Automatically capture valuable information on the Internet ,
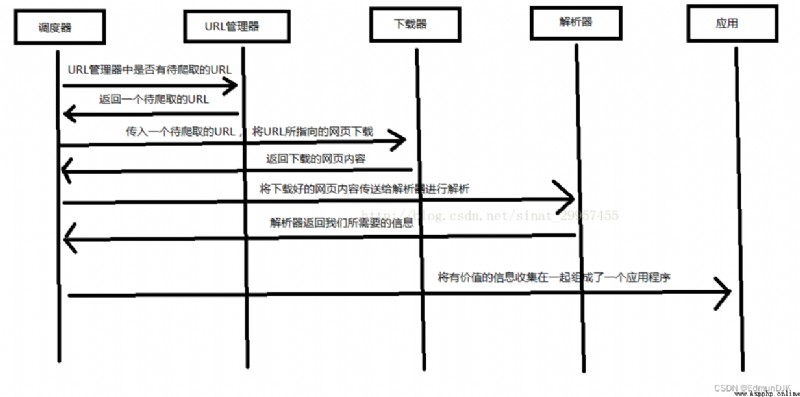
Scheduler 、URL Manager 、 Downloader 、 Parser 、 Applications
Scheduler # The equivalent of a computer CPU, Mainly responsible for dispatching URL Manager 、 Downloader 、 Coordination between parsers .
URL Manager # Including the ones to be crawled URL Address and crawled URL Address , Prevent repeated grabs URL And loop grabbing URL, Realization URL There are three main ways of manager , Through memory 、 data library 、 Cache the database to achieve
Web downloader # By passing in a URL Address to download the web page , Convert the web page to a string , The web downloader has urllib2(Python The official basic module ) Including the need to log in 、 agent 、 and cookie,requests( Third party package )
Parser #(html.parser,beautifulsoup,lxml) Parse a web page string , Extract useful information as required , According to the DOM The tree's parsing way to parse
Applications # An application composed of useful data extracted from web pages .
pip install requests
import requests
''' View the contents of the Library '''
print(dir(requests))
apparent_encoding # Encoding mode
encoding # decode r.text Coding method of
headers # Return response header , Dictionary format
history # Return the list of response objects containing the request history (url)
links # Return the parsing header link of the response
reason # Description of response status , such as "OK"
request # Return the request object requesting this response
url # Returns the URL
status_code # return http The status code , such as 404 and 200(200 yes OK,404 yes Not Found)
close() # Close the connection to the server
content # Returns the content of the response , In bytes
cookies # Return to one CookieJar object , Contains the message sent back from the server cookie
elapsed # Return to one timedelta object , Contains the amount of time elapsed between sending the request and the arrival of the response , It can be used to test the response speed . such as r.elapsed.microseconds Indicates how many microseconds it takes for the response to arrive .
is_permanent_redirect # If the response is permanently redirected url, Then return to True, Otherwise return to False
is_redirect # If the response is redirected , Then return to True, Otherwise return to False
iter_content() # Iterative response
iter_lines() # Iterate the response line
json() # Return the result of JSON object ( The result needs to be JSON formatted , Otherwise, it will lead to mistakes ) http://www.baidu.com/ajax/demo.json
next # Returns the next request in the redirection chain PreparedRequest object
ok # Check "status_code" Value , If it is less than 400, Then return to True, If not less than 400, Then return to False
raise_for_status() # If an error occurs , Method returns a HTTPError object
text # Returns the content of the response ,unicode Type data
Example :
import requests
# Send a request
a = requests.get('http://www.baidu.com')
print(a.text)
# return http The status code
print(a.status_code)
delete(url, args) # send out DELETE Request to specify url
get(url, params, args) # send out GET Request to specify url
head(url, args) # send out HEAD Request to specify url
patch(url, data, args) # send out PATCH Request to specify url
post(url, data, json, args) # send out POST Request to specify url
'''post() Method can send POST Request to specify url, The general format is as follows :'''
requests.post(url, data={
key: value}, json={
key: value}, args)
put(url, data, args) # send out PUT Request to specify url
request(method, url, args) # To specify the url Send the specified request method
Example :
a = requests.request('get','http://www.baidu.com/')
a = requests.post('http://www.baidu.com/xxxxx/1.txt')
requests.get(url)
requests.put(url)
requests.delete(url)
requests.head(url)
requests.options(url)
import requests
info = {
'frame':' Information '}
# Set request header
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# params Receive a dictionary or string query parameter , Dictionary type is automatically converted to url code , Unwanted urlencode()
response = requests.get("https://www.baidu.com/", params = info, headers = headers)
# Check the response status code
print (response.status_code)
# Check the response header character encoding
print (response.encoding)
# See the full url Address
print (response.url)
# View the response content ,response.text The return is Unicode Formatted data
print(response.text)
requests.Request # Represents the request object Used to prepare a request to be sent to the server
requests.Response # Represents the response object Include server pairs http Response to the request
requests.Session # Indicates a request session Provide cookie persistence 、 Connection pool ( The technology of creating and managing a connected buffer pool ) And configuration
Write to existing file
To write to an existing file , You have to go to open() Function add parameter :
"a" - Additional - Will be appended to the end of the file
"w" - write in - Will overwrite any existing content
Create a new file
If you need to be in Python Create a new file , Please use open() Method , And use one of the following parameters :
"x" - establish - A file will be created , If the file exists, an error is returned
"a" - Additional - If the specified file does not exist , A file will be created
"w" - write in - If the specified file does not exist , A file will be created
Example :( Use crawlers to write files )
import requests
f = open("C:/Users/ Jiuze /Desktop/demo.txt", "w",encoding='utf-8')
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
response = requests.get("https://www.baidu.com/",headers = headers)
f.write(response.content.decode('utf-8'))

os Module provides a very rich way to handle files and directories
Rookie tutorial address =========>>>>>>https://www.runoob.com/
Provided by rookie tutorial
https://www.runoob.com/python/os-file-methods.html
Example :
import requests
import os
url="xxxxxxxxxxxxxxxxxxxxxxxxx"
compile="C:/Users/ Jiuze /Desktop/imgs/"
path=compile + url.split('/')[-1]
try:
if not os.path.exists(compile):
os.mkdir(compile)
if not os.path.exists(path):
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'
}
rr=requests.get(url=url,headers=headers)
with open(path,'wb') as f:
f.write(rr.content)
f.close()
print(' File saved successfully !')
else:
print(' file already exist !!')
except:
print(" Crawling failed !!!")
To extract xml and HTML Data in
Get... In the source code title Label content
title.name # Get the tag name
title.string # obtain string Type character
title.parent.string # Get the parent tab
** Example :** obtain html Of p label
import requests
from bs4 import BeautifulSoup
r = requests.get("http://www.baidu.com")
n = r.content
m = BeautifulSoup(n,"html.parser")
for i in m.find_all("p"): # find_all() Get all the contents of a specified label in the source code
with open('C:/Users/ Jiuze /Desktop/imgs/2.txt','w+',encoding='utf-8') as f:
f.write(str(i))
f.close()
** Example :** Use regular expressions to output p label
import requests
import re
from bs4 import BeautifulSoup
r = requests.get("http://www.baidu.com")
n = r.content
m = BeautifulSoup(n,"html.parser")
for tag in m.find_all(re.compile("^p")):
with open('C:/Users/ Jiuze /Desktop/imgs/1.txt','w+',encoding='utf-8') as f:
f.write(str(tag))
f.close()
print(' Climb to success !')
#-*-coding:utf-8 -*-
import requests
import re
import time
headers ={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'
}
f=open('C:/Users/ Jiuze /Desktop/imgs/dpcq.txt','a+')
def get_info(url):
res = requests.get(url,headers=headers)
if(res.status_code==200):
contents=re.findall('<p>(.*?)<p>',res.content.decode('utf-8'),re.S) #re.S Input special characters
for content in contents:
f.write(content + '\n')
else:
pass
if __name__ =='__main__':
urls=['http://www.doupoxs.com/doupocangqiong/{}.html'.format(str(i)) for i in range(1,200)]
for url in urls:
get_info(url)
time.sleep(1)
f.close()
import requests
from bs4 import BeautifulSoup
r=requests.get("http://www.baidu.com")
m=r.content
n= BeautifulSoup(m,"html.parser")
print(n)
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import re
from bs4 import BeautifulSoup
html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """
# Create a BeautifulSoup Parse object
soup = BeautifulSoup(html_doc,"html.parser",from_encoding="utf-8")
# Get all the links
links = soup.find_all('a')
print " All links "
for link in links:
print link.name,link['href'],link.get_text()
print " Get specific URL Address "
link_node = soup.find('a',href="http://example.com/elsie")
print link_node.name,link_node['href'],link_node['class'],link_node.get_text()
print " Regular Expression Matching "
link_node = soup.find('a',href=re.compile(r"ti"))
print link_node.name,link_node['href'],link_node['class'],link_node.get_text()
print " obtain P The text of the paragraph "
p_node = soup.find('p',class_='story')
print p_node.name,p_node['class'],p_node.get_text()
urllib Libraries are used to manipulate web pages URL, And grab the content of the web page
grammar :
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
url: #url Address .
data: # Other data objects sent to the server , The default is None.
timeout: # Set access timeout .
cafile and capath: #cafile by CA certificate , capath by CA Path to certificate , Use HTTPS Need to use .
cadefault: # It has been deprecated .
context: #ssl.SSLContext type , Used to specify SSL Set up
urllib.robotparser # analysis robots.txt file
urllib.request # open / Read url
urllib.parse # analysis url
urllib.error # contain urllib.request Exception thrown .
readline() # Read a line from the file
readlines() # Read the entire contents of the file , It assigns the read content to a list variable
Example :
from urllib import request
file = request.urlopen('http://www.baidu.com')
data = file.read()
f= open('C:/Users/ Jiuze /Desktop/2.html','wb')
f.write(data)
f.close()
Scrapy Yes, it is Python The implementation of a web site in order to crawl data 、 Application framework for extracting structural data .
Scrapy Often used in including data mining , In a series of programs that process or store historical data .
Usually we can simply pass Scrapy The framework implements a crawler , Grab the content or pictures of the specified website .
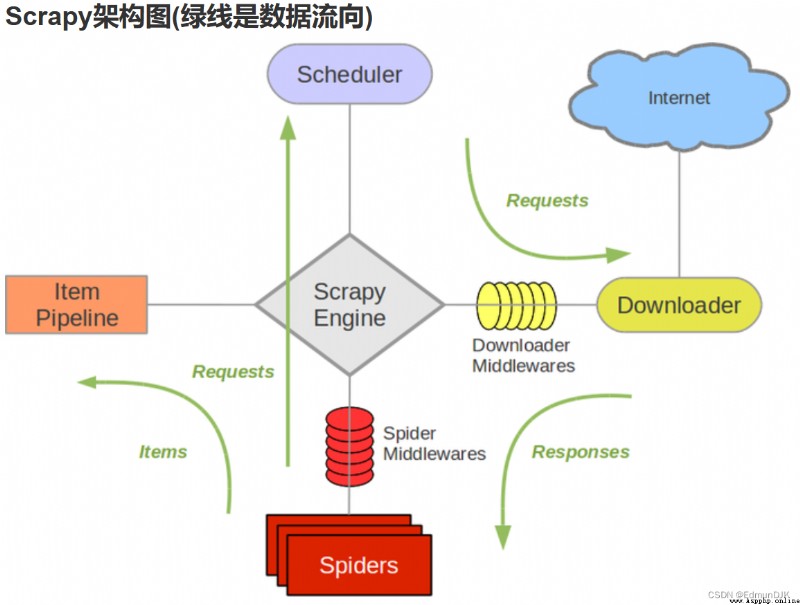
engine # be responsible for Spider、ItemPipeline、Downloader、Scheduler Intermediate communication , The signal 、 Data transfer, etc
Scheduler # Responsible for receiving the engine sent Request request , And in accordance with a certain way to arrange the arrangement , The team , When the engine needs , Give it back to the engine
Downloader # Responsible for downloading all messages sent by the engine Requests request , And get it Responses Give it back to the engine , Engine to Spider To deal with it
Reptiles # Take care of all Responses, Analyze and extract data from it , obtain Item The data required for the field , And will need to follow up URL Submit to engine , Enter the scheduler again
The Conduit # Responsible for handling Spider Obtained in Item, And carry out post-processing ( Detailed analysis 、 Filter 、 Storage, etc ) The place of
middleware # A custom extension and operation engine and Spider Functional components of intermediate communication
Download Middleware # Think of it as a component that you can customize to extend the download functionality
Make Scrapy Steps for :
New projects (scrapy startproject xxx): Create a new crawler project
Clear objectives ( To write items.py): Identify the goals you want to capture
Making reptiles (spiders/xxspider.py): Make a crawler to start crawling the web
Store content (pipelines.py): Design pipeline to store crawling content
scrapy startproject mySpider # Create a mySpider New projects
scrapy genspider mySpider
mySpider/
scrapy.cfg
mySpider/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
scrapy.cfg: # The configuration file for the project .
mySpider/: # Project Python modular , The code will be referenced from here .
mySpider/items.py: # The project's target file .
mySpider/pipelines.py: # Pipeline files for the project .
mySpider/settings.py: # The setup file for the project .
mySpider/spiders/: # Store crawler code directory .
open mySpider In the catalog items.py
Item Define structured data fields , Used to save crawled data , It's kind of like Python Medium dict, But it provides some extra protection to reduce errors .
You can do this by creating a scrapy.Item class , And the definition type is scrapy.Field Class property to define a Item( It can be understood as similar to ORM The mapping relation of ).
Next , Create a ItcastItem class , And build item Model (model)
import scrapy
class ItcastItem(scrapy.Item):
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()
Enter a command in the current directory , Will be in mySpider/spider Create a directory called itcast The reptiles of , And specify the scope of the crawl domain :
scrapy genspider itcast "itcast.cn"
open mySpider/spider In the directory itcast.py, The following code has been added by default :
import scrapy
class ItcastSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["www.itcast.cn"]
start_urls = (
'http://www.itcast.cn/channel/teacher.shtml',
)
def parse(self, response):
pass
take start_urls The value of is changed to the first one that needs to be crawled url:
start_urls = ("http://www.itcast.cn/channel/teacher.shtml",)
modify parse() Method :
def parse(self, response):
filename = "teacher.html"
open(filename, 'w').write(response.body)
And then run , stay mySpider Execute under directory :
scrapy crawl itcast
Specify the encoding format for saving content
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
Crawling through the entire page is finished , The next step is to take the process , First look at the page source code :
<div class="li_txt">
<h3> xxx </h3>
<h4> xxxxx </h4>
<p> xxxxxxxx </p>
xpath Method , We only need to input xpath Rules can be located to the corresponding html Tag node :
Parameters :
/html/head/title: choice HTML In the document <head> Inside the label <title> Elements
/html/head/title/text(): Choose the one mentioned above <title> The text of the element
//td: Choose all <td> Elements
//div[@class="mine"]: Select all of them with class="mine" Attribute div Elements
modify itcast.py The document code is as follows :
# -*- coding: utf-8 -*-
import scrapy
class Opp2Spider(scrapy.Spider):
name = 'itcast'
allowed_domains = ['www.itcast.cn']
start_urls = ['http://www.itcast.cn/channel/teacher.shtml']
def parse(self, response):
# Get website title
context = response.xpath('/html/head/title/text()')
# Extract Website Title
title = context.extract_first()
print(title)
pass
Execute the following command :
scrapy crawl itcast
stay mySpider/items.py There is a definition of ItcastItem class . Here we introduce :
from mySpider.items import ItcastItem
Then we encapsulate the data we get into a ItcastItem In the object , You can save the properties of each :
import scrapy
from mySpider.items import ItcastItem
def parse(self, response):
#open("teacher.html","wb").write(response.body).close()
# A collection of teacher information
items = []
for each in response.xpath("//div[@class='li_txt']"):
# Encapsulate the data we get into a `ItcastItem` object
item = ItcastItem()
#extract() Method returns all of unicode character string
name = each.xpath("h3/text()").extract()
title = each.xpath("h4/text()").extract()
info = each.xpath("p/text()").extract()
#xpath It returns a list of elements
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
items.append(item)
# Return the final data directly
return items
scrapy There are four simple ways to save information ,-o Output file in specified format , The order is as follows :
scrapy crawl itcast -o teachers.json
json lines Format , The default is Unicode code
scrapy crawl itcast -o teachers.jsonl
csv Comma expression , You can use Excel open
scrapy crawl itcast -o teachers.csv
xml Format
scrapy crawl itcast -o teachers.csv
name = "" : The identifying name of this crawler , Must be unique , Different names must be defined in different crawlers .
allow_domains = [] Is the domain name range of the search , That's the constraint area of the crawler , The crawler only crawls the web page under this domain name , There is no the URL Will be ignored .
start_urls = () : The crawl URL Yuan Zu / list . This is where the crawler starts to grab data , therefore , The first download of data will come from these urls Start . Other children URL It will come from these start URL In inheritance generation .
parse(self, response) : The method of analysis , Each initial URL When the download is complete, it will be called , Call when passed in from each URL Back to the Response Object as the only parameter , The main functions are as follows :
1. Responsible for parsing the returned web page data (response.body), Extract structured data ( Generate item)
2. Generate... That requires the next page URL request .
( This failed, so there is no specific content to crawl out ) change another one
We learned from the website ([https://so.gushiwen.cn/shiwenv_4c5705b99143.aspx](javascript:void(0))) Crawl through the title and verse of this poem , Then save it in our folder ,
scrapy startproject poems
scrapy genspider verse www.xxx.com
Open the crawler file ’verse‘, Change the web address that needs to be crawled
import scrapy
class VerseSpider(scrapy.Spider):
name = 'verse'
# allowed_domains = ['www.xxx.com']
start_urls = ['www.xxx.com']
change parse The analysis part , For the obtained data (response) Data analysis , The parsing method used is xpath analysis , Methods and requests The parsing method of sending requests is similar , First, find the part we need to parse , And fill in the corresponding code ( Here's the picture ). We found that , And requests The difference in the parsing method of sending requests is , Add... To the original basis extract Method , and join Method to get text information
title = response.xpath('//div[@class="cont"]/h1/text()').extract()
content = response.xpath('//div[@id=contson4c5705b99143]/text()').extract()
title = ''.join(content)
To save data, we need parse The module has a return value , Let's create an empty list first data, Then we will title and content Put it in the dictionary and add it to the list
import scrapy
class VerseSpider(scrapy.Spider):
name = 'verse'
allowed_domains = ['https://so.gushiwen.cn/']
start_urls = ['https://so.gushiwen.cn/shiwenv_4c5705b99143.aspx/']
def parse(self, response):
data = []
title = response.xpath('//*[@id="sonsyuanwen"]/div[1]/h1').extract()
content = response.xpath('//div[@id=contson4c5705b99143]/text()').extract()
title = ''.join(title)
content=''.join(content)
dic = {
'title': title, 'content': content
}
data.append(dic)
return data
Still save with instructions :scrapy +crawl+ Crawler file name ±o+ Save the path , The final result is as follows :
scrapy crawl verse -o ./verse.csv