author | Dongge takes off
source | Python Data Science
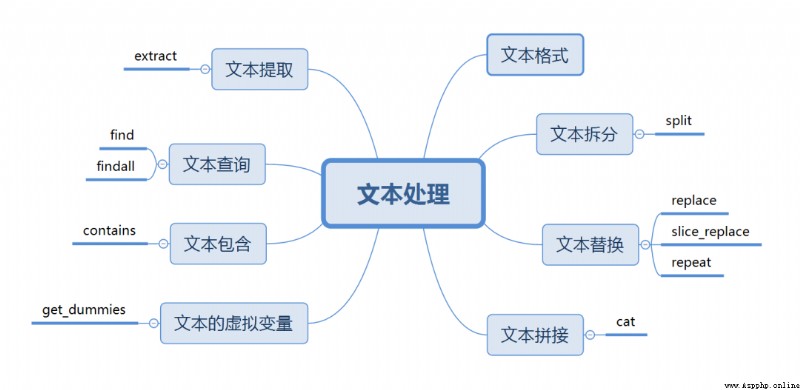
This time, let's introduce the common methods of text processing .
The two main types of text are string and object. Unless otherwise specified, the type is string, The text type is generally object.
The operation of text is mainly through accessor str To achieve , Very powerful , However, the following points should be paid attention to before use .
Accessors can only access Series Data structure use . In addition to regular column variables df.col outside , You can also change the index type df.Index and df.columns Use
Ensure that the object type accessed is a string str type . If not, first astype(str) Conversion type , Otherwise, an error will be reported
Accessors can be used with multiple connections . Such as df.col.str.lower().str.upper(), This and Dataframe One line operation in is a principle
The following formally introduces the various operations of the text , It can basically cover daily 95% Data cleaning needs , altogether 8 A scenario .
The following operations are based on the following data :
import pandas as pd
import numpy as np
df = pd.DataFrame({'name':['jordon', 'MIKE', 'Kelvin', 'xiaoLi', 'qiqi','Amei'],
'Age':[18, 30, 45, 23, 45, 62],
'level':['high','Low','M','L','middle',np.nan],
'Email':['[email protected]','[email protected]','[email protected]','[email protected]',np.nan,'[email protected]']})
--------------------------------------------
name Age level Email
0 jordon 18 high [email protected]
1 MIKE 30 Low [email protected]
2 Kelvin 45 M [email protected]
3 xiaoLi 23 L [email protected]
4 qiqi 45 middle NaN
5 Amei 62 NaN [email protected]Case change
# All characters become lowercase
s.str.lower()
# Characters are all uppercase
s.str.upper()
# Capitalize the first letter of each word
s.str.title()
# The first letter of the string is capitalized
s.str.capitalize()
# Upper and lower case conversion
s.str.swapcase() The above usage is relatively simple , Don't give examples one by one , Here's an example of columns Examples of lowercase .
df.columns.str.lower()
--------------------------------------------------------
Index(['name', 'age', 'level', 'email'], dtype='object')Format judgment
The following are judgment operations , Therefore, the Boolean value is returned .
s.str.isalpha # Is it a letter
s.str.isnumeric # Is it a number 0-9
s.str.isalnum # Whether it consists of letters and numbers
s.str.isupper # Whether it is capitalized
s.str.islower # Whether it is lowercase
s.str.isdigit # Is it a number alignment
# Align center , Width is 8, Others ’*’ fill
s.str.center(, fillchar='*')
# Align left , Width is 8, Others ’*’ fill
s.str.ljust(8, fillchar='*')
# Right alignment , Width is 8, Others ’*’ fill
s.str.rjust(8, fillchar='*')
# Custom alignment , Parameter adjustable width 、 Align the direction 、 Fill character
s.str.pad(width=8, side='both',fillchar='*')# give an example
df.name.str.center(8, fillchar='*')
-------------
0 *jordon*
1 **MIKE**
2 *Kelvin*
3 *xiaoLi*
4 **qiqi**
5 **Amei**Counting and coding
s.str.count('b') # A string that contains a specified number of letters
s.str.len() # String length
s.str.encode('utf-8') # Character encoding
s.str.decode('utf-8') # Character decoding By using split Method can split text by using a specified character as a split point . among ,expand Parameter allows the split content to expand , Form a separate column ,n Parameter can specify the split position to control the formation of several columns .
Next email The variable follows @ To break up .
# Usage method
s.str.split('x', expand=True, n=1)
# give an example
df.Email.str.split('@')
----------------------------
0 [jordon, sohu.com]
1 [Mike, 126.cn]
2 [KelvinChai, gmail.com]
3 [xiaoli, 163.com]
4 NaN
5 [amei, qq.com]# expand You can expand the split content into a single column
df.Email.str.split('@' ,expand=True)
----------------------------
0 1
0 jordon sohu.com
1 Mike 126.cn
2 KelvinChai gmail.com
3 xiaoli 163.com
4 NaN NaN
5 amei qq.com More complex splitting can be done with the help of regular expressions , For example, I want to pass @ and . To break up , Then it can be realized in this way .
df.Email.str.split('\@|\.',expand=True)
----------------------------
0 1 2
0 jordon sohu com
1 Mike 126 cn
2 KelvinChai gmail com
3 xiaoli 163 com
4 NaN NaN NaN
5 amei qq com There are several ways to replace text :replace,slice_replace,repeat
replace Replace
replace Method is the most commonly used alternative , The parameters are as follows :
pal: Is the replaced content string , It can also be a regular expression
repl: String for new content , It can also be a called function
regex: Used to set whether regular is supported , The default is True
# take email Species com Replace with cn
df.Email.str.replace('com','cn')
------------------------
0 [email protected]
1 [email protected]
2 [email protected]
3 [email protected]
4 NaN
5 [email protected]More complicated , For example, write old content as Regular expressions .
# take @ Replace the previous names with xxx
df.Email.str.replace('(.*?)@','[email protected]')
------------------
0 [email protected]
1 [email protected]
2 [email protected]
3 [email protected]
4 NaN
5 [email protected]Or write new content as Called function .
df.Email.str.replace('(.*?)@', lambda x:x.group().upper())
-------------------------
0 [email protected]
1 [email protected]
2 [email protected]
3 [email protected]
4 NaN
5 [email protected]Slice replacement
slice_replace The replacement is realized by slicing , The specified characters can be retained or deleted by slicing , The parameters are as follows .
start: The starting position
stop: End position
repl: New content to replace
Yes start After slice position and stop Replace before slice position , If not set stop, that start Then replace them all , Similarly, if it is not set start, that stop Replace all before .
df.Email.str.slice_replace(start=1,stop=2,repl='XX')
-------------------------
0 [email protected]
1 [email protected]
2 [email protected]
3 [email protected]
4 NaN
5 [email protected]Repeat replacement
repeat It can realize the function of repeated replacement , Parameters repeats Set the number of repetitions .
df.name.str.repeat(repeats=2)
-------------------------
0 jordonjordon
1 MIKEMIKE
2 KelvinKelvin
3 xiaoLixiaoLi
4 qiqiqiqi
5 AmeiAmei The text is spliced through cat Method realization , Parameters :
others: Sequences that need to be spliced , If None Not set up , It will automatically splice the current sequence into a string
sep: Separator for splicing
na_rep: Null values are not processed by default , The replacement character of null value is set here .
join: Direction of splicing , Include left, right, outer, inner, The default is left
There are mainly the following splicing methods .
1. Splice a single sequence into a complete string
As mentioned above , When there is no setting ohters When parameters are , This method combines the current sequence into a new string .
df.name.str.cat()
-------------------------------
'jordonMIKEKelvinxiaoLiqiqiAmei'
# Set up sep The separator is `-`
df.name.str.cat(sep='-')
-------------------------------
'jordon-MIKE-Kelvin-xiaoLi-qiqi-Amei'
# Assign the missing value to `*`
df.level.str.cat(sep='-',na_rep='*')
-----------------------
'high-Low-M-L-middle-*'2. Splicing sequence and other class list objects are new sequences
Let's start with name Column sum * Column splicing , then level Column splicing , Form a new sequence .
# str.cat Multi level connection realizes multi column splicing
df.name.str.cat(['*']*6).str.cat(df.level)
----------------
0 jordon*high
1 MIKE*Low
2 Kelvin*M
3 xiaoLi*L
4 qiqi*middle
5 NaN
# You can also directly splice multiple columns
df.name.str.cat([df.level,df.Email],na_rep='*')
--------------------------------
0 [email protected]
1 [email protected]
2 [email protected]
3 [email protected]
4 qiqimiddle*
5 Amei*[email protected]Splice a sequence with multiple objects into a new sequence
Text extraction is mainly through extract To achieve .
extract Parameters :
pat: Through regular expressions to achieve an extraction of pattern
flags: Regular library re Logo in , such as re.IGNORECASE
expand: When regular extracts only one content , If expand=True The exhibition will return to a DataFrame, Otherwise, return one Series
# extract email Two contents in
df.Email.str.extract(pat='(.*?)@(.*).com')
--------------------
0 1
0 jordon sohu
1 vMike NaN
2 KelvinChai gmail
3 xiaoli 163
4 NaN NaN
5 amei qq adopt find and findall Two ways to achieve .
find The parameters are simple , Directly enter the string to query , Returns the position in the original string , If no query result is found, return -1.
df['@position'] = df.Email.str.find('@')
df[['Email','@position']]
-------------------------------------
Email @position
0 [email protected] 6.0
1 [email protected] 4.0
2 [email protected] 10.0
3 [email protected] 6.0
4 NaN NaN
5 [email protected] 4.0 The above example returns @ stay email Position in variable .
Another way to find it is findall
findall Parameters :
pat: What to look for , regular expression
flag: Regular library re Logo in , such as re.IGNORECASE
findall and find The difference is that regular expressions are supported , And return the details . This method is a little similar to extract, It can also be used to extract , But not as good as extract convenient .
df.Email.str.findall('(.*?)@(.*).com')
--------------------------
0 [(jordon, sohu)]
1 []
2 [(KelvinChai, gmail)]
3 [(xiaoli, 163)]
4 NaN
5 [(amei, qq)]The above example returns two parts of a regular lookup , And appear in the form of tuple list .
The text contains through contains Method realization , Returns a Boolean value , In general, and loc The query function is used in conjunction with , Parameters :
pat: Match string , regular expression
case: Is it case sensitive ,True Express difference
flags: Regular library re Logo in , such as re.IGNORECASE
na: Fill in missing values
regex: Whether to support regular , Default True Support
df.Email.str.contains('jordon|com',na='*')
----------
0 True
1 False
2 True
3 True
4 *
5 True
#
df.loc[df.Email.str.contains('jordon|com', na=False)]
------------------------------------------
name Age level Email @position
0 jordon 18 high [email protected] 6.0
2 Kelvin 45 M [email protected] 10.0
3 xiaoLi 23 L [email protected] 6.0
5 Amei 62 NaN [email protected] 4.0 There's a little bit of caution here , If and loc In combination with , Note that there must be no missing values , Otherwise, an error will be reported . Can be set by na=False Ignore missing values and complete the query .
get_dummies A column variable can be automatically generated into a dummy variable ( Dummy variable ), This method is often used in feature derivation .
df.name.str.get_dummies()
-------------------------------
Amei Kelvin MIKE jordon qiqi xiaoLi
0 0 0 0 1 0 0
1 0 0 1 0 0 0
2 0 1 0 0 0 0
3 0 0 0 0 0 1
4 0 0 0 0 1 0
5 1 0 0 0 0 0That's what we're sharing .

Looking back
It's too voluminous !AI High accuracy of math exam 81%
This Python Artifact can let you touch fish for a long time !
2D Transformation 3D, Look at NVIDIA's AI“ new ” magic !
How to use Python Realize the security system of the scenic spot ?
Share
Point collection
A little bit of praise
Click to see