nlp Adorable new , I'm trying one recently AIDD Project , During this period, I encountered an interesting problem , When turning from zinc,enamine,ChemBL,CDDI When the data collected in the library is merged , It's a 60 many G Of txt file , Yes , You are right ,60 many G Of txt, Hundreds of millions of lines . Indeed, as the literature says , The explorable chemical space can reach 10^80……
This kind of thing , The best way to deal with it should be distributed , use spark Cluster to handle ,pyspark There are many pandas Instructions . Due to the lack of available resources , Only use the most primitive method , Try to simplify time as much as possible .
First, on data reading , There's a problem , The initial operation was very fierce , Sixty something G The data of , Direct reading , result ……
After waiting for a long time , It broke down 
It's really difficult pandas 了 , It's all my fault ……
Next , Had to embark on a similar method of repayment in installments , Cut the data into pieces 500M Each small file , And then one by one .
The cutting data command line is as follows :
# Be arrogant , Fifty million lines of a document (ps: If only it were money )
split -l 50000000 *.txtthis is it , A large file is cut into dozens of small files .
My file contains only one smiles code , Next , need RDKit And Moses Package , In order to obtain weight,logP,SA,QED And other molecular information .
import os
import pandas as pd
# Show all columns ( Parameter set to None Represents the display of all lines , You can also set your own number )
pd.set_option('display.max_columns',None)
# Show all lines
pd.set_option('display.max_rows',None)
# Set the display length of the data , The default is 50
pd.set_option('max_colwidth',200)
# No word wrap ( Set to Flase Don't wrap ,True conversely )
pd.set_option('expand_frame_repr', False)
from rdkit import rdBase, Chem
from rdkit.Chem import PandasTools, Descriptors, rdMolDescriptors, MolFromSmiles
from moses.metrics import QED, SA, logP, weight,mol_passes_filters
import time
# analysis smiles Parameters
inputdir = r'./data/dataset'
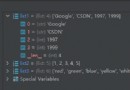
data = pd.DataFrame(columns = ['smiles','weight','logP','mol_passes_filters','get_n_rings'
,'SA','QED'])
data_all = pd.DataFrame(columns = ['smiles','weight','logP','mol_passes_filters','get_n_rings'
,'SA','QED'])
for parents,dirnames,filenames in os.walk(inputdir):
for filename in filenames:
df = pd.read_csv(os.path.join(parents,filename))
df.columns = ['smiles']
start = time.time()
data['weight'] = df['smiles'].apply(lambda x: weight(Chem.MolFromSmiles(x)))
data['logP'] = df['smiles'].apply(lambda x: logP(Chem.MolFromSmiles(x)))
data['SA'] = df['smiles'].apply(lambda x: SA(Chem.MolFromSmiles(x)))
data['QED'] = df['smiles'].apply(lambda x:QED(Chem.MolFromSmiles(x)))
data['mol_passes_filters'] = df['smiles'].apply(lambda x:mol_passes_filters(x))
end = time.time()
print(end-start)
zinc_all = zinc_all.append(data,ignore_index=True)
data_all.to_csv('data_all.csv')
9388.264369010925
8503.865498304367
………………
………………
………………
………………Parse one file on average 9000s about , After it is parsed , Conan primary school has graduated …………
parallel 
On fool type multithreading function ——pandarallel, Let's start with two brief introductions :
The most simple pandas Multi process Method pandarallel - You know although Python It has its own package for implementing multi process and multi thread , But for pandas Chinese is not very easy to use , Actually pandas Have their own implementation of multi process package , Super easy to use . One 、 to see somebody for the first time pandarallel package GitHub - nalepae/pandarallel at v1.5.2 Two 、 Installation side … https://zhuanlan.zhihu.com/p/416002028GitHub - nalepae/pandarallel: A simple and efficient tool to parallelize Pandas operations on all available CPUs
https://zhuanlan.zhihu.com/p/416002028GitHub - nalepae/pandarallel: A simple and efficient tool to parallelize Pandas operations on all available CPUs https://github.com/nalepae/pandarallel First open a four thread game , The code is very simple , Code up :
https://github.com/nalepae/pandarallel First open a four thread game , The code is very simple , Code up :
import os
import pandas as pd
# Show all columns ( Parameter set to None Represents the display of all lines , You can also set your own number )
pd.set_option('display.max_columns',None)
# Show all lines
pd.set_option('display.max_rows',None)
# Set the display length of the data , The default is 50
pd.set_option('max_colwidth',200)
# No word wrap ( Set to Flase Don't wrap ,True conversely )
pd.set_option('expand_frame_repr', False)
from rdkit import rdBase, Chem
from rdkit.Chem import PandasTools, Descriptors, rdMolDescriptors, MolFromSmiles
from moses.metrics import QED, SA, logP, weight,mol_passes_filters
from pandarallel import pandarallel
pandarallel.initialize(nb_workers=4)
import time
inputdir = r'./data/dataset'
data = pd.DataFrame(columns = ['smiles','weight','logP','mol_passes_filters','get_n_rings'
,'SA','QED'])
dataset = pd.DataFrame(columns = ['smiles','weight','logP','mol_passes_filters','get_n_rings'
,'SA','QED'])
for parents,dirnames,filenames in os.walk(inputdir):
for filename in filenames:
df = pd.read_csv(os.path.join(parents,filename))
df.columns = ['smiles']
start = time.time()
data['weight'] = df['smiles'].parallel_apply(lambda x: weight(Chem.MolFromSmiles(x)))
data['logP'] = df['smiles'].parallel_apply(lambda x: logP(Chem.MolFromSmiles(x)))
data['SA'] = df['smiles'].parallel_apply(lambda x: SA(Chem.MolFromSmiles(x)))
data['QED'] = df['smiles'].parallel_apply(lambda x:QED(Chem.MolFromSmiles(x)))
data['mol_passes_filters'] = df['smiles'].parallel_apply(lambda x:mol_passes_filters(x))
end = time.time()
print(end-start)
dataset = dataset.append(data,ignore_index=True)
2621.7469606399536
……………………
……………………
……………………
……………………
A quarter of the time was saved , I'm going to open ten threads , Twenty threads have gone , toodles
ps: About the use of multithreading , Driving too little cannot achieve the best optimization , Driving too much may also be optimized , Last two blogs
It's done , The whole process takes about a day . Found this tutorial , It's really easy to use Use Python Pandas Processing 100 million data - Python - Development languages and tools - Deep open source
dried food | Python High concurrency scenario optimization solution developed in the background _Python Base camp blog -CSDN Blog The guest | Source of Huang Sihan | AI The Internet has developed to this day , It's getting bigger and bigger , It also puts forward higher requirements for all back-end services . In normal work , We have all experienced server pressure more or less ... https://blog.csdn.net/weixin_42232219/article/details/95131433?spm=1001.2101.3001.6650.11&utm_medium=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromBaidu~Rate-11.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromBaidu~Rate-11.pc_relevant_default&utm_relevant_index=16 Feige talks about code 9: Lifting performance , Just have the right number of threads - Lanling N Zi Ji Lanling N Zi Ji | Blog | Software | framework | Java | Golang
https://blog.csdn.net/weixin_42232219/article/details/95131433?spm=1001.2101.3001.6650.11&utm_medium=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromBaidu~Rate-11.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromBaidu~Rate-11.pc_relevant_default&utm_relevant_index=16 Feige talks about code 9: Lifting performance , Just have the right number of threads - Lanling N Zi Ji Lanling N Zi Ji | Blog | Software | framework | Java | Golang http://lanlingzi.cn/post/technical/2020/0718_code/
http://lanlingzi.cn/post/technical/2020/0718_code/