爬蟲常用與畢業設計的數據收集階段, 多同學要求和反應, 讓學長出一片講解爬蟲的文章.
本文將描述和解析爬蟲怎麼使用, 並且給出實例.
所謂爬蟲就是編寫代碼從網頁上爬取自己想要的數據,代碼的質量決定了你能否精確的爬取想要得到的數據,得到數據後能否直觀正確的分析。
Python無疑是所有語言中最適合爬蟲的。Python本身很簡單,可是真正用好它需要學習大量的第三方庫插件。比如matplotlib庫,是一個仿照matalab的強大的繪圖庫,用它可以將爬下來的數據畫出餅圖、折線圖、散點圖等等,甚至是3D圖來直觀的展示。
Python第三方庫的安裝可以手動安裝,但是更為簡便的是在命令行直接輸入一行代碼即可自動搜索資源並安裝。而且非常智能,可以識別自己電腦的類型找到最合適的版本。
Pip install +你所需要的第三方庫
或者是easy install +你所需要的第三方庫
這裡建議大家使用pip安裝,因為pip可以安裝也可以卸載,而另一種方法只能安裝。如果遇到你想使用新的版本的第三方庫,使用pip的優勢就會顯現出來。
🧿 選題指導, 項目分享:
https://gitee.com/dancheng-senior/project-sharing-1/blob/master/%E6%AF%95%E8%AE%BE%E6%8C%87%E5%AF%BC/README.md
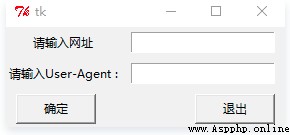
def web():
root = Tk()
Label(root,text='請輸入網址').grid(row=0,column=0) #對Label內容進行表格式布局
Label(root,text='請輸入User-Agent :').grid(row=1,column=0)
v1=StringVar() #設置變量
v2=StringVar()
e1 = Entry(root,textvariable=v1) #用於儲存 輸入的內容
e2 = Entry(root,textvariable=v2)
e1.grid(row=0,column=1,padx=10,pady=5) #進行表格式布局
e2.grid (row=1,column=1,padx=10,pady=5)
url = e1.get() #將從輸入框中得到的網址賦值給url
head = e2.get()
使用爬蟲爬取隨便一個博客,並對其所有的文章進行結巴分詞。從而提取關鍵詞,分析這位博主使用當下比較熱的與互聯網相關的詞匯的頻率。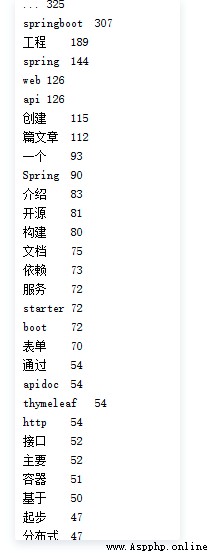
先編寫一個函數download()獲取url,接著編寫一個函數parse_descrtion()解析從
url中獲取的html,最後結巴分詞。
def download(url): #通過給定的url爬出數據
if url is None:
return None
try:
response = requests.get(url, headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36', })
if (response.status_code == 200):
return response.content
return None
except:
return None
def parse_descrtion(html):
if html is None:
return None
soup = BeautifulSoup(html, "html.parser") #html字符串創建BeautifulSoup
links = soup.find_all('a', href=re.compile(r'/forezp/article/details'))
for link in links:
titles.add(link.get_text())
def jiebaSet():
strs=''
if titles.__len__()==0:
return
for item in titles:
strs=strs+item;
tags = jieba.analyse.extract_tags(strs, topK=100, withWeight=True)
for item in tags:
print(item[0] + '\t' + str(int(item[1] * 1000)))
第一個函數沒什麼好說的。
第二個函數用到了beautifulsoup,通過對網頁的分析,從而尋找所有的滿足條件為
href=re.compile(r’/forezp/article/details’)的a標簽裡的內容。
第三個函數就是結巴分詞。接下來對結巴分詞作簡單的介紹。
支持三種分詞模式。
精確模式:試圖將句子最精確地切開,適合文本分析。
全模式:把句子中所有的可以成詞的詞語都掃描出來,速度非常快,但是不能解決歧義。
搜索引擎模式:在精確模式的基礎上,對長詞再次切分,提高召回率,適合用於搜索引擎分詞。
舉個例子,結巴分詞“我來到北京清華大學”這句話。
【全模式】:我/來到/北京/清華/清華大學/華大/大學
【精確模式】:我/來到/北京/清華大學
我這裡使用mongoDB數據庫, 同學們可以選取自己熟悉或符合要求的數據庫
client = pymongo.MongoClient(“localhost”, 27017)
這句是使用給定主機位置和端口。pymongo的Connection()方法不建議使用,官方推薦新方法MongoClient()。
db = client[‘local’]
這句是將創建好mongoDB後默認存在的兩個數據庫中的其中一個“local”賦給db,這樣
db在以後的程序裡就代表數據庫local。
posts = db.pymongo_test
post_id = posts.insert(data)
將local裡默認的一個集合“pymongo_test”賦值給posts,並且用insert方法單個插入數據。最後回到結巴分詞裡的一個循環程序裡,將數據依次插入。
以上是有關連接數據庫的核心代碼,接下來介紹如何啟動mongoDB數據庫。(我一開始編程怎麼都連接不上,後來發現是數據庫自身沒有啟動,唉,編程裡發生的傻逼事情實在是太多了。)
微軟徽標+R,輸入cmd,找“mongodb”的路徑,然後運行mongod開啟命令,同時用–dbpath指定數據存放地點為“db”文件夾。
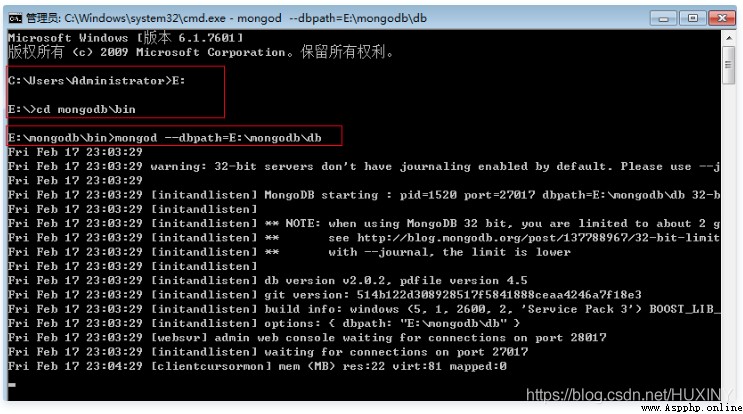
啟動mongoDB
我這裡是放在了E盤,大家根據需要自己設置。最後要看下是否開啟成功,從圖中的信息中獲知,mongodb采用27017端口,那麼我們就在浏覽器輸http://localhost:27017,打開後mongodb告訴我們在27017上Add 1000可以用http模式查看mongodb的管理信息。
🧿 選題指導, 項目分享:
https://gitee.com/dancheng-senior/project-sharing-1/blob/master/%E6%AF%95%E8%AE%BE%E6%8C%87%E5%AF%BC/README.md