\n', 'w', 'e', 'a', 'z', 'l', 'u', 'f', 'x']
共計有19909個字符,唯一字符有27個
這些字符是a-z(26個字符)加上“\n”(換行符),在此作業中,Its role is similar to what we discussed in the lecture<EOS>(句子結尾)標記,Only here means the end of the dinosaur name,rather than the end of the sentence.在下面的單元格中,外面創建一個python字典(即哈希表),to map each character as0-26之間的索引.Outside also created a secondpython字典,This dictionary maps each index back to the corresponding character.This will help you find outsoftmaxWhich index corresponds to which character in the probability distribution output of the layer.下面的char_to_ix和ix_to_char是python字典.
char_to_ix = {
ch:i for i,ch in enumerate(sorted(chars)) }
ix_to_char = {
i:ch for i,ch in enumerate(sorted(chars)) }
print(ix_to_char)
{0: '\n', 1: 'a', 2: 'b', 3: 'c', 4: 'd', 5: 'e', 6: 'f', 7: 'g', 8: 'h', 9: 'i', 10: 'j', 11: 'k', 12: 'l', 13: 'm', 14: 'n', 15: 'o', 16: 'p', 17: 'q', 18: 'r', 19: 's', 20: 't', 21: 'u', 22: 'v', 23: 'w', 24: 'x', 25: 'y', 26: 'z'}
Your model will have the following structure:
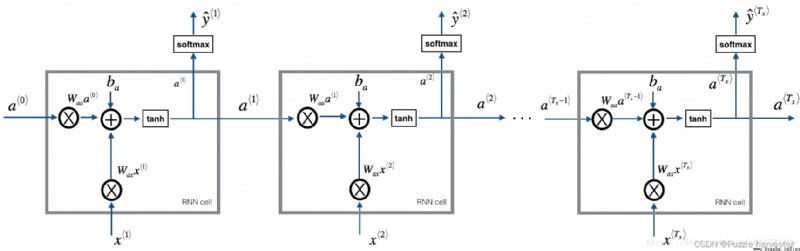
圖1:循環神經網絡,Similar to your last notebook“手把手實現循環神經網絡”The content of the building.
在每個時間步,RNNboth predict the next character based on the given previous character.數據集 X = ( x * 1 * , x * 2 * , . . . , x * T x * ) X = (x^{\langle 1 \rangle}, x^{\langle 2 \rangle}, ..., x^{\langle T_x \rangle}) X=(x*1*,x*2*,...,x*Tx*)is the list of characters in the training set,而 Y = ( y * 1 * , y * 2 * , . . . , y * T x * ) Y = (y^{\langle 1 \rangle}, y^{\langle 2 \rangle}, ..., y^{\langle T_x \rangle}) Y=(y*1*,y*2*,...,y*Tx*)make each time step t t t,我們有 y * t * = x * t + 1 * y^{\langle t \rangle} = x^{\langle t+1 \rangle} y*t*=x*t+1*.
在這一部分中,You will build two important modules of the entire model:
然後,You will apply these two functions to build the model.
在本節中,You will achieve in the optimization cycle callclip函數.回想一下,Your overall loop structure is usually represented by forward propagation,損失計算,Backpropagation and parameter update composition.在更新參數之前,You will perform gradient clipping when needed,In order to ensure your gradient will not“爆炸”,This means taking very large values.
在下面的練習中,you will implement a functionclip,The function receives a dictionary of gradients,And to return after cutting in gradient.There are many methods for gradient clipping.We will use a simple dark element clipper,where each element of the gradient vector is clipped to lie in the range [ − N , N ] [-N, N] [−N,N]之間.通常,you will provide amaxValue(例如10).在此示例中,If any component of the gradient vector is greater than10,則將其設置為10;and if any component of the gradient vector is less than-10,則將其設置為-10.如果介於-10和10之間,則將其保留.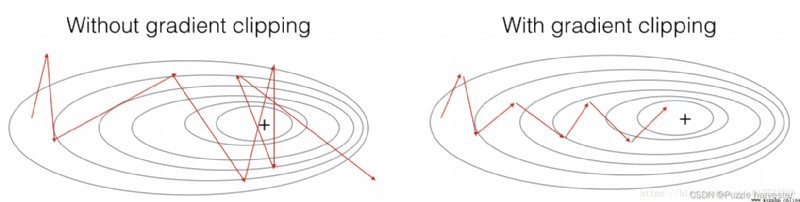
圖2:encountered a slight“梯度爆炸”的情況下,Gradient descent with and without gradient clipping.
練習:Implement the following function to return a dictionarygradientsThe clipping gradient of.your function accepts max threshold,and returns the clipped gradient.你可以查看此hint,for information on how to cropnumpy的示例.you will need to use the parameterout = ....
def clip(gradients, maxValue):
""" 使用maxValue來修剪梯度 參數: gradients -- 字典類型,包含了以下參數:"dWaa", "dWax", "dWya", "db", "dby" maxValue -- 阈值,把梯度值限制在[-maxValue, maxValue]內 返回: gradients -- 修剪後的梯度 """
# 獲取參數
dWaa, dWax, dWya, db, dby = gradients['dWaa'], gradients['dWax'], gradients['dWya'], gradients['db'], gradients['dby']
# 梯度修剪
for gradient in [dWaa, dWax, dWya, db, dby]:
np.clip(gradient, -maxValue, maxValue, out=gradient)
gradients = {
"dWaa": dWaa, "dWax": dWax, "dWya": dWya, "db": db, "dby": dby}
return gradients
np.random.seed(3)
dWax = np.random.randn(5,3)*10
dWaa = np.random.randn(5,5)*10
dWya = np.random.randn(2,5)*10
db = np.random.randn(5,1)*10
dby = np.random.randn(2,1)*10
gradients = {
"dWax": dWax, "dWaa": dWaa, "dWya": dWya, "db": db, "dby": dby}
gradients = clip(gradients, 10)
print("gradients[\"dWaa\"][1][2] =", gradients["dWaa"][1][2])
print("gradients[\"dWax\"][3][1] =", gradients["dWax"][3][1])
print("gradients[\"dWya\"][1][2] =", gradients["dWya"][1][2])
print("gradients[\"db\"][4] =", gradients["db"][4])
print("gradients[\"dby\"][1] =", gradients["dby"][1])
gradients["dWaa"][1][2] = 10.0
gradients["dWax"][3][1] = -10.0
gradients["dWya"][1][2] = 0.2971381536101662
gradients["db"][4] = [10.]
gradients["dby"][1] = [8.45833407]
Now assume your model is already trained.you want to generate new text(字符).The following diagram illustrates the build process: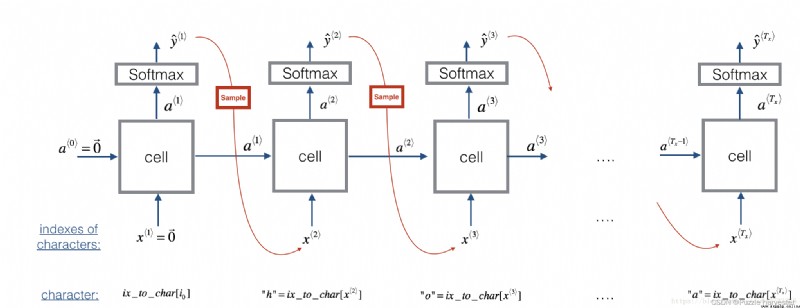
圖3:在此圖中,We assume that the model is already trained.We pass in in the first step x * 1 * = 0 ⃗ x^{\langle 1\rangle} = \vec{0} x*1*=0,And then let the network sampling one character at a time.
練習:實現以下的samplefunction to sample letters.你需要執行4個步驟:
softmax()functions for you to use.np.random.choice.np.random.choice()的例子:np.random.seed(0)
p = np.array([0.1, 0.0, 0.7, 0.2])
index = np.random.choice([0, 1, 2, 3], p = p.ravel())
This means that you will choose based on the distribution`index`:$P(index = 0) = 0.1, P(index = 1) = 0.0, P(index = 2) = 0.7, P(index = 3) = 0.2$.
sample()The last step implemented in is overriding the variablex,The variable currently stores x * t * x^{\langle t \rangle } x*t*,其值為 x * t + 1 * x^{\langle t+1 \rangle } x*t+1*.By creating a correspondingone-hotThe vector is represented as x * t + 1 * x^{\langle t+1 \rangle } x*t+1*.然後,you will be in step1forward propagation x * t + 1 * x^{\langle t+1 \rangle } x*t+1*,And continue to repeat this process,直到獲得"\n"字符,Show that you have arrived in name at the end of the dinosaur.def sample(parameters, char_to_is, seed):
""" 根據RNN輸出的概率分布序列對字符序列進行采樣 參數: parameters -- 包含了Waa, Wax, Wya, by, b的字典 char_to_ix -- 字符映射到索引的字典 seed -- 隨機種子 返回: indices -- 包含采樣字符索引的長度為n的列表. """
# 從parameters 中獲取參數
Waa, Wax, Wya, by, b = parameters['Waa'], parameters['Wax'], parameters['Wya'], parameters['by'], parameters['b']
vocab_size = by.shape[0]
n_a = Waa.shape[1]
# 步驟1
## 創建獨熱向量x
x = np.zeros((vocab_size,1))
## 使用0初始化a_prev
a_prev = np.zeros((n_a,1))
# 創建索引的空列表,這是包含要生成的字符的索引的列表.
indices = []
# IDX是檢測換行符的標志,我們將其初始化為-1.
idx = -1
# 循環遍歷時間步驟t.在每個時間步中,從概率分布中抽取一個字符,
# 並將其索引附加到“indices”上,如果我們達到50個字符,
#(我們應該不太可能有一個訓練好的模型),我們將停止循環,這有助於調試並防止進入無限循環
counter = 0
newline_character = char_to_ix["\n"]
while (idx != newline_character and counter < 50):
# 步驟2:使用公式1、2、3進行前向傳播
a = np.tanh(np.dot(Wax, x) + np.dot(Waa, a_prev) + b)
z = np.dot(Wya, a) + by
y = softmax(z)
# 設定隨機種子
np.random.seed(counter + seed)
# 步驟3:從概率分布y中抽取詞匯表中字符的索引
idx = np.random.choice(list(range(vocab_size)), p=y.ravel())
# 添加到索引中
indices.append(idx)
# 步驟4:將輸入字符重寫為與采樣索引對應的字符.
x = np.zeros((vocab_size,1))
x[idx] = 1
# 更新a_prev為a
a_prev = a
# 累加器
seed += 1
counter +=1
if(counter == 50):
indices.append(char_to_ix["\n"])
return indices
np.random.seed(2)
_, n_a = 20, 100
Wax, Waa, Wya = np.random.randn(n_a, vocab_size), np.random.randn(n_a, n_a), np.random.randn(vocab_size, n_a)
b, by = np.random.randn(n_a, 1), np.random.randn(vocab_size, 1)
parameters = {
"Wax": Wax, "Waa": Waa, "Wya": Wya, "b": b, "by": by}
indices = sample(parameters, char_to_ix, 0)
print("Sampling:")
print("list of sampled indices:", indices)
print("list of sampled characters:", [ix_to_char[i] for i in indices])
Sampling:
list of sampled indices: [12, 17, 24, 14, 13, 9, 10, 22, 24, 6, 13, 11, 12, 6, 21, 15, 21, 14, 3, 2, 1, 21, 18, 24, 7, 25, 6, 25, 18, 10, 16, 2, 3, 8, 15, 12, 11, 7, 1, 12, 10, 2, 7, 7, 11, 17, 24, 12, 12, 0, 0]
list of sampled characters: ['l', 'q', 'x', 'n', 'm', 'i', 'j', 'v', 'x', 'f', 'm', 'k', 'l', 'f', 'u', 'o', 'u', 'n', 'c', 'b', 'a', 'u', 'r', 'x', 'g', 'y', 'f', 'y', 'r', 'j', 'p', 'b', 'c', 'h', 'o', 'l', 'k', 'g', 'a', 'l', 'j', 'b', 'g', 'g', 'k', 'q', 'x', 'l', 'l', '\n', '\n']
It's time to build letter-level language models for text generation.
在本部分中,you will implement a function,This function performs one step of stochastic gradient descent(梯度裁剪).You will look at one training example at a time,So the optimization algorithm is stochastic gradient descent.提醒一下,以下是RNNCommon optimization loop steps:
練習:Implement this optimization process(One step of stochastic gradient descent).
Let's implement this optimization process(One-step stochastic gradient descent),Here we provide some functions:
# 示例,請勿執行.
def rnn_forward(X, Y, a_prev, parameters):
""" 通過RNN進行前向傳播,計算交叉熵損失. It returns the value of the loss along with the stored value used in backpropagation“緩存”值. """
....
return loss, cache
def rnn_backward(X, Y, parameters, cache):
""" Back propagation through time,Calculate the gradient loss compared to the parameters.It also returns all hidden states """
...
return gradients, a
def update_parameters(parameters, gradients, learning_rate):
""" 使用梯度下降更新參數 """
...
return parameters
Let's build the optimization function:
def optimize(X, Y, a_prev, parameters, learning_rate = 0.01):
""" 執行訓練模型的單步優化. 參數: X -- 整數列表,其中每個整數映射到詞匯表中的字符. Y -- 整數列表,與X完全相同,但向左移動了一個索引. a_prev -- 上一個隱藏狀態 parameters -- 字典,包含了以下參數: Wax -- 權重矩陣乘以輸入,維度為(n_a, n_x) Waa -- 權重矩陣乘以隱藏狀態,維度為(n_a, n_a) Wya -- 隱藏狀態與輸出相關的權重矩陣,維度為(n_y, n_a) b -- 偏置,維度為(n_a, 1) by -- 隱藏狀態與輸出相關的權重偏置,維度為(n_y, 1) learning_rate -- 模型學習的速率 返回: loss -- 損失函數的值(交叉熵損失) gradients -- 字典,包含了以下參數: dWax -- 輸入到隱藏的權值的梯度,維度為(n_a, n_x) dWaa -- 隱藏到隱藏的權值的梯度,維度為(n_a, n_a) dWya -- 隱藏到輸出的權值的梯度,維度為(n_y, n_a) db -- 偏置的梯度,維度為(n_a, 1) dby -- 輸出偏置向量的梯度,維度為(n_y, 1) a[len(X)-1] -- 最後的隱藏狀態,維度為(n_a, 1) """
# 前向傳播
loss, cache = rnn_forward(X, Y, a_prev, parameters)
# 反向傳播
gradients, a = rnn_backward(X, Y, parameters, cache)
# 梯度修剪,[-5 , 5]
gradients = clip(gradients,5)
# 更新參數
parameters = update_parameters(parameters,gradients,learning_rate)
return loss, gradients, a[len(X)-1]
np.random.seed(1)
vocab_size, n_a = 27, 100
a_prev = np.random.randn(n_a, 1)
Wax, Waa, Wya = np.random.randn(n_a, vocab_size), np.random.randn(n_a, n_a), np.random.randn(vocab_size, n_a)
b, by = np.random.randn(n_a, 1), np.random.randn(vocab_size, 1)
parameters = {
"Wax": Wax, "Waa": Waa, "Wya": Wya, "b": b, "by": by}
X = [12,3,5,11,22,3]
Y = [4,14,11,22,25, 26]
loss, gradients, a_last = optimize(X, Y, a_prev, parameters, learning_rate = 0.01)
print("Loss =", loss)
print("gradients[\"dWaa\"][1][2] =", gradients["dWaa"][1][2])
print("np.argmax(gradients[\"dWax\"]) =", np.argmax(gradients["dWax"]))
print("gradients[\"dWya\"][1][2] =", gradients["dWya"][1][2])
print("gradients[\"db\"][4] =", gradients["db"][4])
print("gradients[\"dby\"][1] =", gradients["dby"][1])
print("a_last[4] =", a_last[4])
Loss = 126.50397572165362
gradients["dWaa"][1][2] = 0.19470931534720892
np.argmax(gradients["dWax"]) = 93
gradients["dWya"][1][2] = -0.007773876032003782
gradients["db"][4] = [-0.06809825]
gradients["dby"][1] = [0.01538192]
a_last[4] = [-1.]
Given a dataset of dinosaur names,We will each row of the data set(一個名稱)as a training example.每100步隨機梯度下降,you will sample10randomly chosen names,to see the algorithm in action.Remember to shuffle the dataset,so that stochastic gradient descent accesses the examples in random order.
練習:Follow the instructions and implementmodel().當examples[index]contains a dinosaur name(字符串)時,創建示例(X,Y),可以使用以下方法:
index = j % len(examples)
X = [None] + [char_to_ix[ch] for ch in examples[index]]
Y = X[1:] + [char_to_ix["\n"]]
注意,我們使用:index= j % len(examples),其中j = 1....num_iterations,以確保examples[index]always a valid statement(index小於len(examples)).X的第一個條目為None將被rnn_forward()interpreted as setting x * 0 * = 0 ⃗ x^{\langle 0 \rangle} = \vec{0} x*0*=0.此外,這確保了Y等於X,But the move is a step to the left,並附加了“\n”ends with the name of a dinosaur.
def model(data, ix_to_char, char_to_ix, num_iterations=3500,
n_a=50, dino_names=7,vocab_size=27):
""" 訓練模型並生成恐龍名字 參數: data -- 語料庫 ix_to_char -- 索引映射字符字典 char_to_ix -- 字符映射索引字典 num_iterations -- 迭代次數 n_a -- RNN單元數量 dino_names -- 每次迭代中采樣的數量 vocab_size -- 在文本中的唯一字符的數量 返回: parameters -- 學習後了的參數 """
# 從vocab_size中獲取n_x、n_y
n_x, n_y = vocab_size, vocab_size
# 初始化參數
parameters = initialize_parameters(n_a, n_x, n_y)
# 初始化損失
loss = get_initial_loss(vocab_size, dino_names)
# 構建恐龍名稱列表
with open("datasets/dinos.txt") as f:
examples = f.readlines()
examples = [x.lower().strip() for x in examples]
# 打亂全部的恐龍名稱
np.random.seed(0)
np.random.shuffle(examples)
# 初始化LSTM隱藏狀態
a_prev = np.zeros((n_a,1))
# 循環
for j in range(num_iterations):
# 定義一個訓練樣本
index = j % len(examples)
X = [None] + [char_to_ix[ch] for ch in examples[index]]
Y = X[1:] + [char_to_ix["\n"]]
# 執行單步優化:前向傳播 -> 反向傳播 -> 梯度修剪 -> 更新參數
# 選擇學習率為0.01
curr_loss, gradients, a_prev = optimize(X, Y, a_prev, parameters)
# 使用延遲來保持損失平滑,這是為了加速訓練.
loss = smooth(loss, curr_loss)
# 每2000次迭代,通過sample()生成“\n”字符,檢查模型是否學習正確
if j % 2000 == 0:
print("第" + str(j+1) + "次迭代,損失值為:" + str(loss))
seed = 0
for name in range(dino_names):
# 采樣
sampled_indices = sample(parameters, char_to_ix, seed)
print_sample(sampled_indices, ix_to_char)
# 為了得到相同的效果,隨機種子+1
seed += 1
print("\n")
return parameters
#開始時間
start_time = time.clock()
#開始訓練
parameters = model(data, ix_to_char, char_to_ix, num_iterations=35000)
#結束時間
end_time = time.clock()
#計算時差
minium = end_time - start_time
print("執行了:" + str(int(minium / 60)) + "分" + str(int(minium%60)) + "秒")
第1次迭代,損失值為:23.087336085484605
Nkzxwtdmfqoeyhsqwasjkjvu
Kneb
Kzxwtdmfqoeyhsqwasjkjvu
Neb
Zxwtdmfqoeyhsqwasjkjvu
Eb
Xwtdmfqoeyhsqwasjkjvu
第2001次迭代,損失值為:27.884160491415777
Liusskeomnolxeros
Hmdaairus
Hytroligoraurus
Lecalosapaus
Xusicikoraurus
Abalpsamantisaurus
Tpraneronxeros
第4001次迭代,損失值為:25.90181489335302
Mivrosaurus
Inee
Ivtroplisaurus
Mbaaisaurus
Wusichisaurus
Cabaselachus
Toraperlethosdarenitochusthiamamumamaon
第6001次迭代,損失值為:24.608778900832394
Onwusceomosaurus
Lieeaerosaurus
Lxussaurus
Oma
Xusteonosaurus
Eeahosaurus
Toreonosaurus
第8001次迭代,損失值為:24.070350147705277
Onxusichepriuon
Kilabersaurus
Lutrodon
Omaaerosaurus
Xutrcheps
Edaksoje
Trodiktonus
第10001次迭代,損失值為:23.84444646002657
Onyusaurus
Klecalosaurus
Lustodon
Ola
Xusodonia
Eeaeosaurus
Troceosaurus
第12001次迭代,損失值為:23.291971267939104
Onyxosaurus
Kica
Lustrepiosaurus
Olaagrraiansaurus
Yuspangosaurus
Eealosaurus
Trognesaurus
第14001次迭代,損失值為:23.38233761730599
Meutromodromurus
Inda
Iutroinatorsaurus
Maca
Yusteratoptititan
Ca
Troclosaurus
第16001次迭代,損失值為:23.28294611567149
Mdyusaurus
Indaacosaupisaurus
Justolong
Maca
Yuspandosaurus
Cabaspadantes
Trodon
第18001次迭代,損失值為:22.85081326872384
Phyusaurus
Meja
Mystoosaurus
Pegamosaurus
Yusmaphosaurus
Eiahosaurus
Trolonosaurus
第20001次迭代,損失值為:22.929325599583475
Nlyusaurus
Logbalosaurus
Lvuslangosaurus
Necalosaurus
Ytrrangosaurus
Ekairus
Troenesaurus
第22001次迭代,損失值為:22.760728439539477
Onvusaroglolonoshareimus
Llecaerona
Myrrocephoeurus
Pedacosaurus
Ytrodonosaurus
Eiadosaurus
Trodonosaurus
第24001次迭代,損失值為:22.57720843347023
Meustrhe
Inca
Jurrollesaurus
Medaislleamlis
Yusaurus
Cabasigaansaurus
Trocerator
第26001次迭代,損失值為:22.616434369927045
Onyxosaurus
Lelealosaurus
Lustolialneusaurns
Olaahus
Yusichesaurus
Ehairuodan
Trochenomusaurus
第28001次迭代,損失值為:22.52468955468878
Meutosaurus
Kracafosaurus
Lvtosaurus
Necaisaurus
Yusiadgosaurus
Eiadosaurus
Trocephicrisaurus
第30001次迭代,損失值為:22.719787638280476
Peutroknethithosaurus
Llacalosaurus
Lutroenator
Pacalosaurus
Yusolonosaurus
Edacosaurus
Trocheshathystatepiscaptiuiman
第32001次迭代,損失值為:22.23296009953549
Meustrathus
Kojcanosaurus
Lustrasaurus
Macalosaurus
Yusiandon
Eeainor
Usianatorsaurus
第34001次迭代,損失值為:22.318447496893175
Olusaurus
Klacaesaurus
Lusnsaurus
Ola
Ytosaurus
Egaisaurus
Trhangosaurus
執行了:0分38秒
d:\vr\virtual_environment\lib\site-packages\ipykernel_launcher.py:8: DeprecationWarning: time.clock has been deprecated in Python 3.3 and will be removed from Python 3.8: use time.perf_counter or time.process_time instead
你可以看到,near the end of training,Your algorithm has started generating plausible dinosaur names.剛開始時,it generates random characters,但是到最後,You'll see cool endings in dinosaur names.For a longer time to run the algorithm,and tune the hyperparameters to see if you can get better results.Our implementation produces some really cool names,例如“maconucon”,“marloralus”和“macingsersaurus”.Your model is also expected to learn that dinosaur names often start withsaurus,don,aura,tor等結尾.
If your model generates some uncool names,Please don't fully blame the model-Not all actual dinosaur names sound cool.(例如,dromaeosauroidesis the name of an actual dinosaur,and also in the training set.)But this model should give you a set of candidate names to pick from!
The job uses a relatively small dataset,因此你可以在CPU上快速訓練RNN.Training an English model requires a larger dataset,and usually requires more computation,在GPUrun for many hours.We've been using dinosaur names for a while now,到目前為止,Our favorite names aregreat, undefeatable,且fierce的:Mangosaurus!
The rest of the notebook is optional,Has yet to score,but we want you to try it,Because it's very interesting and informative.
一個類似(但更復雜)The task is to generate Shakespeare poetry.No need to learn from a dataset of dinosaur names,Instead use Shakespeare's poetry.使用LSTM單元,You can learn long-term dependencies across many characters in the text.例如,The appearance of a character somewhere in the sequence may affect other characters following the sequence.These long-term dependencies for the dinosaur names is not very important,because their names are short.
Let us become a poet!
我們已經用KerasImplemented Shakespeare Poetry Generator.Run the following cells to load the required packages and models.這可能需要幾分鐘的時間.
from __future__ import print_function
from keras.callbacks import LambdaCallback
from keras.models import Model, load_model, Sequential
from keras.layers import Dense, Activation, Dropout, Input, Masking
from keras.layers import LSTM
from keras.utils.data_utils import get_file
from keras.preprocessing.sequence import pad_sequences
from shakespeare_utils import *
import sys
import io
Using TensorFlow backend.
Loading text data...
Creating training set...
number of training examples: 31412
Vectorizing training set...
Loading model...
WARNING:tensorflow:From d:\vr\virtual_environment\lib\site-packages\tensorflow_core\python\ops\resource_variable_ops.py:1630: calling BaseResourceVariable.__init__ (from tensorflow.python.ops.resource_variable_ops) with constraint is deprecated and will be removed in a future version.
Instructions for updating:
If using Keras pass *_constraint arguments to layers.
WARNING:tensorflow:From d:\vr\virtual_environment\lib\site-packages\tensorflow_core\python\ops\math_grad.py:1424: where (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.where in 2.0, which has the same broadcast rule as np.where
WARNING:tensorflow:From d:\vr\virtual_environment\lib\site-packages\keras\backend\tensorflow_backend.py:422: The name tf.global_variables is deprecated. Please use tf.compat.v1.global_variables instead.
d:\vr\virtual_environment\lib\site-packages\keras\engine\saving.py:384: UserWarning: Error in loading the saved optimizer state. As a result, your model is starting with a freshly initialized optimizer.
warnings.warn('Error in loading the saved optimizer '
為了節省你的時間,We already have in Shakespeare's sonnets"The Sonnets"Trained on poetry collections for approx.1000個epoch的模型.
Let's retrain the model to complete a newepoch,This will also take a few minutes.你可以運行generate_output,This will prompt you to enter less than40個字符的句子.The poem will start with the sentence you typed,我們的RNN-Shakespearewill do the rest for you!例如,嘗試"Forsooth this maketh no sense "(不要輸入引號).Depending on whether or not to add a space at the end,Your results may also vary,Both methods should be tried,You can also try other input methods.
print_callback = LambdaCallback(on_epoch_end=on_epoch_end)
model.fit(x, y, batch_size=128, epochs=1, callbacks=[print_callback])
Epoch 1/1
31412/31412 [==============================] - 31s 992us/step - loss: 2.7320
<keras.callbacks.callbacks.History at 0x20c382edb38>
# 運行此代碼嘗試不同的輸入,而不必重新訓練模型.
generate_output() # blogger input"Forsooth this maketh no sense"
Write the beginning of your poem, the Shakespeare machine will complete it. Your input is: Forsooth this maketh no sense
Here is your poem:
Forsooth this maketh no senses,
sin love that hiss of o no crusth,
and doth my berod fear i be two deared,
the hames for sichn three from when his biml age,
when thene his frotery i con dost,
whone knife whace a haor wor, wire not so,
the mesters shound be for yet befanot dight,
i unding thy beauty holl o lide to vears,
and bu thy grint hapl a do before.
that i hast to cell i pand
co whot i womd do bester is have racpeated,
RNN-ShakespeareThe model is very similar to the one you built for the dinosaur name.唯一的區別是: