這兩年開始畢業設計和畢業答辯的要求和難度不斷提升,傳統的畢設題目缺少創新和亮點,往往達不到畢業答辯的要求,這兩年不斷有學弟學妹告訴學長自己做的項目系統達不到老師的要求。
為了大家能夠順利以及最少的精力通過畢設,學長分享優質畢業設計項目,今天要分享的是
基於python/大數據的疫情分析與可視化系統
學長這裡給一個題目綜合評分(每項滿分5分)
🧿 選題指導, 項目分享:
https://gitee.com/dancheng-senior/project-sharing-1/blob/master/%E6%AF%95%E8%AE%BE%E6%8C%87%E5%AF%BC/README.md
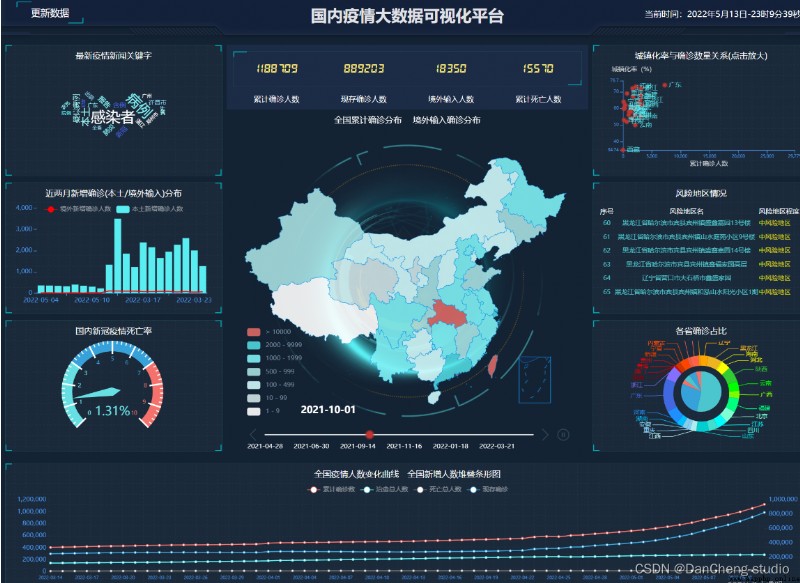
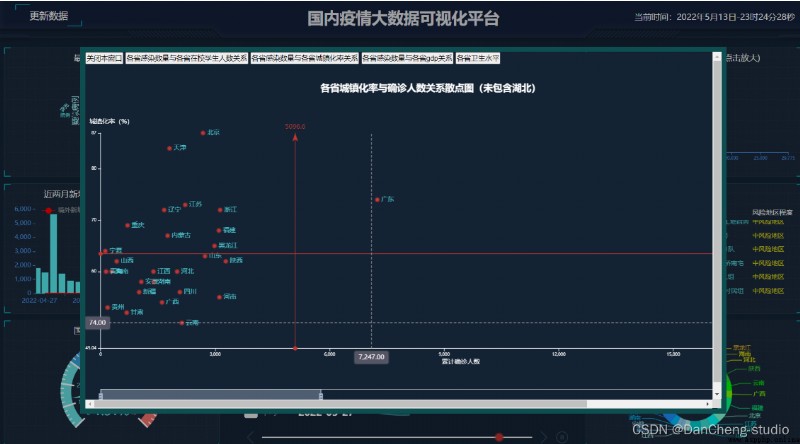
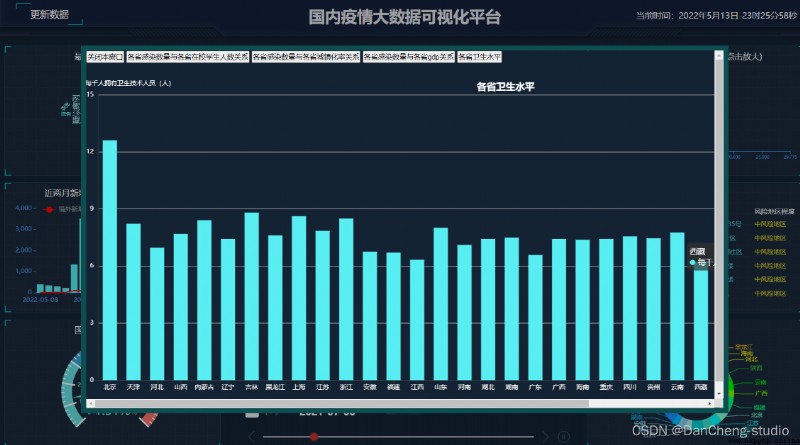
全球Covid-19大危機影響我們的生活,我們的出行、交流、教育、經濟等都發生了巨大的變化,全球疫情大數據可視化分析與展示,可用於社會各界接入疫情數據,感知疫情相關情況的實時交互式態勢,是重要的疫情分析、防控決策依據。
我國爆發的疫情,對我們的日常生活帶來了極大的影響,疫情嚴重期間,大家都談“疫”色變,大家對於了解疫情的情況具有巨大的需求;並且,目前來看我國仍然存在疫情二次爆發的可能,大家對於疫情的情況跟蹤也急於了解。
基於這個情況,學長對疫情的數據進行了爬取和可視化的展示和疫情的追蹤, 也就是學長設計的作品。

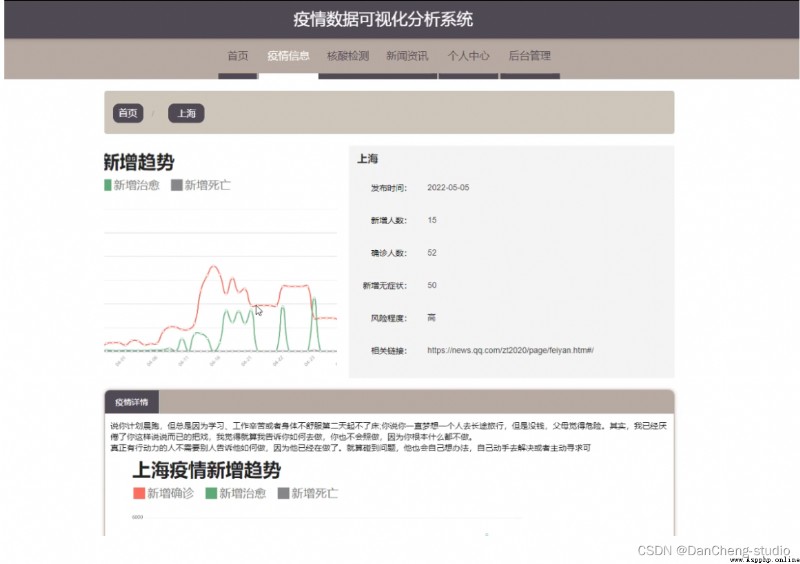
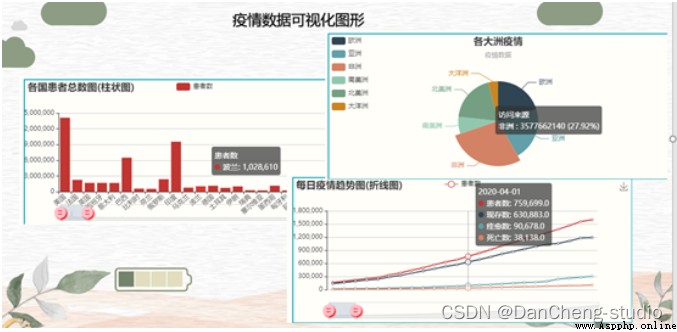
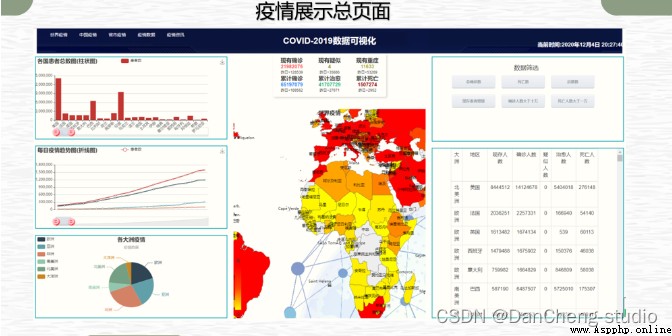
PS:篇幅有限,學長僅展示部分關鍵代碼
疫情數據爬蟲,就是給網站發起請求,並從響應中提取需要的數據
1、發起請求,獲取響應
2、解析內容
3、保存數據
import pymysql
import time
import json
import traceback #追蹤異常
import requests
def get_tencent_data():
""" :return: 返回歷史數據和當日詳細數據 """
url = ''
url_his=''
#最基本的反爬蟲
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
}
r = requests.get(url, headers) #使用requests請求
res = json.loads(r.text) # json字符串轉字典
data_all = json.loads(res['data'])
#再加上history的配套東西
r_his=requests.get(url_his,headers)
res_his=json.loads(r_his.text)
data_his=json.loads(res_his['data'])
history = {
} # 歷史數據
for i in data_his["chinaDayList"]:
ds = "2020." + i["date"]
tup = time.strptime(ds, "%Y.%m.%d")
ds = time.strftime("%Y-%m-%d", tup) # 改變時間格式,不然插入數據庫會報錯,數據庫是datetime類型
confirm = i["confirm"]
suspect = i["suspect"]
heal = i["heal"]
dead = i["dead"]
history[ds] = {
"confirm": confirm, "suspect": suspect, "heal": heal, "dead": dead}
for i in data_his["chinaDayAddList"]:
ds = "2020." + i["date"]
tup = time.strptime(ds, "%Y.%m.%d")
ds = time.strftime("%Y-%m-%d", tup)
confirm = i["confirm"]
suspect = i["suspect"]
heal = i["heal"]
dead = i["dead"]
history[ds].update({
"confirm_add": confirm, "suspect_add": suspect, "heal_add": heal, "dead_add": dead})
details = [] # 當日詳細數據
update_time = data_all["lastUpdateTime"]
data_country = data_all["areaTree"] # list 25個國家
data_province = data_country[0]["children"] # 中國各省
for pro_infos in data_province:
province = pro_infos["name"] # 省名
for city_infos in pro_infos["children"]:
city = city_infos["name"]
confirm = city_infos["total"]["confirm"]
confirm_add = city_infos["today"]["confirm"]
heal = city_infos["total"]["heal"]
dead = city_infos["total"]["dead"]
details.append([update_time, province, city, confirm, confirm_add, heal, dead])
return history, details
數據表結構
history表存儲每日的總數據
CREATE TABLE history (
ds datetime NOT NULL COMMENT ‘日期’,
confirm int(11) DEFAULT NULL COMMENT ‘累計確診’,
confirm_add int(11) DEFAULT NULL COMMENT ‘當日新增確診’,
suspect int(11) DEFAULT NULL COMMENT ‘剩余疑似’,
suspect_add int(11) DEFAULT NULL COMMENT ‘當日新增疑似’,
heal int(11) DEFAULT NULL COMMENT ‘累計治愈’,
heal_add int(11) DEFAULT NULL COMMENT ‘當日新增治愈’,
dead int(11) DEFAULT NULL COMMENT ‘累計死亡’,
dead_add int(11) DEFAULT NULL COMMENT ‘當日新增死亡’,
PRIMARY KEY (ds) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
details表存儲每日的詳細數據
CREATE TABLE details (
id int(11) NOT NULL AUTO_INCREMENT,
update_time datetime DEFAULT NULL COMMENT ‘數據最後更新時間’,
province varchar(50) DEFAULT NULL COMMENT ‘省’,
city varchar(50) DEFAULT NULL COMMENT ‘市’,
confirm int(11) DEFAULT NULL COMMENT ‘累計確診’,
confirm_add int(11) DEFAULT NULL COMMENT ‘新增確診’,
heal int(11) DEFAULT NULL COMMENT ‘累計治愈’,
dead int(11) DEFAULT NULL COMMENT ‘累計死亡’,
PRIMARY KEY (id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
整體的數據庫圖表:
echarts繪制圖表
def get_c1_data():
""" :return: 返回大屏div id=c1 的數據 """
# 因為會更新多次數據,取時間戳最新的那組數據
sql = "select sum(confirm)," \
"(select suspect from history order by ds desc limit 1)," \
"sum(heal)," \
"sum(dead) " \
"from details " \
"where update_time=(select update_time from details order by update_time desc limit 1) "
res = query(sql)
res_list = [str(i) for i in res[0]]
res_tuple=tuple(res_list)
return res_tuple
中國疫情地圖實現
def get_c2_data():
""" :return: 返回各省數據 """
# 因為會更新多次數據,取時間戳最新的那組數據
sql = "select province,sum(confirm) from details " \
"where update_time=(select update_time from details " \
"order by update_time desc limit 1) " \
"group by province"
res = query(sql)
return res
全國累計趨勢
def get_l1_data():
""" :return:返回每天歷史累計數據 """
sql = "select ds,confirm,suspect,heal,dead from history"
res = query(sql)
return res
def get_l2_data():
""" :return:返回每天新增確診和疑似數據 """
sql = "select ds,confirm_add,suspect_add from history"
res = query(sql)
return res
def get_r1_data():
""" :return: 返回非湖北地區城市確診人數前5名 """
sql = 'SELECT city,confirm FROM ' \
'(select city,confirm from details ' \
'where update_time=(select update_time from details order by update_time desc limit 1) ' \
'and province not in ("湖北","北京","上海","天津","重慶") ' \
'union all ' \
'select province as city,sum(confirm) as confirm from details ' \
'where update_time=(select update_time from details order by update_time desc limit 1) ' \
'and province in ("北京","上海","天津","重慶") group by province) as a ' \
'ORDER BY confirm DESC LIMIT 5'
res = query(sql)
return res
疫情熱搜
def get_r2_data():
""" :return: 返回最近的20條熱搜 """
sql = 'select content from hotsearch order by id desc limit 20'
res = query(sql) # 格式 (('民警抗疫一線奮戰16天犧牲1037364',), ('四川再派兩批醫療隊1537382',)
return res
🧿 選題指導, 項目分享:
https://gitee.com/dancheng-senior/project-sharing-1/blob/master/%E6%AF%95%E8%AE%BE%E6%8C%87%E5%AF%BC/README.md