目錄
思路
過程
代碼實現
代碼一(有點錯誤)
結果
代碼二
結果
在百度翻譯上,進行翻譯,點開檢查F12,可以在網絡那邊看到數據傳輸情況,看到後台的翻譯網址,我們可以偽裝前台的百度翻譯網站,發送一樣的數據給翻譯後台,然後獲取後台傳輸回來的翻譯信息。百度翻譯這邊需要偽裝下發送信息,偽裝自己是個浏覽器。不過有道翻譯就不需要偽裝是浏覽器了。
先小翻譯

找到POST
右側有相應翻譯的POST
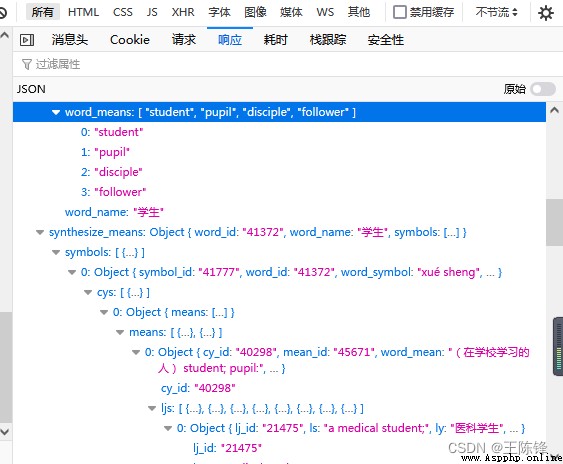
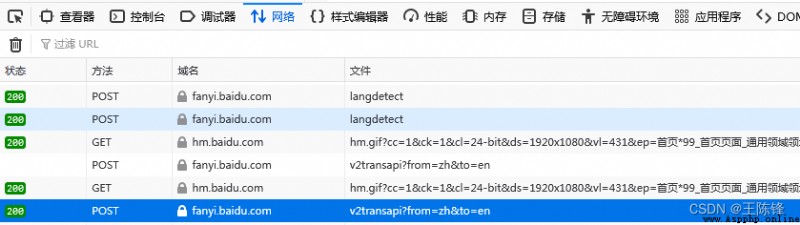
獲取後台翻譯網址
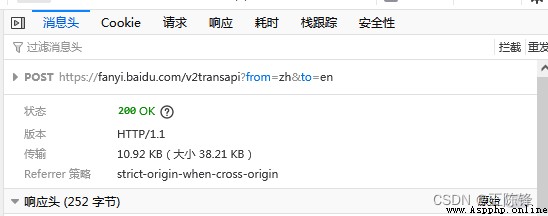
獲取請求字段
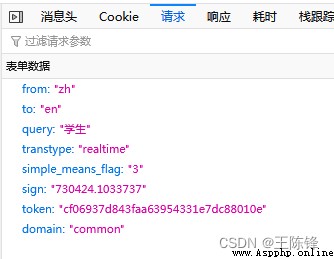
from urllib import request,parse
import json
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/68.0.3440.75 Safari/537.36'}
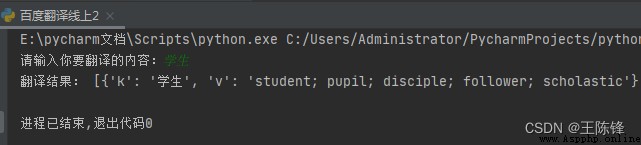
content=input('請輸入你要翻譯的內容:')
dict={'kw':content}#需要翻譯的內容
new_name=parse.urlencode(dict)#進行轉碼
url='https://fanyi.baidu.com/sug'#url 連接
response=request.Request(url,headers=headers,data=bytes(new_name,encoding='utf-8'))#進行封裝
text=request.urlopen(response).read().decode('utf-8')#爬取數據
content=json.loads(text)
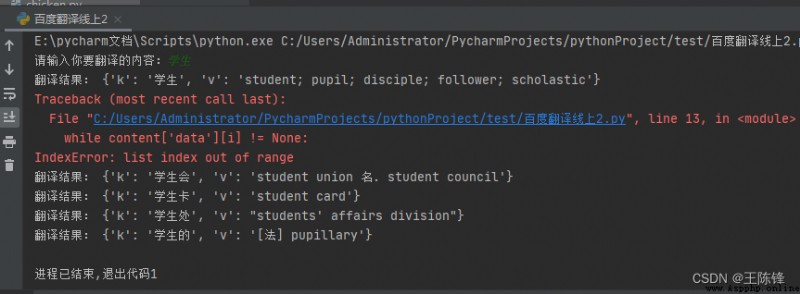
print('翻譯結果:',content['data'][0])在實現的時候,會發生超出邊界的問題。
from urllib import request,parse
import json
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/68.0.3440.75 Safari/537.36'}
content=input('請輸入你要翻譯的內容:')
dict={'kw':content}#需要翻譯的內容
new_name=parse.urlencode(dict)#進行轉碼
url='https://fanyi.baidu.com/sug'#url 連接
response=request.Request(url,headers=headers,data=bytes(new_name,encoding='utf-8'))#進行封裝
text=request.urlopen(response).read().decode('utf-8')#爬取數據
content=json.loads(text)
print('翻譯結果:',content['data'][:-1])
為了解決代碼一的超出邊界問題,我采取了直接用-1做索引,限定了最後的邊界。