Bibliography :《 Explain profound theories in simple language Pandas: utilize Python Data processing and analysis 》
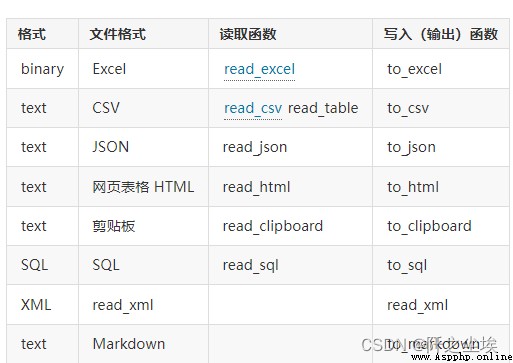
pandas It's really powerful , Almost any format of data Can read , what csv,excel,spss,stata,json,html...... Even the data on the clipboard can be read ..... This chapter teaches you how to read data , Although the simple reading is just one sentence , But there are still many parameters and functions , Have a look .
csv The most basic data file , The most detailed introduction , Because many parameters of other files and csv The reading methods are similar
import pandas as pd
import numpy as np
# File directory
pd.read_csv('data.csv') # If the file is in the same directory as the code file
pd.read_csv('D:\AAA Recent want to use \ Deep learning \ Own project \ Wind power generation \ A little less .csv') # Specify the directory
pd.read_csv('data\my\my.data') # CSV The file extension is not necessarily csv
# Use the web address url
pd.read_csv('https://www.gairuo.com/file/data/dataset/GDP-China.csv')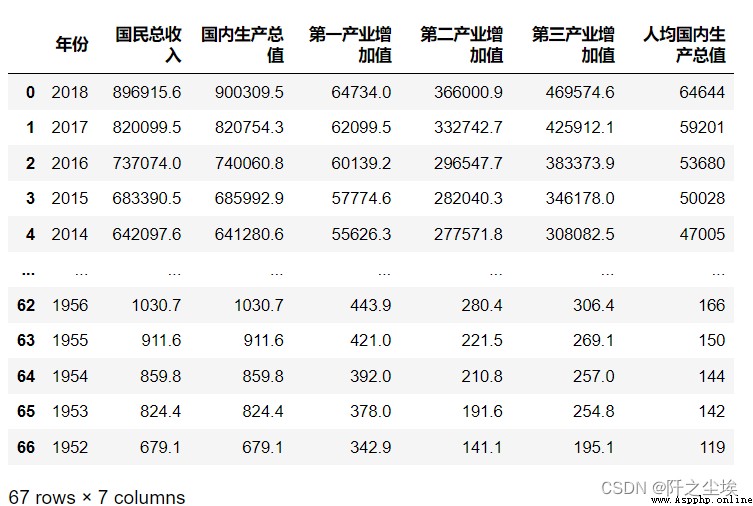
Read from the string
# You can also get it from StringIO Read from
from io import StringIO
data = ('col1,col2,col3\n'
'a,b,1\n'
'a,b,2\n'
'c,d,3')
pd.read_csv(StringIO(data)).to_csv('data.data',index=False) # Save it Separator
# Data separation conversion is comma , If it is others, you can specify
pd.read_csv('data.data', sep='\t') # Tab delimited tab
pd.read_table('data.data') # read_table The default is tab delimitation tab
pd.read_csv('data.data', sep='|') # Tab delimited tab
Specify column names and headers
# Specify column names and headers
pd.read_csv(data, header=0) # Default first line
pd.read_csv(data, header=None) # There is no meter
pd.read_csv(data, names=[' Column 1', ' Column 2']) # Specify a list of column names
pd.read_csv(data, names=[' Column 1', ' Column 2'],header=None) # Specify a list of column names
# If not listed , Automatically assign one : Prefix plus ordinal number
pd.read_csv(data, prefix='c_', header=None) # Header is c_0,c_1...Specify the index
# Specify the index
pd.read_csv(data,index_col=False) # Do not use the first column as an index
pd.read_csv(data,index_col=0) # Which column is the index
pd.read_csv(data,index_col=' year ')# Specifies the column name
pd.read_csv(data,index_col=['a','b']) # Multiple indexes
pd.read_csv(data,index_col=[0,3]) # Multiple index Read Partial Columns
# Read Partial Columns
pd.read_csv(data, usecols=[0,4,3]) # Read only the specified columns by index , The order is irrelevant
pd.read_csv(data, usecols=[' Column 1', ' Column 5']) # Read only the specified columns by index
# Specify the column order , It's actually df The screening function of
pd.read_csv(data, usecols=[' Column 1', ' Column 5'])[[' Column 5', ' Column 1']]
pd.read_csv(data, index_col=0) # Which column is the index
# The following is used callable The order can be cleverly specified , in Next is the order we want
pd.read_csv(data, usecols=lambda x: x.upper() in ['COL3', 'COL1'])Handle duplicate column names
# Handle duplicate column names
data='a,b,a\n0,1,2\n5,6,4'
pd.read_csv(StringIO(data),mangle_dupe_cols=True)
data type
# data type
data = 'https://www.gairuo.com/file/data/dataset/GDP-China.csv'
# Specify the data type
pd.read_csv(data, dtype=np.float64) # All data is of this data type
pd.read_csv(data, dtype={
'c1':np.float64, 'c2': str}).info() # Specify the type of field
pd.read_csv(data, dtype=[datetime,datetime,str,float]) # Specify in turn Skip the specified line
# Skip the specified line
pd.read_csv(data,skiprows=2) # Skip the first two lines
pd.read_csv(data,skiprows=range(2)) # Skip the first two lines
pd.read_csv(data,skiprows=[24,235,65]) # Skip the specified line
pd.read_csv(data,skiprows=np.array([24,235,65])) # Skip the specified line
pd.read_csv(data,skiprows=lambda x:x%2!=0) # Skip every other line
pd.read_csv(data,skipfooter=1) # Skip from the tail
pd.read_csv(data,skip_black_lines=True)# Skip empty lines Reads the specified number of rows
# Reads the specified number of rows
pd.read_csv(data,nrows=1000)Null value substitution
# Null value substitution
pd.read_csv(data,na_values=[0]) #0 It will be considered as missing value
pd.read_csv(data,na_values='?') #? It will be considered as missing value
pd.read_csv(data,na_values='abc') #abc Will be considered missing value Equivalent ['a','b','c']
pd.read_csv(data,na_values={'c':3,1:[2,5]}) # The specified column is specified as NaNParse date and time
# Parse date and time
data = 'D:/AAA Recent want to use / mathematical modeling /22 Mercer / data /LBMA-GOLD.csv'
pd.read_csv(data, parse_dates=True).info()# Automatically parse date and time format
pd.read_csv(data, parse_dates=['Date']).info() # Specify the date and time field to parse
# take 0,1,2 The column merge resolves to a name The time of the Time type column
pd.read_csv('D:/AAA Recent want to use / Deep learning / Own project / Wind power generation / A little less .csv', parse_dates={' Time ':[0,1,2]}).info()
# Keep the original column
pd.read_csv('D:/AAA Recent want to use / Deep learning / Own project / Wind power generation / A little less .csv', parse_dates={' Time ':[0,1,2]},keep_date_col=True).info()
# Data with date before month
pd.read_csv(data,dayfist=True,parse_dates=[0])# Specify the time resolution Library , The default is dateutil.parser.parser
date_parser=pd.io.date_converters.parse_date_time
date_parser=lambda x: pd.to_datetime(x, utc=True, format='%D%M%Y')
date_parser=lambda d: pd.datetime.strptime(d,'%d%b%Y')
pd.read_csv(data, date_parser=date_parser)
# Try converting to date
pd.read_csv(data, date_parser=date_parser,infer_datetime_format=True)Read compressed package
# Read compressed package
pd.read_csv('sample.tar.gz',compression='gzip')
# Specify the read encoding
pd.read_csv('gairuo.csv',encoding='utf-8')
pd.read_csv('gairuo.csv',encoding='gk2312')# chinese Symbol
# Symbol
pd.read_csv('test.csv',thousands=',')# The thousandth separator
pd.read_csv('test.csv',decimal=',,')# decimal point , Default '.'
pd.read_csv(StringIO(data),escapechar='\n',encoding='utf-8')# Filter line breaks
pd.read_csv(StringIO(s),sep=',',comment='#',skiprows=1) # The line has '#' Will skip df.to_csv('done.csv')
df.to_csv('data/done.csv') # You can specify the file directory path
df.to_csv('done.csv', index=False) # Don't index
f.to_csv('done.csv', encoding='utf-8') # Specified encoding
# You can also use sep Specify the separator
df.Q1.to_csv('Q1_test.txt', index=None) # Specify a column to export txt Format file Export compressed package
df=pd.read_csv('https://www.gairuo.com/file/data/dataset/GDP-China.csv')
# Create a containing out.csv The compressed file of out.zip
com_opts=dict(method='zip',archive_name='out.csv')
df.to_csv('out.zip',encoding='gbk',index=False,compression=com_opts)
excel You need this front-end package openpyxl
pd.read_excel('team.xlsx')
pd.read_excel('https://www.gairuo.com/file/data/dataset/team.xlsx')
excel Multiple tables sheet
#excel Multiple tables sheet
xlsx = pd.ExcelFile('data.xlsx')
df = pd.read_excel(xlsx, 'Sheet1') # Read
xlsx.parse('sheet1') # Take the specified label as DataFrame
# Excel All tags for
xlsx.sheet_names # ['sheet1', 'sheet2', 'sheet3', 'sheet4']Specify read sheet
# Specify read sheet
pd.read_excel('team.xlsx', sheet_name=1) # the second sheet
pd.read_excel('team.xlsx', sheet_name=' summary ') # name
# Read multiple sheet
pd.read_excel('team.xlsx', sheet_name=[0,1,'Sheet5'])# Read the first and second , The fifth one sheet, form df Dictionaries
dfs=pd.read_excel('team.xlsx', sheet_name=None) # all sheet
dfs['Sheet5']# Use ExcelFile Save file object
df.to_excel('file.xlsx',sheet_name='sheet2',index=False)Multiple sheet
df1=df.describe()
# You can put more than one Sheet Deposit in ExcelFile
with pd.ExcelWriter('path_to_file.xlsx') as xls:
df1.to_excel(xls, 'Sheet1')
df.to_excel(xls, 'Sheet2',index=False)
dfs = pd.read_html('https://www.gairuo.com/p/pandas-io')
dfs[0] # Look at the first one df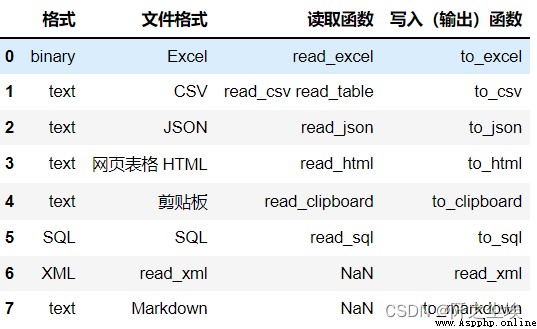
dfs = pd.read_html('data.html', header=0) # Read web files , The first line is the header
dfs = pd.read_html(url, index_col=0)# The first column is the index
# Many tables can specify elements to get
dfs1 = pd.read_html(url, attrs={'id': 'table'}) # id='table' Table for , Note that it is still possible to return multiple
# dfs1[0]
dfs2 = pd.read_html(url, attrs={'class': 'sortable'})# class='sortable'
# !!! Common functions and read_csv identical , Please refer to the above df.to_html(' Web page file .html')
df.to_html(' Web page file .html',columns=[0])# Output specified column
df.to_html(' Web page file .html',classes=['class1','class2'])# Output the specified style pd.read_json('data.json')
json = '''{"columns":["col 1","col 2"],
"index":["row 1","row 2"],
"data":[["a","b"],["c","d"]]}
'''
pd.read_json(json)
pd.read_json(json, orient='split') # json Format 
''' orient Support :
df = pd.DataFrame([['a', 'b'], ['c', 'd']],
index=['row 1', 'row 2'],
columns=['col 1', 'col 2'])
# Output json character string
df.to_json(orient='split')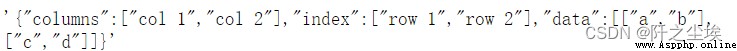
For example, I'll copy a data from Oriental Fortune :

And then in Python Input
pd.read_clipboard(header=None)You can get
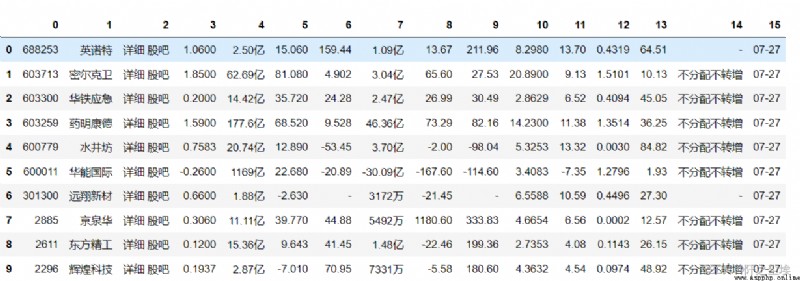
Very convenient
df = pd.DataFrame({'A': [1, 2, 3],
'B': [4, 5, 6],
'C': ['p', 'q', 'r']},
index=['x', 'y', 'z'])
df.to_clipboard()So we can take df Things have been copied everywhere
print(df.to_markdown())
Data analysis and spss file ,sas file ,stata Documents, etc. , Both can be used. pandas Read
pd.read_stata('file.dta')# Read stata file
pd.read_spss('file.sav')# Read spss file
pd.read_sas# Read sas
pd.read_sql# Read sql
# Read data with fixed column width
colspecs = [(0, 6), (8, 20), (21, 33), (34, 43)]
pd.read_fwf('demo.txt', colspecs=colspecs, header=None, index_col=0)